 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Hand-Perspective Visual Information to Grasp Type Probabilities: Deep Learning via Ranking Labels
Mar 08, 2021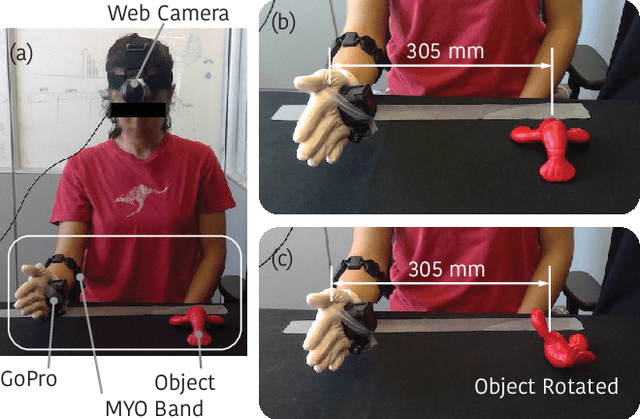
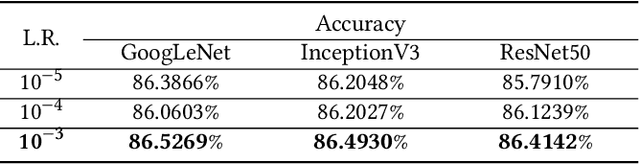

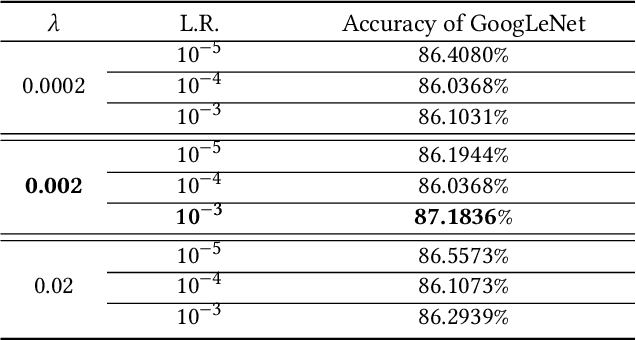
Limb deficiency severely affects the daily lives of amputees and drives efforts to provide functional robotic prosthetic hands to compensate this deprivation. Convolutional neural network-based computer vision control of the prosthetic hand has received increased attention as a method to replace or complement physiological signals due to its reliability by training visual information to predict the hand gesture. Mounting a camera into the palm of a prosthetic hand is proved to be a promising approach to collect visual data. However, the grasp type labelled from the eye and hand perspective may differ as object shapes are not always symmetric. Thus, to represent this difference in a realistic way, we employed a dataset containing synchronous images from eye- and hand- view, where the hand-perspective images are used for training while the eye-view images are only for manual labelling. Electromyogram (EMG) activity and movement kinematics data from the upper arm are also collected for multi-modal information fusion in future work. Moreover, in order to include human-in-the-loop control and combine the computer vision with physiological signal inputs, instead of making absolute positive or negative predictions, we build a novel probabilistic classifier according to the Plackett-Luce model. To predict the probability distribution over grasps, we exploit the statistical model over label rankings to solve the permutation domain problems via a maximum likelihood estimation, utilizing the manually ranked lists of grasps as a new form of label. We indicate that the proposed model is applicable to the most popular and productive convolutional neural network frameworks.
HANDS: A Multimodal Dataset for Modeling Towards Human Grasp Intent Inference in Prosthetic Hands
Mar 08, 2021



Upper limb and hand functionality is critical to many activities of daily living and the amputation of one can lead to significant functionality loss for individuals. From this perspective, advanced prosthetic hands of the future are anticipated to benefit from improved shared control between a robotic hand and its human user, but more importantly from the improved capability to infer human intent from multimodal sensor data to provide the robotic hand perception abilities regarding the operational context. Such multimodal sensor data may include various environment sensors including vision, as well as human physiology and behavior sensors including electromyography and inertial measurement units. A fusion methodology for environmental state and human intent estimation can combine these sources of evidence in order to help prosthetic hand motion planning and control. In this paper, we present a dataset of this type that was gathered with the anticipation of cameras being built into prosthetic hands, and computer vision methods will need to assess this hand-view visual evidence in order to estimate human intent. Specifically, paired images from human eye-view and hand-view of various objects placed at different orientations have been captured at the initial state of grasping trials, followed by paired video, EMG and IMU from the arm of the human during a grasp, lift, put-down, and retract style trial structure. For each trial, based on eye-view images of the scene showing the hand and object on a table, multiple humans were asked to sort in decreasing order of preference, five grasp types appropriate for the object in its given configuration relative to the hand. The potential utility of paired eye-view and hand-view images was illustrated by training a convolutional neural network to process hand-view images in order to predict eye-view labels assigned by humans.