 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Bayesian Optimization of Machine Learning Hyperparameters on Large Datasets
Paper and Code
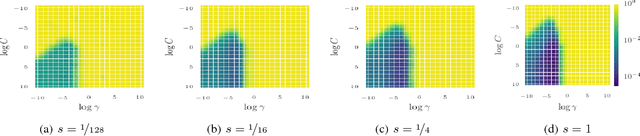
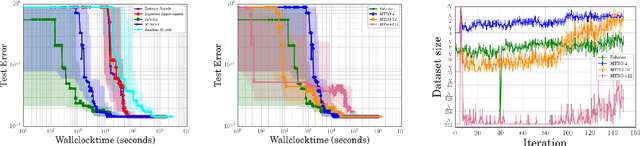
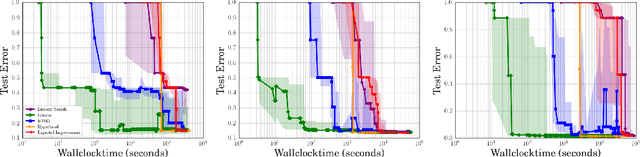
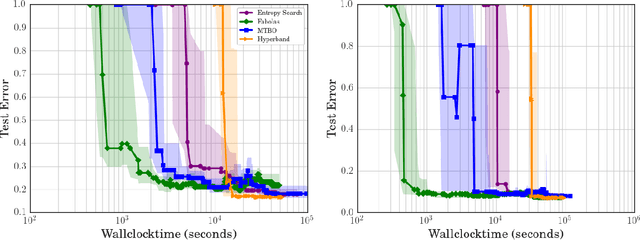
Bayesian optimization has become a successful tool for hyperparameter optimization of machine learning algorithms, such as support vector machines or deep neural networks. Despite its success, for large datasets, training and validating a single configuration often takes hours, days, or even weeks, which limits the achievable performance. To accelerate hyperparameter optimization, we propose a generative model for the validation error as a function of training set size, which is learned during the optimization process and allows exploration of preliminary configurations on small subsets, by extrapolating to the full dataset. We construct a Bayesian optimization procedure, dubbed Fabolas, which models loss and training time as a function of dataset size and automatically trades off high information gain about the global optimum against computational cost. Experiments optimizing support vector machines and deep neural networks show that Fabolas often finds high-quality solutions 10 to 100 times faster than other state-of-the-art Bayesian optimization methods or the recently proposed bandit strategy Hyperband.