 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Meta-Learning with Gaussian Processes
Dec 01, 2023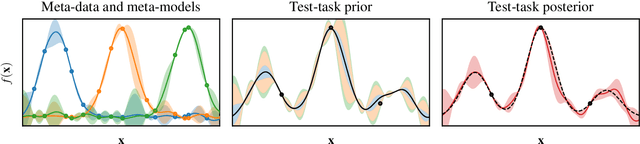
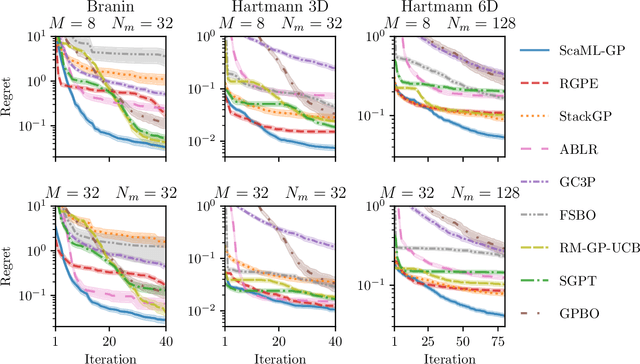
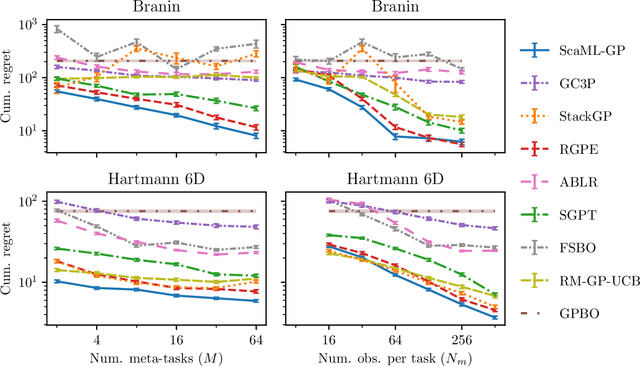
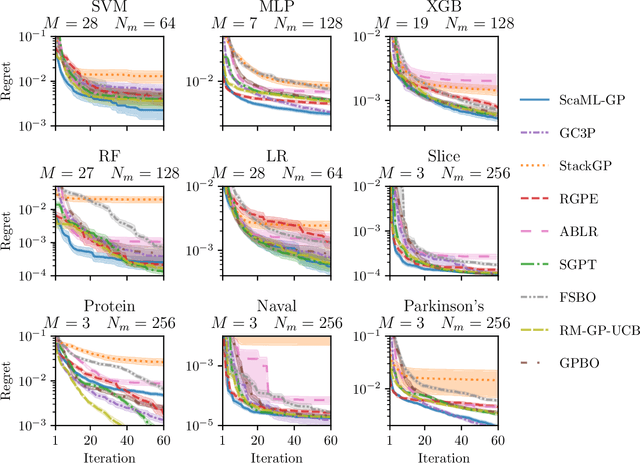
Meta-learning is a powerful approach that exploits historical data to quickly solve new tasks from the same distribution. In the low-data regime, methods based on the closed-form posterior of Gaussian processes (GP) together with Bayesian optimization have achieved high performance. However, these methods are either computationally expensive or introduce assumptions that hinder a principled propagation of uncertainty between task models. This may disrupt the balance between exploration and exploitation during optimization. In this paper, we develop ScaML-GP, a modular GP model for meta-learning that is scalable in the number of tasks. Our core contribution is a carefully designed multi-task kernel that enables hierarchical training and task scalability. Conditioning ScaML-GP on the meta-data exposes its modular nature yielding a test-task prior that combines the posteriors of meta-task GPs. In synthetic and real-world meta-learning experiments, we demonstrate that ScaML-GP can learn efficiently both with few and many meta-tasks.
MALIBO: Meta-learning for Likelihood-free Bayesian Optimization
Jul 07, 2023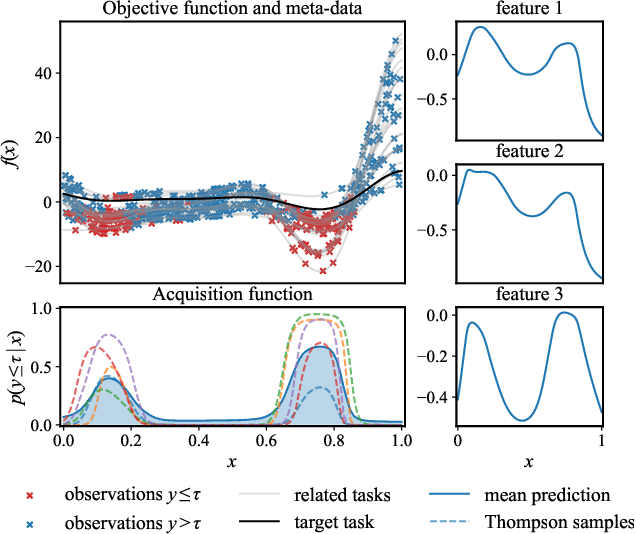



Bayesian optimization (BO) is a popular method to optimize costly black-box functions. While traditional BO optimizes each new target task from scratch, meta-learning has emerged as a way to leverage knowledge from related tasks to optimize new tasks faster. However, existing meta-learning BO methods rely on surrogate models that suffer from scalability issues and are sensitive to observations with different scales and noise types across tasks. Moreover, they often overlook the uncertainty associated with task similarity. This leads to unreliable task adaptation when only limited observations are obtained or when the new tasks differ significantly from the related tasks. To address these limitations, we propose a novel meta-learning BO approach that bypasses the surrogate model and directly learns the utility of queries across tasks. Our method explicitly models task uncertainty and includes an auxiliary model to enable robust adaptation to new tasks. Extensive experiments show that our method demonstrates strong anytime performance and outperforms state-of-the-art meta-learning BO methods in various benchmarks.
Auto-Sklearn 2.0: The Next Generation
Jul 08, 2020
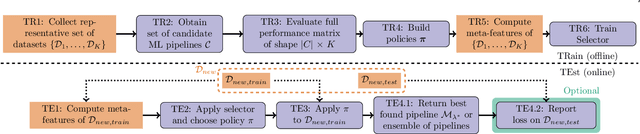
Automated Machine Learning, which supports practitioners and researchers with the tedious task of manually designing machine learning pipelines, has recently achieved substantial success. In this paper we introduce new Automated Machine Learning (AutoML) techniques motivated by our winning submission to the second ChaLearn AutoML challenge, PoSH Auto-sklearn. For this, we extend Auto-sklearn with a new, simpler meta-learning technique, improve its way of handling iterative algorithms and enhance it with a successful bandit strategy for budget allocation. Furthermore, we go one step further and study the design space of AutoML itself and propose a solution towards truly hand-free AutoML. Together, these changes give rise to the next generation of our AutoML system, Auto-sklearn (2.0). We verify the improvement by these additions in a large experimental study on 39 AutoML benchmark datasets and conclude the paper by comparing to Auto-sklearn (1.0), reducing the regret by up to a factor of five.
Probabilistic Rollouts for Learning Curve Extrapolation Across Hyperparameter Settings
Oct 10, 2019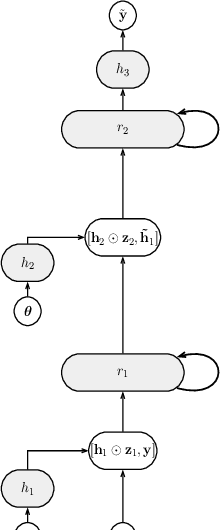


We propose probabilistic models that can extrapolate learning curves of iterative machine learning algorithms, such as stochastic gradient descent for training deep networks, based on training data with variable-length learning curves. We study instantiations of this framework based on random forests and Bayesian recurrent neural networks. Our experiments show that these models yield better predictions than state-of-the-art models from the hyperparameter optimization literature when extrapolating the performance of neural networks trained with different hyperparameter settings.
Learning to Design RNA
Dec 31, 2018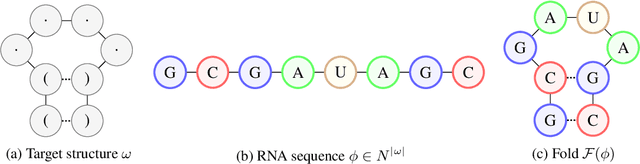
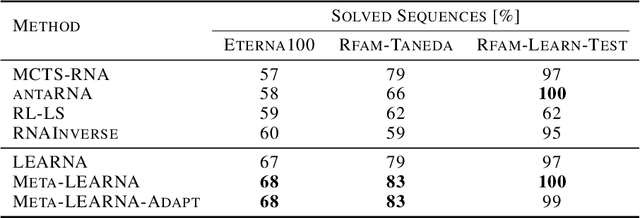
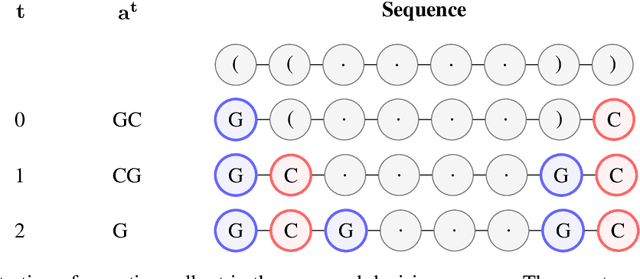
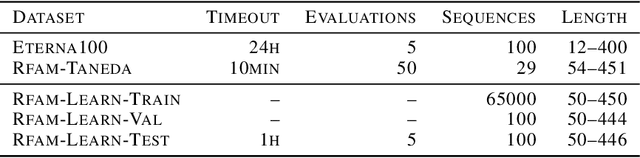
Designing RNA molecules has garnered recent interest in medicine, synthetic biology, biotechnology and bioinformatics since many functional RNA molecules were shown to be involved in regulatory processes for transcription, epigenetics and translation. Since an RNA's function depends on its structural properties, the RNA Design problem is to find an RNA sequence that folds into a specified secondary structure. Here, we propose a new algorithm for the RNA Design problem, dubbed LEARNA. LEARNA uses deep reinforcement learning to train a policy network to sequentially design an entire RNA sequence given a specified secondary target structure. By meta-learning across 8000 different RNA target structures for one hour on 20 cores, our extension Meta-LEARNA constructs an RNA Design policy that can be applied out of the box to solve novel RNA target structures. Methodologically, for what we believe to be the first time, we jointly optimize over a rich space of neural architectures for the policy network, the hyperparameters of the training procedure and the formulation of the decision process. Comprehensive empirical results on two widely-used RNA secondary structure design benchmarks, as well as a third one that we introduce, show that our approach achieves new state-of-the-art performance on all benchmarks while also being orders of magnitudes faster in reaching the previous state-of-the-art performance. In an ablation study, we analyze the importance of our method's different components.
Towards Automated Deep Learning: Efficient Joint Neural Architecture and Hyperparameter Search
Jul 18, 2018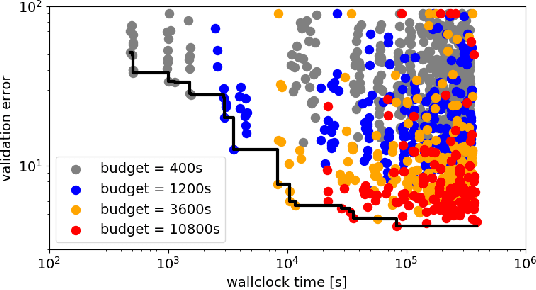

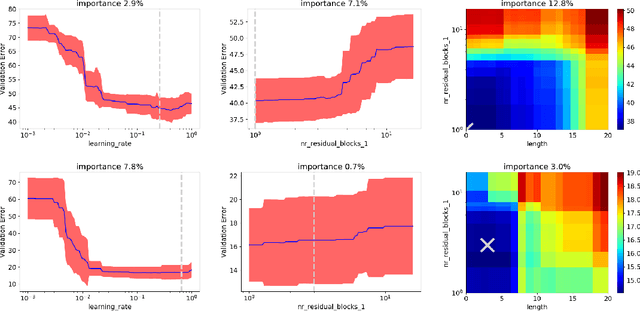
While existing work on neural architecture search (NAS) tunes hyperparameters in a separate post-processing step, we demonstrate that architectural choices and other hyperparameter settings interact in a way that can render this separation suboptimal. Likewise, we demonstrate that the common practice of using very few epochs during the main NAS and much larger numbers of epochs during a post-processing step is inefficient due to little correlation in the relative rankings for these two training regimes. To combat both of these problems, we propose to use a recent combination of Bayesian optimization and Hyperband for efficient joint neural architecture and hyperparameter search.
* 11 pages, 3 figures, 3 tables, ICML 2018 AutoML Workshop
BOHB: Robust and Efficient Hyperparameter Optimization at Scale
Jul 04, 2018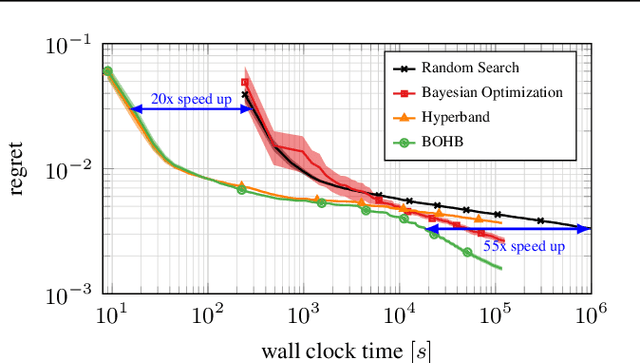
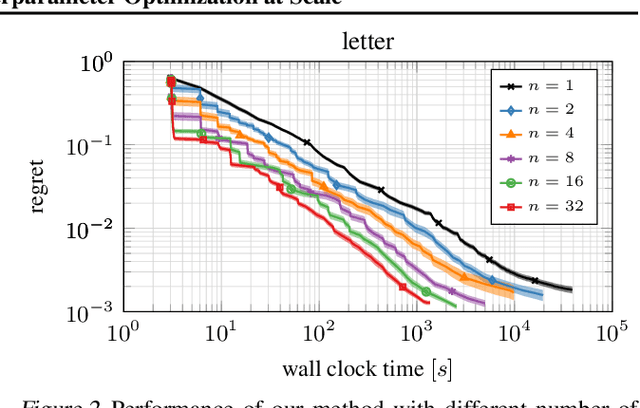
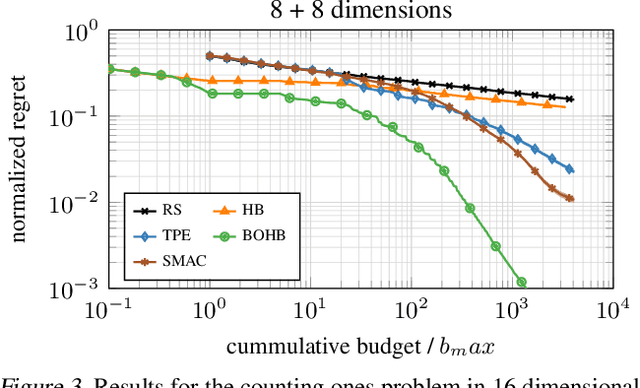
Modern deep learning methods are very sensitive to many hyperparameters, and, due to the long training times of state-of-the-art models, vanilla Bayesian hyperparameter optimization is typically computationally infeasible. On the other hand, bandit-based configuration evaluation approaches based on random search lack guidance and do not converge to the best configurations as quickly. Here, we propose to combine the benefits of both Bayesian optimization and bandit-based methods, in order to achieve the best of both worlds: strong anytime performance and fast convergence to optimal configurations. We propose a new practical state-of-the-art hyperparameter optimization method, which consistently outperforms both Bayesian optimization and Hyperband on a wide range of problem types, including high-dimensional toy functions, support vector machines, feed-forward neural networks, Bayesian neural networks, deep reinforcement learning, and convolutional neural networks. Our method is robust and versatile, while at the same time being conceptually simple and easy to implement.
Fast Bayesian Optimization of Machine Learning Hyperparameters on Large Datasets
Mar 07, 2017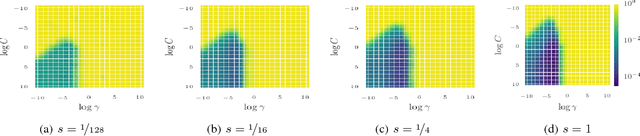
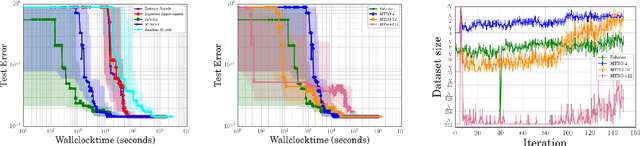
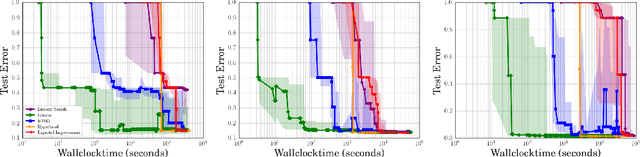
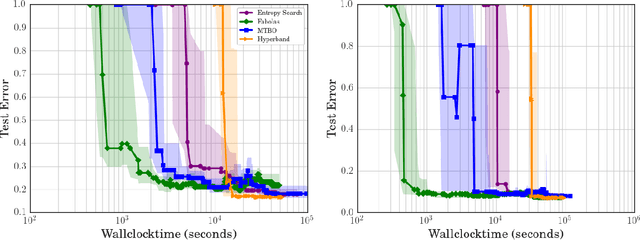
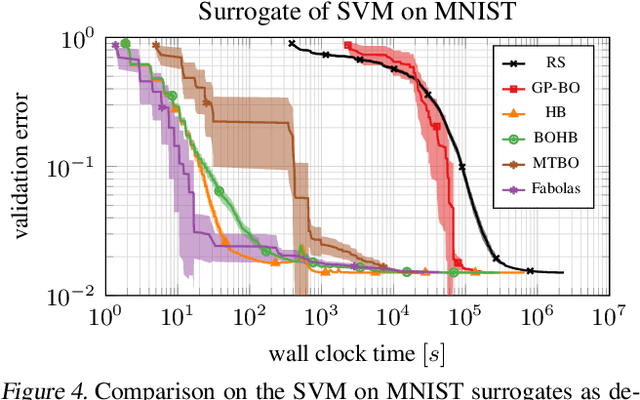
Bayesian optimization has become a successful tool for hyperparameter optimization of machine learning algorithms, such as support vector machines or deep neural networks. Despite its success, for large datasets, training and validating a single configuration often takes hours, days, or even weeks, which limits the achievable performance. To accelerate hyperparameter optimization, we propose a generative model for the validation error as a function of training set size, which is learned during the optimization process and allows exploration of preliminary configurations on small subsets, by extrapolating to the full dataset. We construct a Bayesian optimization procedure, dubbed Fabolas, which models loss and training time as a function of dataset size and automatically trades off high information gain about the global optimum against computational cost. Experiments optimizing support vector machines and deep neural networks show that Fabolas often finds high-quality solutions 10 to 100 times faster than other state-of-the-art Bayesian optimization methods or the recently proposed bandit strategy Hyperband.
Asynchronous Stochastic Gradient MCMC with Elastic Coupling
Dec 08, 2016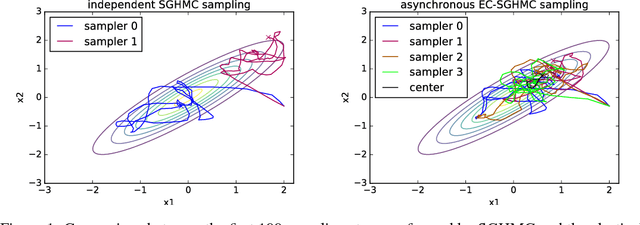
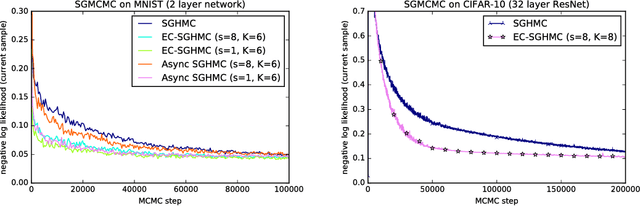
We consider parallel asynchronous Markov Chain Monte Carlo (MCMC) sampling for problems where we can leverage (stochastic) gradients to define continuous dynamics which explore the target distribution. We outline a solution strategy for this setting based on stochastic gradient Hamiltonian Monte Carlo sampling (SGHMC) which we alter to include an elastic coupling term that ties together multiple MCMC instances. The proposed strategy turns inherently sequential HMC algorithms into asynchronous parallel versions. First experiments empirically show that the resulting parallel sampler significantly speeds up exploration of the target distribution, when compared to standard SGHMC, and is less prone to the harmful effects of stale gradients than a naive parallelization approach.