 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp-HGN: Grasping the Unexpected
Aug 11, 2025For transradial amputees, robotic prosthetic hands promise to regain the capability to perform daily living activities. To advance next-generation prosthetic hand control design, it is crucial to address current shortcomings in robustness to out of lab artifacts, and generalizability to new environments. Due to the fixed number of object to interact with in existing datasets, contrasted with the virtually infinite variety of objects encountered in the real world, current grasp models perform poorly on unseen objects, negatively affecting users' independence and quality of life. To address this: (i) we define semantic projection, the ability of a model to generalize to unseen object types and show that conventional models like YOLO, despite 80% training accuracy, drop to 15% on unseen objects. (ii) we propose Grasp-LLaVA, a Grasp Vision Language Model enabling human-like reasoning to infer the suitable grasp type estimate based on the object's physical characteristics resulting in a significant 50.2% accuracy over unseen object types compared to 36.7% accuracy of an SOTA grasp estimation model. Lastly, to bridge the performance-latency gap, we propose Hybrid Grasp Network (HGN), an edge-cloud deployment infrastructure enabling fast grasp estimation on edge and accurate cloud inference as a fail-safe, effectively expanding the latency vs. accuracy Pareto. HGN with confidence calibration (DC) enables dynamic switching between edge and cloud models, improving semantic projection accuracy by 5.6% (to 42.3%) with 3.5x speedup over the unseen object types. Over a real-world sample mix, it reaches 86% average accuracy (12.2% gain over edge-only), and 2.2x faster inference than Grasp-LLaVA alone.
Segmentation and Classification of EMG Time-Series During Reach-to-Grasp Motion
Apr 19, 2021


The electromyography (EMG) signals have been widely utilized in human robot interaction for extracting user hand and arm motion instructions. A major challenge of the online interaction with robots is the reliable EMG recognition from real-time data. However, previous studies mainly focused on using steady-state EMG signals with a small number of grasp patterns to implement classification algorithms, which is insufficient to generate robust control regarding the dynamic muscular activity variation in practice. Introducing more EMG variability during training and validation could implement a better dynamic-motion detection, but only limited research focused on such grasp-movement identification, and all of those assessments on the non-static EMG classification require supervised ground-truth label of the movement status. In this study, we propose a framework for classifying EMG signals generated from continuous grasp movements with variations on dynamic arm/hand postures, using an unsupervised motion status segmentation method. We collected data from large gesture vocabularies with multiple dynamic motion phases to encode the transitions from one intent to another based on common sequences of the grasp movements. Two classifiers were constructed for identifying the motion-phase label and grasp-type label, where the dynamic motion phases were segmented and labeled in an unsupervised manner. The proposed framework was evaluated in real-time with the accuracy variation over time presented, which was shown to be efficient due to the high degree of freedom of the EMG data.
Multimodal Fusion of EMG and Vision for Human Grasp Intent Inference in Prosthetic Hand Control
Apr 08, 2021



For lower arm amputees, robotic prosthetic hands offer the promise to regain the capability to perform fine object manipulation in activities of daily living. Current control methods based on physiological signals such as EEG and EMG are prone to poor inference outcomes due to motion artifacts, variability of skin electrode junction impedance over time, muscle fatigue, and other factors. Visual evidence is also susceptible to its own artifacts, most often due to object occlusion, lighting changes, variable shapes of objects depending on view-angle, among other factors. Multimodal evidence fusion using physiological and vision sensor measurements is a natural approach due to the complementary strengths of these modalities. In this paper, we present a Bayesian evidence fusion framework for grasp intent inference using eye-view video, gaze, and EMG from the forearm processed by neural network models. We analyze individual and fused performance as a function of time as the hand approaches the object to grasp it. For this purpose, we have also developed novel data processing and augmentation techniques to train neural network components. Our experimental data analyses demonstrate that EMG and visual evidence show complementary strengths, and as a consequence, fusion of multimodal evidence can outperform each individual evidence modality at any given time. Specifically, results indicate that, on average, fusion improves the instantaneous upcoming grasp type classification accuracy while in the reaching phase by 13.66% and 14.8%, relative to EMG and visual evidence individually. An overall fusion accuracy of 95.3% among 13 labels (compared to a chance level of 7.7%) is achieved, and more detailed analysis indicate that the correct grasp is inferred sufficiently early and with high confidence compared to the top contender, in order to allow successful robot actuation to close the loop.
NetCut: Real-Time DNN Inference Using Layer Removal
Jan 13, 2021

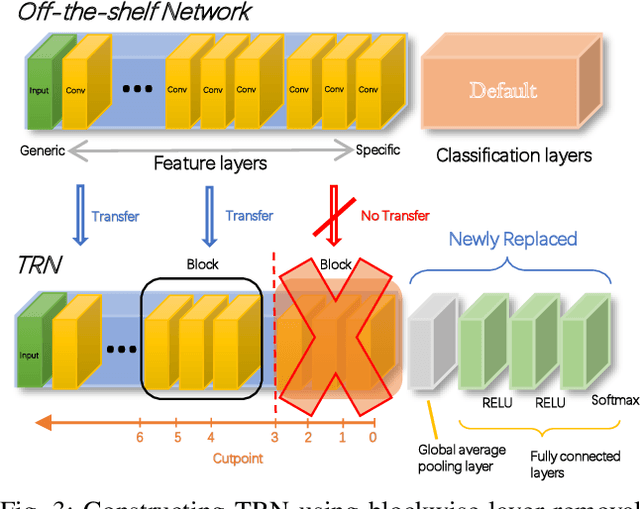
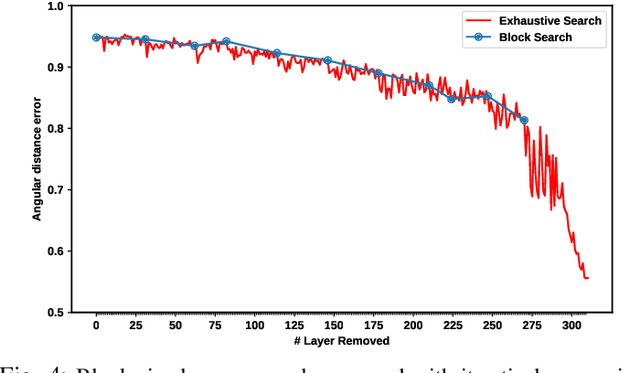
Deep Learning plays a significant role in assisting humans in many aspects of their lives. As these networks tend to get deeper over time, they extract more features to increase accuracy at the cost of additional inference latency. This accuracy-performance trade-off makes it more challenging for Embedded Systems, as resource-constrained processors with strict deadlines, to deploy them efficiently. This can lead to selection of networks that can prematurely meet a specified deadline with excess slack time that could have potentially contributed to increased accuracy. In this work, we propose: (i) the concept of layer removal as a means of constructing TRimmed Networks (TRNs) that are based on removing problem-specific features of a pretrained network used in transfer learning, and (ii) NetCut, a methodology based on an empirical or an analytical latency estimator, which only proposes and retrains TRNs that can meet the application's deadline, hence reducing the exploration time significantly. We demonstrate that TRNs can expand the Pareto frontier that trades off latency and accuracy to provide networks that can meet arbitrary deadlines with potential accuracy improvement over off-the-shelf networks. Our experimental results show that such utilization of TRNs, while transferring to a simpler dataset, in combination with NetCut, can lead to the proposal of networks that can achieve relative accuracy improvement of up to 10.43% among existing off-the-shelf neural architectures while meeting a specific deadline, and 27x speedup in exploration time.
Towards Creating a Deployable Grasp Type Probability Estimator for a Prosthetic Hand
Jan 13, 2021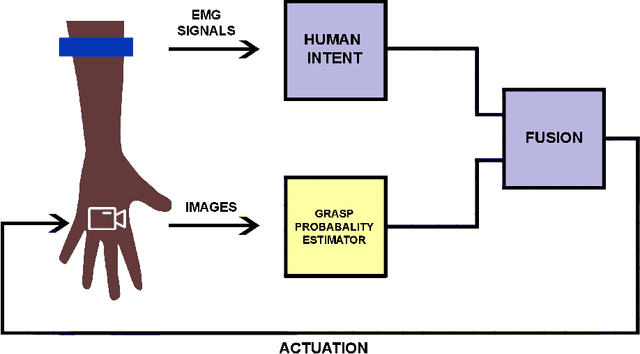

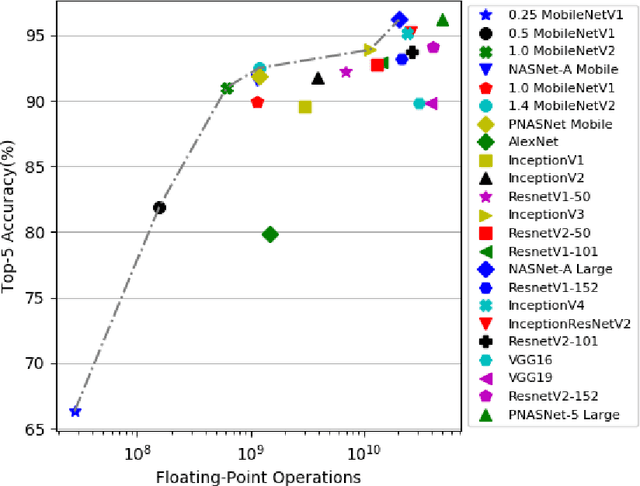

For lower arm amputees, prosthetic hands promise to restore most of physical interaction capabilities. This requires to accurately predict hand gestures capable of grabbing varying objects and execute them timely as intended by the user. Current approaches often rely on physiological signal inputs such as Electromyography (EMG) signal from residual limb muscles to infer the intended motion. However, limited signal quality, user diversity and high variability adversely affect the system robustness. Instead of solely relying on EMG signals, our work enables augmenting EMG intent inference with physical state probability through machine learning and computer vision method. To this end, we: (1) study state-of-the-art deep neural network architectures to select a performant source of knowledge transfer for the prosthetic hand, (2) use a dataset containing object images and probability distribution of grasp types as a new form of labeling where instead of using absolute values of zero and one as the conventional classification labels, our labels are a set of probabilities whose sum is 1. The proposed method generates probabilistic predictions which could be fused with EMG prediction of probabilities over grasps by using the visual information from the palm camera of a prosthetic hand. Our results demonstrate that InceptionV3 achieves highest accuracy with 0.95 angular similarity followed by 1.4 MobileNetV2 with 0.93 at ~20% the amount of operations.