 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation and Classification of EMG Time-Series During Reach-to-Grasp Motion
Apr 19, 2021
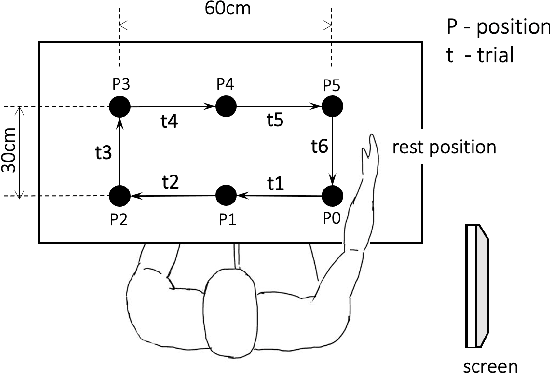


The electromyography (EMG) signals have been widely utilized in human robot interaction for extracting user hand and arm motion instructions. A major challenge of the online interaction with robots is the reliable EMG recognition from real-time data. However, previous studies mainly focused on using steady-state EMG signals with a small number of grasp patterns to implement classification algorithms, which is insufficient to generate robust control regarding the dynamic muscular activity variation in practice. Introducing more EMG variability during training and validation could implement a better dynamic-motion detection, but only limited research focused on such grasp-movement identification, and all of those assessments on the non-static EMG classification require supervised ground-truth label of the movement status. In this study, we propose a framework for classifying EMG signals generated from continuous grasp movements with variations on dynamic arm/hand postures, using an unsupervised motion status segmentation method. We collected data from large gesture vocabularies with multiple dynamic motion phases to encode the transitions from one intent to another based on common sequences of the grasp movements. Two classifiers were constructed for identifying the motion-phase label and grasp-type label, where the dynamic motion phases were segmented and labeled in an unsupervised manner. The proposed framework was evaluated in real-time with the accuracy variation over time presented, which was shown to be efficient due to the high degree of freedom of the EMG data.
Multimodal Fusion of EMG and Vision for Human Grasp Intent Inference in Prosthetic Hand Control
Apr 08, 2021



For lower arm amputees, robotic prosthetic hands offer the promise to regain the capability to perform fine object manipulation in activities of daily living. Current control methods based on physiological signals such as EEG and EMG are prone to poor inference outcomes due to motion artifacts, variability of skin electrode junction impedance over time, muscle fatigue, and other factors. Visual evidence is also susceptible to its own artifacts, most often due to object occlusion, lighting changes, variable shapes of objects depending on view-angle, among other factors. Multimodal evidence fusion using physiological and vision sensor measurements is a natural approach due to the complementary strengths of these modalities. In this paper, we present a Bayesian evidence fusion framework for grasp intent inference using eye-view video, gaze, and EMG from the forearm processed by neural network models. We analyze individual and fused performance as a function of time as the hand approaches the object to grasp it. For this purpose, we have also developed novel data processing and augmentation techniques to train neural network components. Our experimental data analyses demonstrate that EMG and visual evidence show complementary strengths, and as a consequence, fusion of multimodal evidence can outperform each individual evidence modality at any given time. Specifically, results indicate that, on average, fusion improves the instantaneous upcoming grasp type classification accuracy while in the reaching phase by 13.66% and 14.8%, relative to EMG and visual evidence individually. An overall fusion accuracy of 95.3% among 13 labels (compared to a chance level of 7.7%) is achieved, and more detailed analysis indicate that the correct grasp is inferred sufficiently early and with high confidence compared to the top contender, in order to allow successful robot actuation to close the loop.