 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Meta-Learning with Gaussian Processes
Dec 01, 2023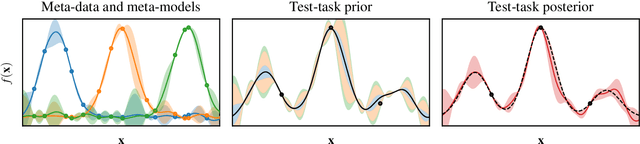
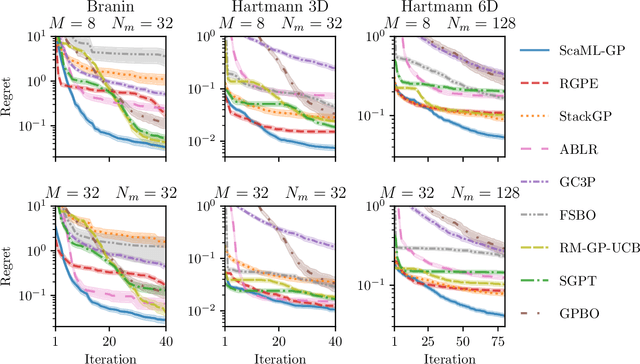
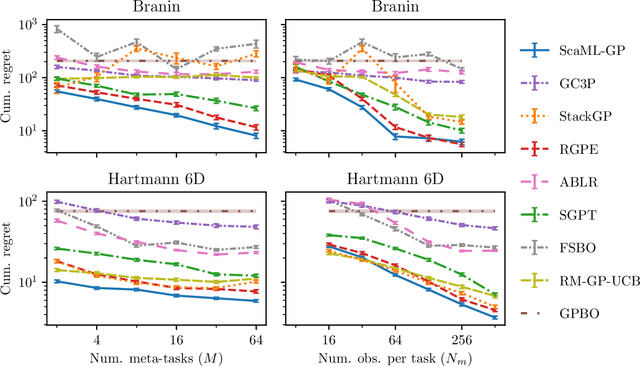
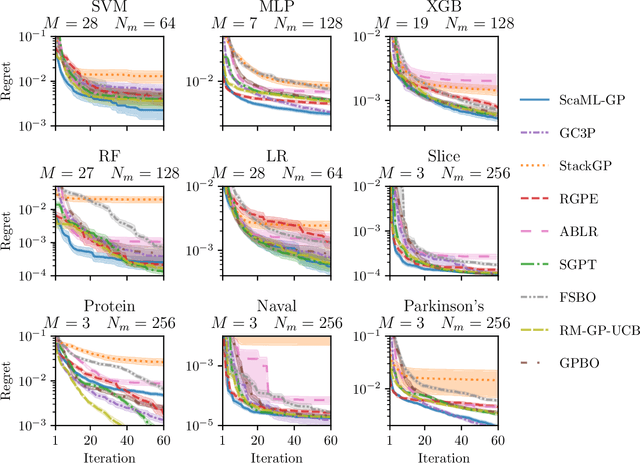
Meta-learning is a powerful approach that exploits historical data to quickly solve new tasks from the same distribution. In the low-data regime, methods based on the closed-form posterior of Gaussian processes (GP) together with Bayesian optimization have achieved high performance. However, these methods are either computationally expensive or introduce assumptions that hinder a principled propagation of uncertainty between task models. This may disrupt the balance between exploration and exploitation during optimization. In this paper, we develop ScaML-GP, a modular GP model for meta-learning that is scalable in the number of tasks. Our core contribution is a carefully designed multi-task kernel that enables hierarchical training and task scalability. Conditioning ScaML-GP on the meta-data exposes its modular nature yielding a test-task prior that combines the posteriors of meta-task GPs. In synthetic and real-world meta-learning experiments, we demonstrate that ScaML-GP can learn efficiently both with few and many meta-tasks.
Transfer Learning with Gaussian Processes for Bayesian Optimization
Nov 22, 2021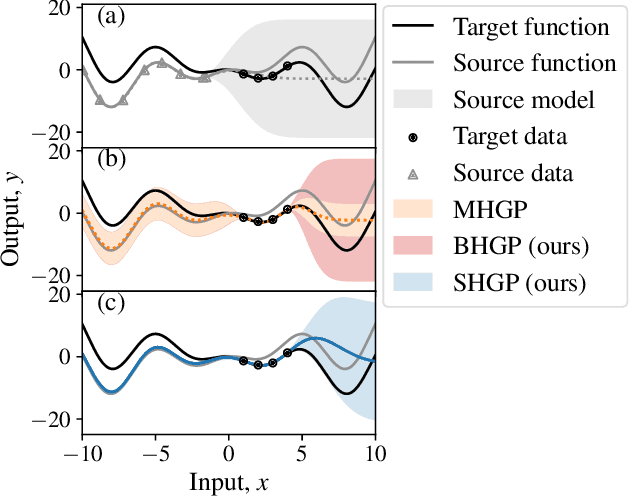

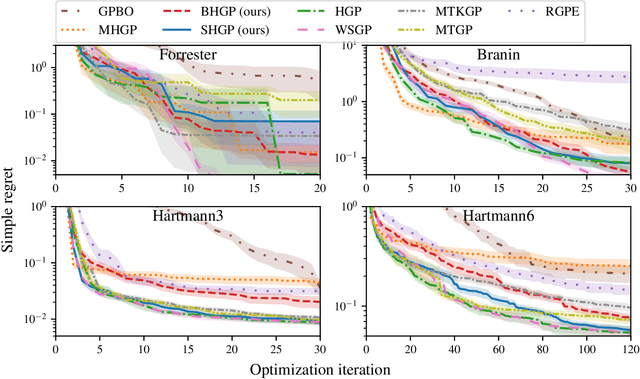
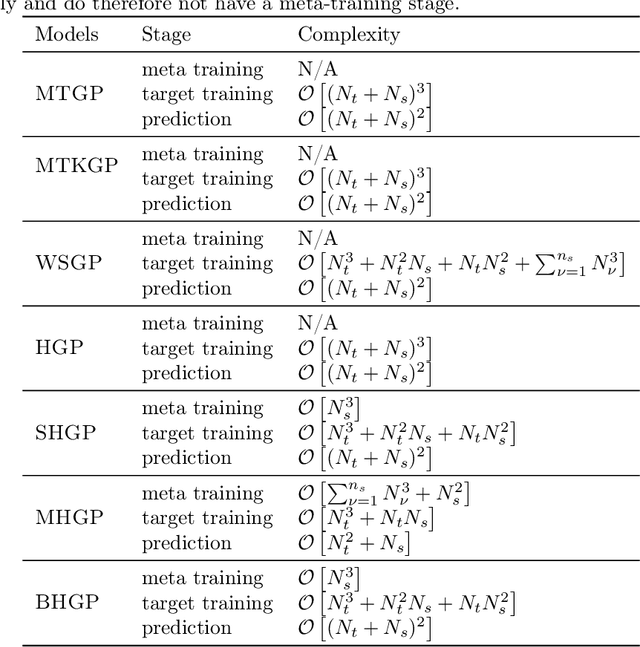
Bayesian optimization is a powerful paradigm to optimize black-box functions based on scarce and noisy data. Its data efficiency can be further improved by transfer learning from related tasks. While recent transfer models meta-learn a prior based on large amount of data, in the low-data regime methods that exploit the closed-form posterior of Gaussian processes (GPs) have an advantage. In this setting, several analytically tractable transfer-model posteriors have been proposed, but the relative advantages of these methods are not well understood. In this paper, we provide a unified view on hierarchical GP models for transfer learning, which allows us to analyze the relationship between methods. As part of the analysis, we develop a novel closed-form boosted GP transfer model that fits between existing approaches in terms of complexity. We evaluate the performance of the different approaches in large-scale experiments and highlight strengths and weaknesses of the different transfer-learning methods.
Multi-Class Multi-Instance Count Conditioned Adversarial Image Generation
Mar 31, 2021
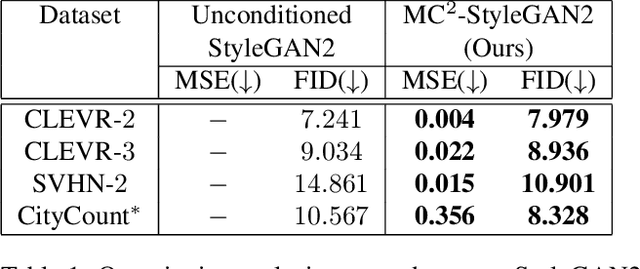
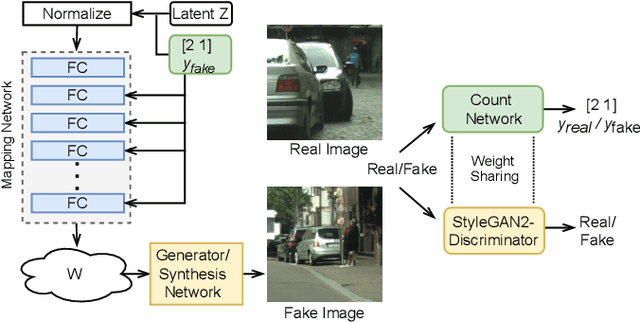
Image generation has rapidly evolved in recent years. Modern architectures for adversarial training allow to generate even high resolution images with remarkable quality. At the same time, more and more effort is dedicated towards controlling the content of generated images. In this paper, we take one further step in this direction and propose a conditional generative adversarial network (GAN) that generates images with a defined number of objects from given classes. This entails two fundamental abilities (1) being able to generate high-quality images given a complex constraint and (2) being able to count object instances per class in a given image. Our proposed model modularly extends the successful StyleGAN2 architecture with a count-based conditioning as well as with a regression sub-network to count the number of generated objects per class during training. In experiments on three different datasets, we show that the proposed model learns to generate images according to the given multiple-class count condition even in the presence of complex backgrounds. In particular, we propose a new dataset, CityCount, which is derived from the Cityscapes street scenes dataset, to evaluate our approach in a challenging and practically relevant scenario.