 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modality Embedding of Force and Language for Natural Human-Robot Communication
Feb 04, 2025



A method for cross-modality embedding of force profile and words is presented for synergistic coordination of verbal and haptic communication. When two people carry a large, heavy object together, they coordinate through verbal communication about the intended movements and physical forces applied to the object. This natural integration of verbal and physical cues enables effective coordination. Similarly, human-robot interaction could achieve this level of coordination by integrating verbal and haptic communication modalities. This paper presents a framework for embedding words and force profiles in a unified manner, so that the two communication modalities can be integrated and coordinated in a way that is effective and synergistic. Here, it will be shown that, although language and physical force profiles are deemed completely different, the two can be embedded in a unified latent space and proximity between the two can be quantified. In this latent space, a force profile and words can a) supplement each other, b) integrate the individual effects, and c) substitute in an exchangeable manner. First, the need for cross-modality embedding is addressed, and the basic architecture and key building block technologies are presented. Methods for data collection and implementation challenges will be addressed, followed by experimental results and discussions.
Language Control in Robotics
May 04, 2023



For robots performing a assistive tasks for the humans, it is crucial to synchronize their speech with their motions, in order to achieve natural and effective human-robot interaction. When a robot's speech is out of sync with their motions, it can cause confusion, frustration, and misinterpretation of the robot's intended meaning. Humans are accustomed to using both verbal and nonverbal cues to understand and coordinate with each other, and robots that can align their speech with their actions can tap into this natural mode of communication. In this research, we propose a language controller for robots to control the pace, tone, and pauses of their speech along with it's motion in the trajectory. The robot's speed is adjusted using an admittance controller based on the force input from the user, and the robot's speech speed is modulated using phase-vocoders.
An Avatar Robot Overlaid with the 3D Human Model of a Remote Operator
Mar 05, 2023



Although telepresence assistive robots have made significant progress, they still lack the sense of realism and physical presence of the remote operator. This results in a lack of trust and adoption of such robots. In this paper, we introduce an Avatar Robot System which is a mixed real/virtual robotic system that physically interacts with a person in proximity of the robot. The robot structure is overlaid with the 3D model of the remote caregiver and visualized through Augmented Reality (AR). In this way, the person receives haptic feedback as the robot touches him/her. We further present an Optimal Non-Iterative Alignment solver that solves for the optimally aligned pose of 3D Human model to the robot (shoulder to the wrist non-iteratively). The proposed alignment solver is stateless, achieves optimal alignment and faster than the baseline solvers (demonstrated in our evaluations). We also propose an evaluation framework that quantifies the alignment quality of the solvers through multifaceted metrics. We show that our solver can consistently produce poses with similar or superior alignments as IK-based baselines without their potential drawbacks.
Handle Anywhere: A Mobile Robot Arm for Providing Bodily Support to Elderly Persons
Sep 30, 2022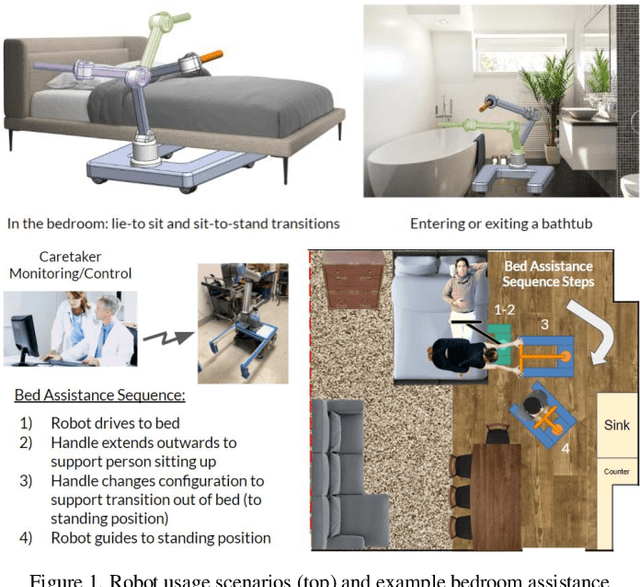
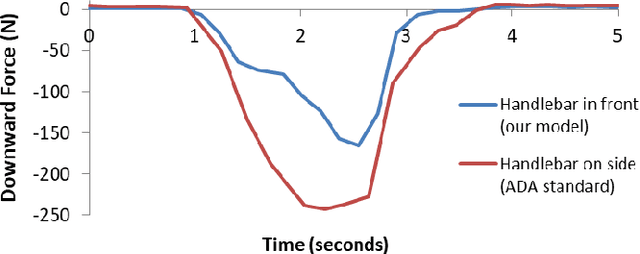
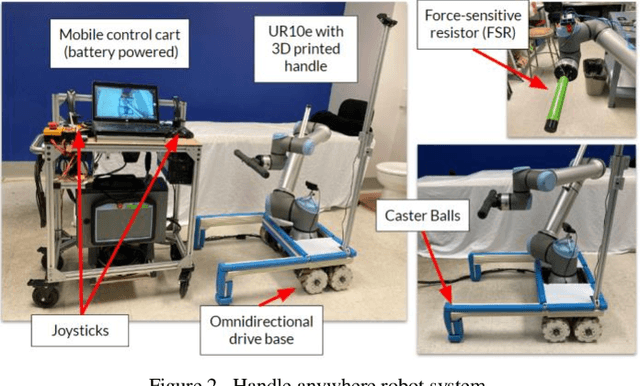
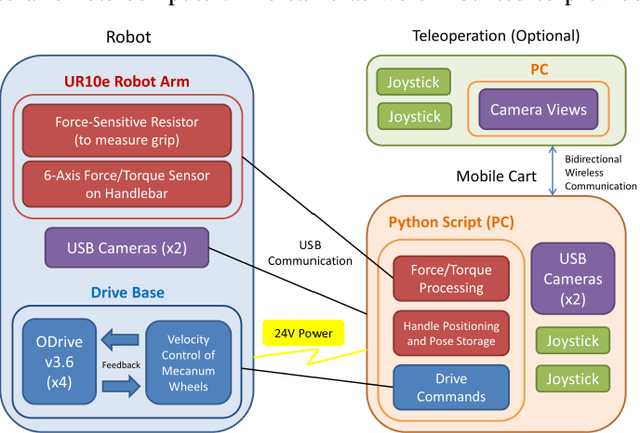
Age-related loss of mobility and increased risk of falling remain important obstacles toward facilitating aging-in-place. Many elderly people lack the coordination and strength necessary to perform common movements around their home, such as getting out of bed or stepping into a bathtub. The traditional solution has been to install grab bars on various surfaces; however, these are often not placed in optimal locations due to feasibility constraints in room layout. In this paper, we present a mobile robot that provides an older adult with a handle anywhere in space - "handle anywhere". The robot consists of an omnidirectional mobile base attached to a repositionable handle. We analyze the postural changes in four activities of daily living and determine, in each, the body pose that requires the maximal muscle effort. Using a simple model of the human body, we develop a methodology to optimally place the handle to provide the maximum support for the elderly person at the point of most effort. Our model is validated with experimental trials. We discuss how the robotic device could be used to enhance patient mobility and reduce the incidence of falls.
Multimodal Fusion of EMG and Vision for Human Grasp Intent Inference in Prosthetic Hand Control
Apr 08, 2021



For lower arm amputees, robotic prosthetic hands offer the promise to regain the capability to perform fine object manipulation in activities of daily living. Current control methods based on physiological signals such as EEG and EMG are prone to poor inference outcomes due to motion artifacts, variability of skin electrode junction impedance over time, muscle fatigue, and other factors. Visual evidence is also susceptible to its own artifacts, most often due to object occlusion, lighting changes, variable shapes of objects depending on view-angle, among other factors. Multimodal evidence fusion using physiological and vision sensor measurements is a natural approach due to the complementary strengths of these modalities. In this paper, we present a Bayesian evidence fusion framework for grasp intent inference using eye-view video, gaze, and EMG from the forearm processed by neural network models. We analyze individual and fused performance as a function of time as the hand approaches the object to grasp it. For this purpose, we have also developed novel data processing and augmentation techniques to train neural network components. Our experimental data analyses demonstrate that EMG and visual evidence show complementary strengths, and as a consequence, fusion of multimodal evidence can outperform each individual evidence modality at any given time. Specifically, results indicate that, on average, fusion improves the instantaneous upcoming grasp type classification accuracy while in the reaching phase by 13.66% and 14.8%, relative to EMG and visual evidence individually. An overall fusion accuracy of 95.3% among 13 labels (compared to a chance level of 7.7%) is achieved, and more detailed analysis indicate that the correct grasp is inferred sufficiently early and with high confidence compared to the top contender, in order to allow successful robot actuation to close the loop.
From Hand-Perspective Visual Information to Grasp Type Probabilities: Deep Learning via Ranking Labels
Mar 08, 2021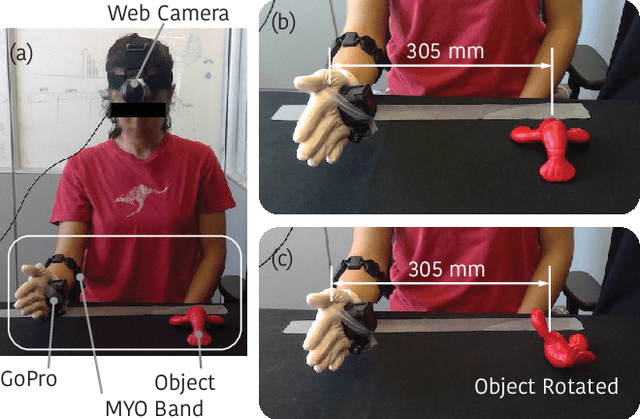
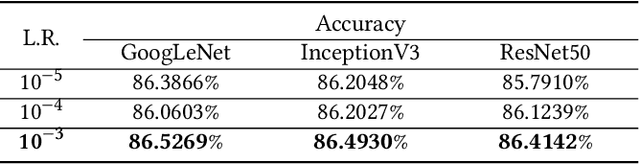

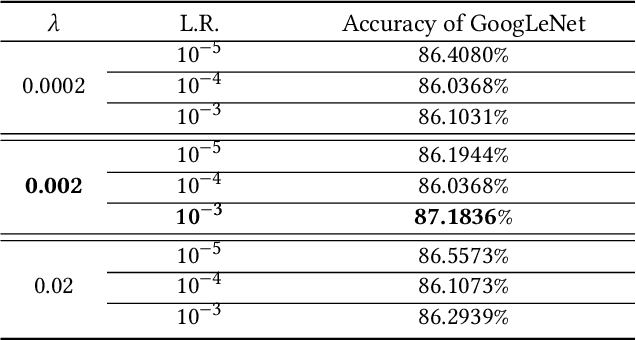
Limb deficiency severely affects the daily lives of amputees and drives efforts to provide functional robotic prosthetic hands to compensate this deprivation. Convolutional neural network-based computer vision control of the prosthetic hand has received increased attention as a method to replace or complement physiological signals due to its reliability by training visual information to predict the hand gesture. Mounting a camera into the palm of a prosthetic hand is proved to be a promising approach to collect visual data. However, the grasp type labelled from the eye and hand perspective may differ as object shapes are not always symmetric. Thus, to represent this difference in a realistic way, we employed a dataset containing synchronous images from eye- and hand- view, where the hand-perspective images are used for training while the eye-view images are only for manual labelling. Electromyogram (EMG) activity and movement kinematics data from the upper arm are also collected for multi-modal information fusion in future work. Moreover, in order to include human-in-the-loop control and combine the computer vision with physiological signal inputs, instead of making absolute positive or negative predictions, we build a novel probabilistic classifier according to the Plackett-Luce model. To predict the probability distribution over grasps, we exploit the statistical model over label rankings to solve the permutation domain problems via a maximum likelihood estimation, utilizing the manually ranked lists of grasps as a new form of label. We indicate that the proposed model is applicable to the most popular and productive convolutional neural network frameworks.