 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoBench: Benchmarking LLMs on Hard Topological Reasoning
Mar 12, 2026Solving topological grid puzzles requires reasoning over global spatial invariants such as connectivity, loop closure, and region symmetry and remains challenging for even the most powerful large language models (LLMs). To study these abilities under controlled settings, we introduce TopoBench, a benchmark of six puzzle families across three difficulty levels. We evaluate strong reasoning LLMs on TopoBench and find that even frontier models solve fewer than one quarter of hard instances, with two families nearly unsolved. To investigate whether these failures stem from reasoning limitations or from difficulty extracting and maintaining spatial constraints, we annotate 750 chain of thought traces with an error taxonomy that surfaces four candidate causal failure modes, then test them with targeted interventions simulating each error type. These interventions show that certain error patterns like premature commitment and constraint forgetting have a direct impact on the ability to solve the puzzle, while repeated reasoning is a benign effect of search. Finally we study mitigation strategies including prompt guidance, cell-aligned grid representations and tool-based constraint checking, finding that the bottleneck lies in extracting constraints from spatial representations and not in reasoning over them. Code and data are available at github.com/mayug/topobench-benchmark.
Dataset Clustering for Improved Offline Policy Learning
Feb 14, 2024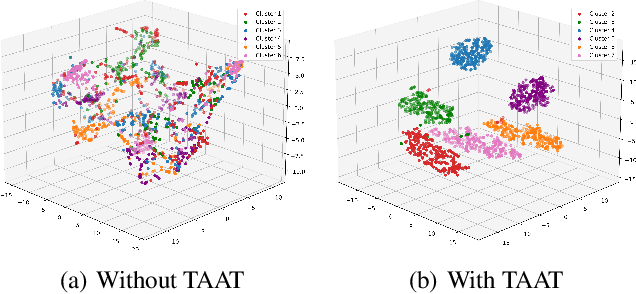
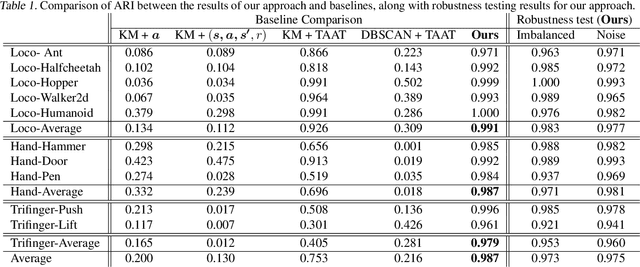
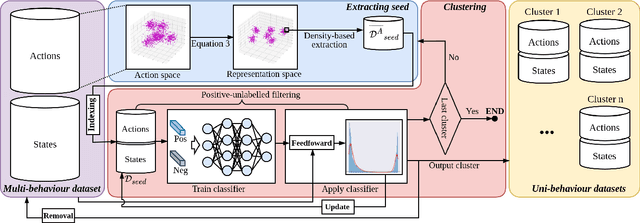

Offline policy learning aims to discover decision-making policies from previously-collected datasets without additional online interactions with the environment. As the training dataset is fixed, its quality becomes a crucial determining factor in the performance of the learned policy. This paper studies a dataset characteristic that we refer to as multi-behavior, indicating that the dataset is collected using multiple policies that exhibit distinct behaviors. In contrast, a uni-behavior dataset would be collected solely using one policy. We observed that policies learned from a uni-behavior dataset typically outperform those learned from multi-behavior datasets, despite the uni-behavior dataset having fewer examples and less diversity. Therefore, we propose a behavior-aware deep clustering approach that partitions multi-behavior datasets into several uni-behavior subsets, thereby benefiting downstream policy learning. Our approach is flexible and effective; it can adaptively estimate the number of clusters while demonstrating high clustering accuracy, achieving an average Adjusted Rand Index of 0.987 across various continuous control task datasets. Finally, we present improved policy learning examples using dataset clustering and discuss several potential scenarios where our approach might benefit the offline policy learning community.
Privacy-Aware Energy Consumption Modeling of Connected Battery Electric Vehicles using Federated Learning
Dec 12, 2023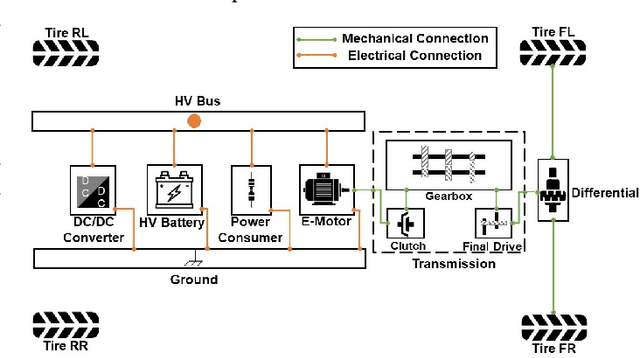
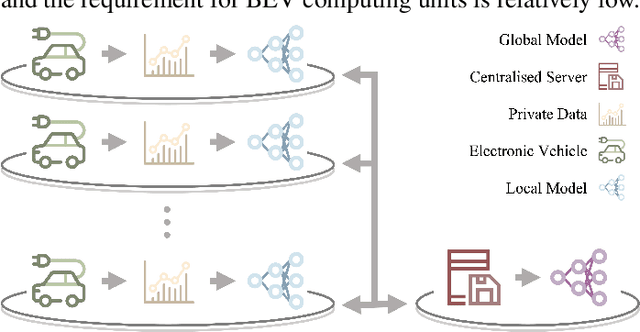
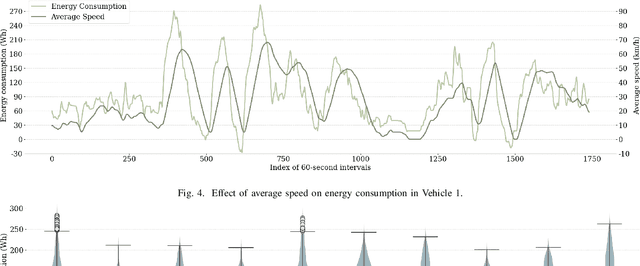
Battery Electric Vehicles (BEVs) are increasingly significant in modern cities due to their potential to reduce air pollution. Precise and real-time estimation of energy consumption for them is imperative for effective itinerary planning and optimizing vehicle systems, which can reduce driving range anxiety and decrease energy costs. As public awareness of data privacy increases, adopting approaches that safeguard data privacy in the context of BEV energy consumption modeling is crucial. Federated Learning (FL) is a promising solution mitigating the risk of exposing sensitive information to third parties by allowing local data to remain on devices and only sharing model updates with a central server. Our work investigates the potential of using FL methods, such as FedAvg, and FedPer, to improve BEV energy consumption prediction while maintaining user privacy. We conducted experiments using data from 10 BEVs under simulated real-world driving conditions. Our results demonstrate that the FedAvg-LSTM model achieved a reduction of up to 67.84\% in the MAE value of the prediction results. Furthermore, we explored various real-world scenarios and discussed how FL methods can be employed in those cases. Our findings show that FL methods can effectively improve the performance of BEV energy consumption prediction while maintaining user privacy.
Learning Saliency From Fixations
Nov 23, 2023We present a novel approach for saliency prediction in images, leveraging parallel decoding in transformers to learn saliency solely from fixation maps. Models typically rely on continuous saliency maps, to overcome the difficulty of optimizing for the discrete fixation map. We attempt to replicate the experimental setup that generates saliency datasets. Our approach treats saliency prediction as a direct set prediction problem, via a global loss that enforces unique fixations prediction through bipartite matching and a transformer encoder-decoder architecture. By utilizing a fixed set of learned fixation queries, the cross-attention reasons over the image features to directly output the fixation points, distinguishing it from other modern saliency predictors. Our approach, named Saliency TRansformer (SalTR), achieves metric scores on par with state-of-the-art approaches on the Salicon and MIT300 benchmarks.
Learning and reusing primitive behaviours to improve Hindsight Experience Replay sample efficiency
Oct 03, 2023
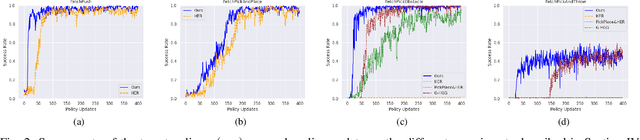
Hindsight Experience Replay (HER) is a technique used in reinforcement learning (RL) that has proven to be very efficient for training off-policy RL-based agents to solve goal-based robotic manipulation tasks using sparse rewards. Even though HER improves the sample efficiency of RL-based agents by learning from mistakes made in past experiences, it does not provide any guidance while exploring the environment. This leads to very large training times due to the volume of experience required to train an agent using this replay strategy. In this paper, we propose a method that uses primitive behaviours that have been previously learned to solve simple tasks in order to guide the agent toward more rewarding actions during exploration while learning other more complex tasks. This guidance, however, is not executed by a manually designed curriculum, but rather using a critic network to decide at each timestep whether or not to use the actions proposed by the previously-learned primitive policies. We evaluate our method by comparing its performance against HER and other more efficient variations of this algorithm in several block manipulation tasks. We demonstrate the agents can learn a successful policy faster when using our proposed method, both in terms of sample efficiency and computation time. Code is available at https://github.com/franroldans/qmp-her.
A Review on AI Algorithms for Energy Management in E-Mobility Services
Sep 26, 2023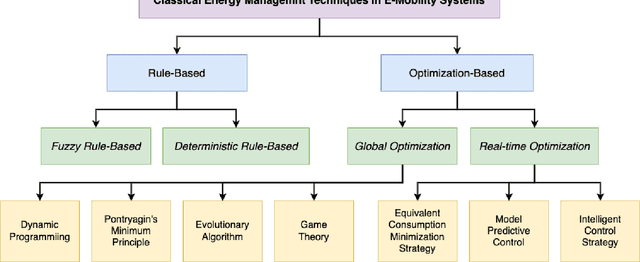
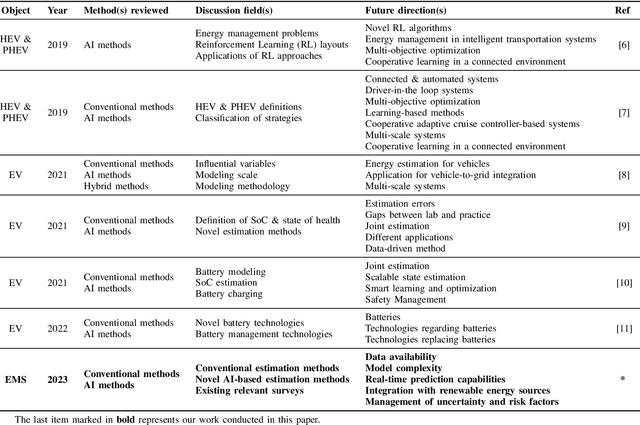
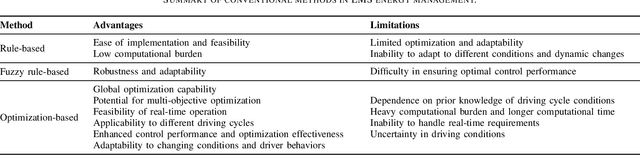
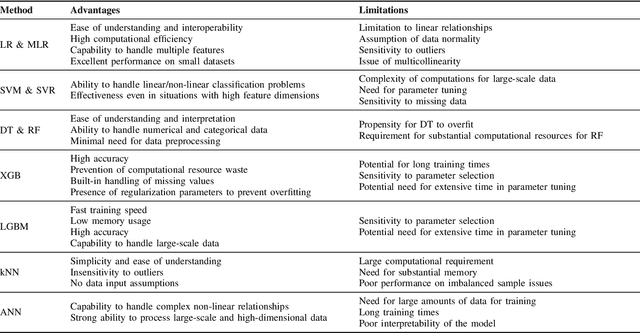
E-mobility, or electric mobility, has emerged as a pivotal solution to address pressing environmental and sustainability concerns in the transportation sector. The depletion of fossil fuels, escalating greenhouse gas emissions, and the imperative to combat climate change underscore the significance of transitioning to electric vehicles (EVs). This paper seeks to explore the potential of artificial intelligence (AI) in addressing various challenges related to effective energy management in e-mobility systems (EMS). These challenges encompass critical factors such as range anxiety, charge rate optimization, and the longevity of energy storage in EVs. By analyzing existing literature, we delve into the role that AI can play in tackling these challenges and enabling efficient energy management in EMS. Our objectives are twofold: to provide an overview of the current state-of-the-art in this research domain and propose effective avenues for future investigations. Through this analysis, we aim to contribute to the advancement of sustainable and efficient e-mobility solutions, shaping a greener and more sustainable future for transportation.
An Ensemble Deep Learning Approach for COVID-19 Severity Prediction Using Chest CT Scans
May 17, 2023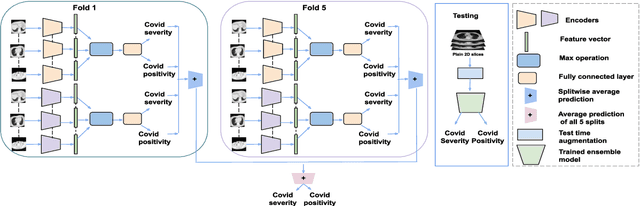
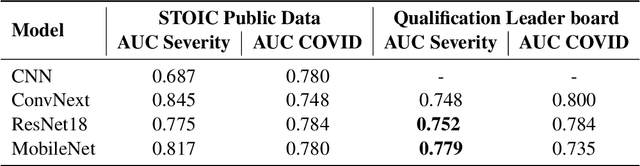

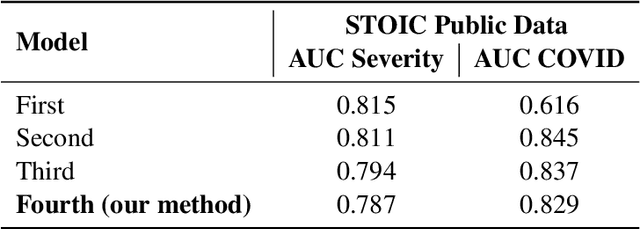
Chest X-rays have been widely used for COVID-19 screening; however, 3D computed tomography (CT) is a more effective modality. We present our findings on COVID-19 severity prediction from chest CT scans using the STOIC dataset. We developed an ensemble deep learning based model that incorporates multiple neural networks to improve predictions. To address data imbalance, we used slicing functions and data augmentation. We further improved performance using test time data augmentation. Our approach which employs a simple yet effective ensemble of deep learning-based models with strong test time augmentations, achieved results comparable to more complex methods and secured the fourth position in the STOIC2021 COVID-19 AI Challenge. Our code is available on online: at: https://github.com/aleemsidra/stoic2021- baseline-finalphase-main.
BaseTransformers: Attention over base data-points for One Shot Learning
Oct 05, 2022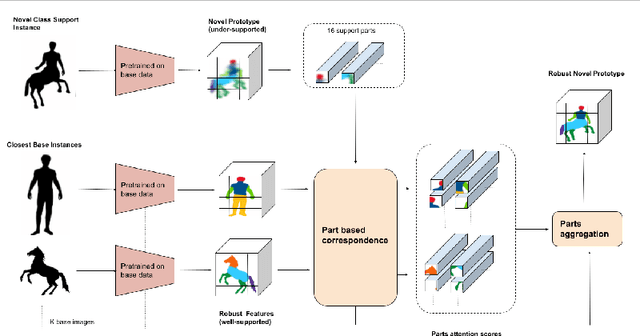
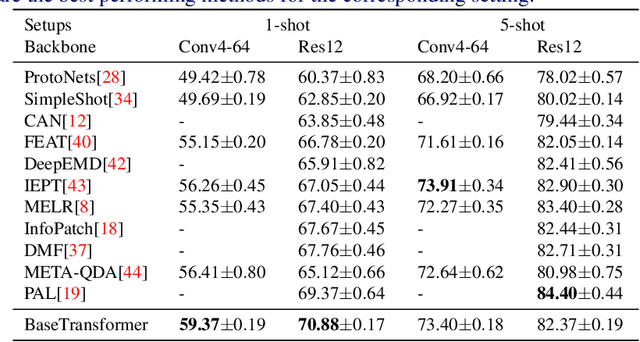
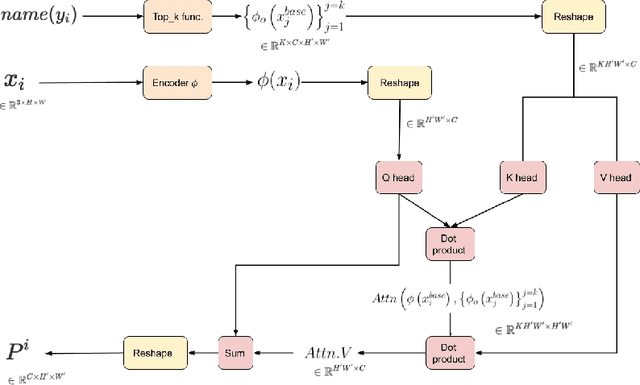
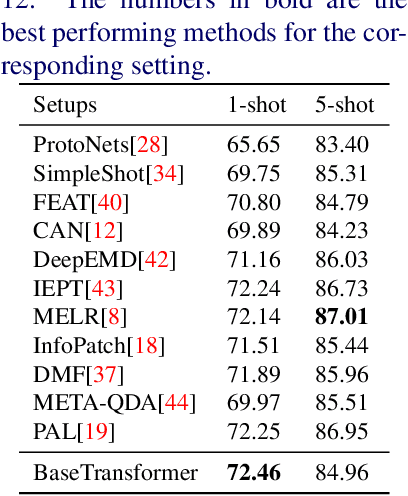
Few shot classification aims to learn to recognize novel categories using only limited samples per category. Most current few shot methods use a base dataset rich in labeled examples to train an encoder that is used for obtaining representations of support instances for novel classes. Since the test instances are from a distribution different to the base distribution, their feature representations are of poor quality, degrading performance. In this paper we propose to make use of the well-trained feature representations of the base dataset that are closest to each support instance to improve its representation during meta-test time. To this end, we propose BaseTransformers, that attends to the most relevant regions of the base dataset feature space and improves support instance representations. Experiments on three benchmark data sets show that our method works well for several backbones and achieves state-of-the-art results in the inductive one shot setting. Code is available at github.com/mayug/BaseTransformers
Hierarchical reinforcement learning for in-hand robotic manipulation using Davenport chained rotations
Oct 03, 2022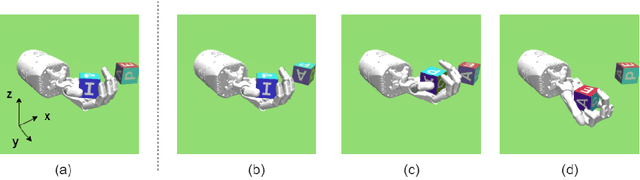
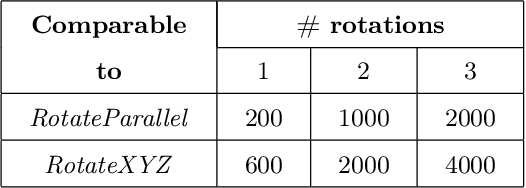
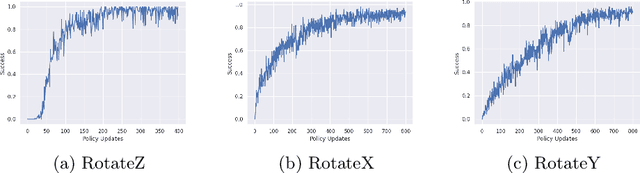

End-to-end reinforcement learning techniques are among the most successful methods for robotic manipulation tasks. However, the training time required to find a good policy capable of solving complex tasks is prohibitively large. Therefore, depending on the computing resources available, it might not be feasible to use such techniques. The use of domain knowledge to decompose manipulation tasks into primitive skills, to be performed in sequence, could reduce the overall complexity of the learning problem, and hence reduce the amount of training required to achieve dexterity. In this paper, we propose the use of Davenport chained rotations to decompose complex 3D rotation goals into a concatenation of a smaller set of more simple rotation skills. State-of-the-art reinforcement-learning-based methods can then be trained using less overall simulated experience. We compare its performance with the popular Hindsight Experience Replay method, trained in an end-to-end fashion using the same amount of experience in a simulated robotic hand environment. Despite a general decrease in performance of the primitive skills when being sequentially executed, we find that decomposing arbitrary 3D rotations into elementary rotations is beneficial when computing resources are limited, obtaining increases of success rates of approximately 10% on the most complex 3D rotations with respect to the success rates obtained by HER trained in an end-to-end fashion, and increases of success rates between 20% and 40% on the most simple rotations.
Towards advanced robotic manipulation
Sep 26, 2022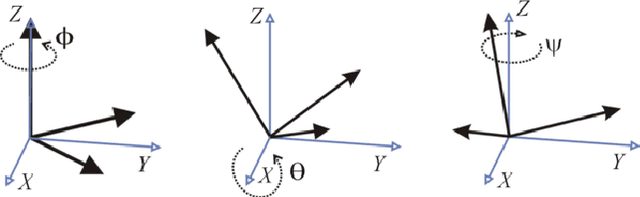
Robotic manipulation and control has increased in importance in recent years. However, state of the art techniques still have limitations when required to operate in real world applications. This paper explores Hindsight Experience Replay both in simulated and real environments, highlighting its weaknesses and proposing reinforcement-learning based alternatives based on reward and goal shaping. Additionally, several research questions are identified along with potential research directions that could be explored to tackle those questions.