 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Deep Neural Networks for Massive MIMO Data Detection
Apr 11, 2022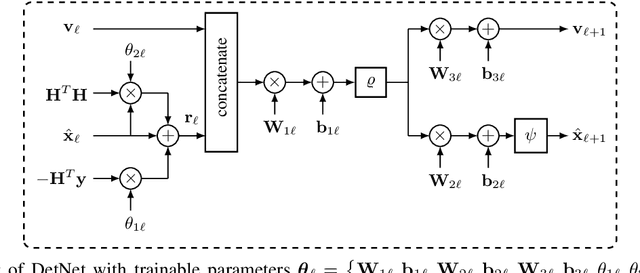
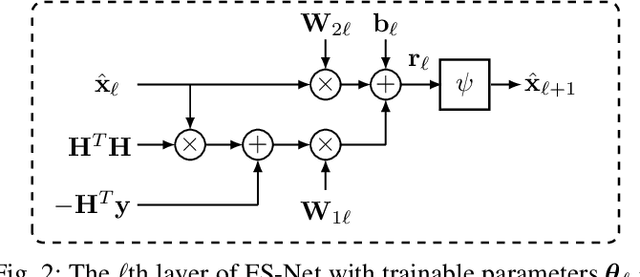
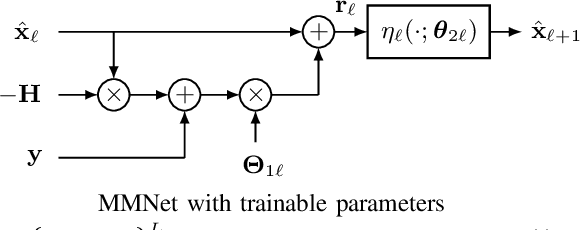
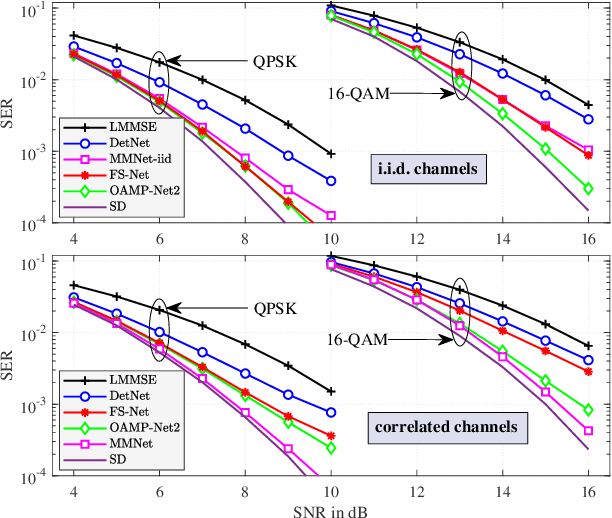
Massive multiple-input multiple-output (MIMO) is a key technology for emerging next-generation wireless systems. Utilizing large antenna arrays at base-stations, massive MIMO enables substantial spatial multiplexing gains by simultaneously serving a large number of users. However, the complexity in massive MIMO signal processing (e.g., data detection) increases rapidly with the number of users, making conventional hand-engineered algorithms less computationally efficient. Low-complexity massive MIMO detection algorithms, especially those inspired or aided by deep learning, have emerged as a promising solution. While there exist many MIMO detection algorithms, the aim of this magazine paper is to provide insight into how to leverage deep neural networks (DNN) for massive MIMO detection. We review recent developments in DNN-based MIMO detection that incorporate the domain knowledge of established MIMO detection algorithms with the learning capability of DNNs. We then present a comparison of the key numerical performance metrics of these works. We conclude by describing future research areas and applications of DNNs in massive MIMO receivers.
VinDr-CXR: An open dataset of chest X-rays with radiologist's annotations
Jan 03, 2021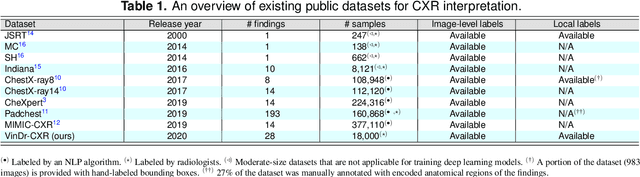
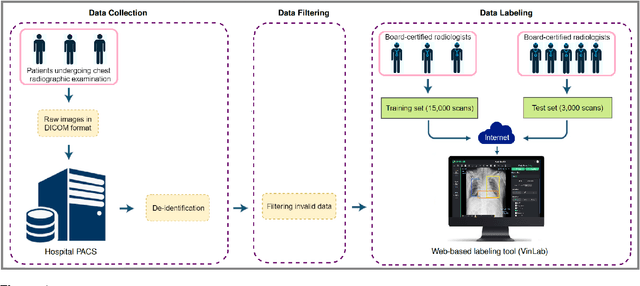
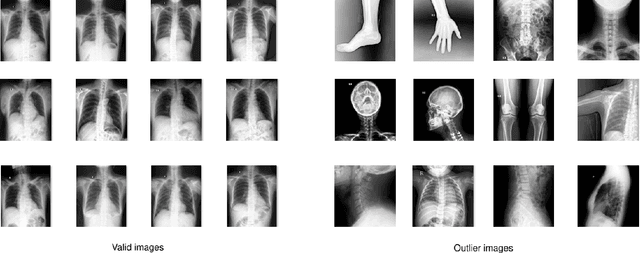
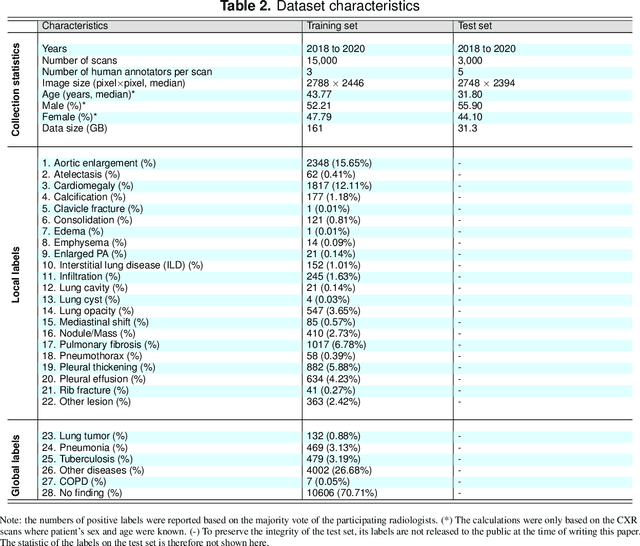
Most of the existing chest X-ray datasets include labels from a list of findings without specifying their locations on the radiographs. This limits the development of machine learning algorithms for the detection and localization of chest abnormalities. In this work, we describe a dataset of more than 100,000 chest X-ray scans that were retrospectively collected from two major hospitals in Vietnam. Out of this raw data, we release 18,000 images that were manually annotated by a total of 17 experienced radiologists with 22 local labels of rectangles surrounding abnormalities and 6 global labels of suspected diseases. The released dataset is divided into a training set of 15,000 and a test set of 3,000. Each scan in the training set was independently labeled by 3 radiologists, while each scan in the test set was labeled by the consensus of 5 radiologists. We designed and built a labeling platform for DICOM images to facilitate these annotation procedures. All images are made publicly available in DICOM format in company with the labels of the training set. The labels of the test set are hidden at the time of writing this paper as they will be used for benchmarking machine learning algorithms on an open platform.
A translational pathway of deep learning methods in GastroIntestinal Endoscopy
Oct 12, 2020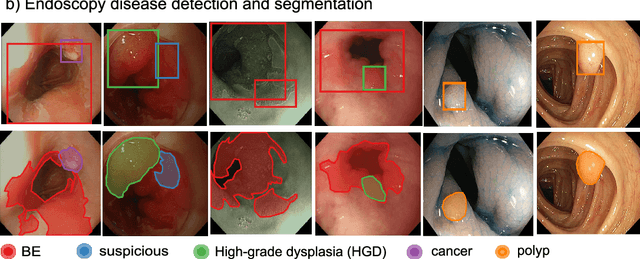
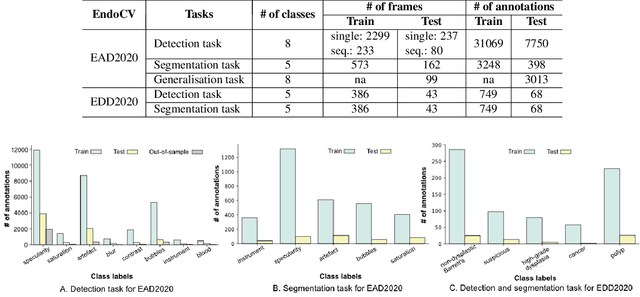
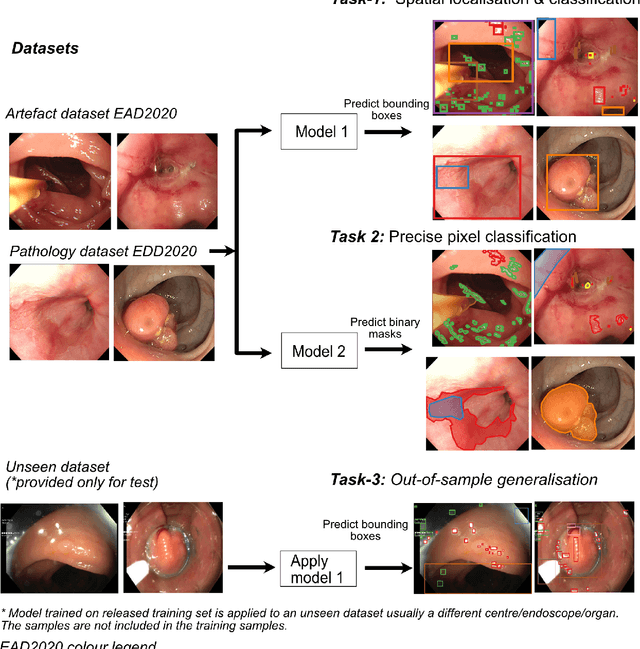
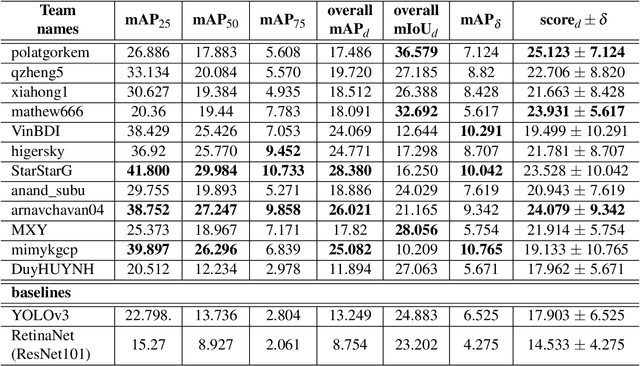
The Endoscopy Computer Vision Challenge (EndoCV) is a crowd-sourcing initiative to address eminent problems in developing reliable computer aided detection and diagnosis endoscopy systems and suggest a pathway for clinical translation of technologies. Whilst endoscopy is a widely used diagnostic and treatment tool for hollow-organs, there are several core challenges often faced by endoscopists, mainly: 1) presence of multi-class artefacts that hinder their visual interpretation, and 2) difficulty in identifying subtle precancerous precursors and cancer abnormalities. Artefacts often affect the robustness of deep learning methods applied to the gastrointestinal tract organs as they can be confused with tissue of interest. EndoCV2020 challenges are designed to address research questions in these remits. In this paper, we present a summary of methods developed by the top 17 teams and provide an objective comparison of state-of-the-art methods and methods designed by the participants for two sub-challenges: i) artefact detection and segmentation (EAD2020), and ii) disease detection and segmentation (EDD2020). Multi-center, multi-organ, multi-class, and multi-modal clinical endoscopy datasets were compiled for both EAD2020 and EDD2020 sub-challenges. An out-of-sample generalisation ability of detection algorithms was also evaluated. Whilst most teams focused on accuracy improvements, only a few methods hold credibility for clinical usability. The best performing teams provided solutions to tackle class imbalance, and variabilities in size, origin, modality and occurrences by exploring data augmentation, data fusion, and optimal class thresholding techniques.
Enhancing MRI Brain Tumor Segmentation with an Additional Classification Network
Sep 25, 2020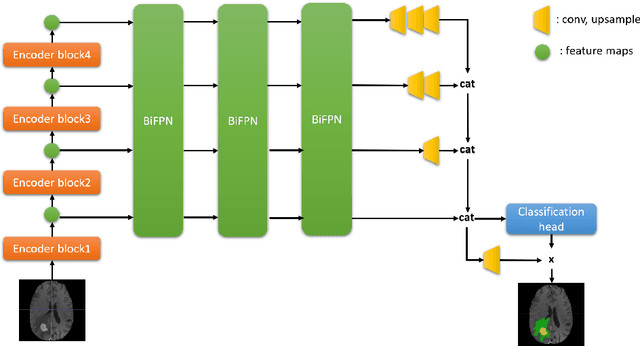
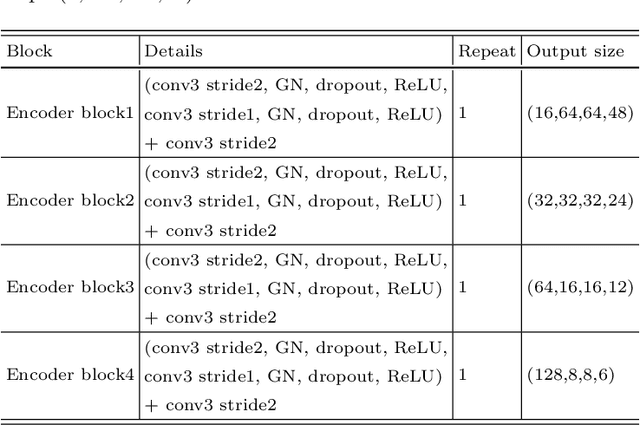
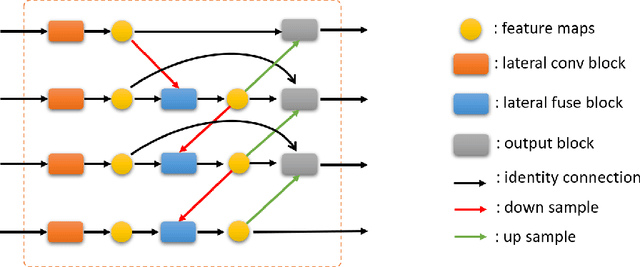
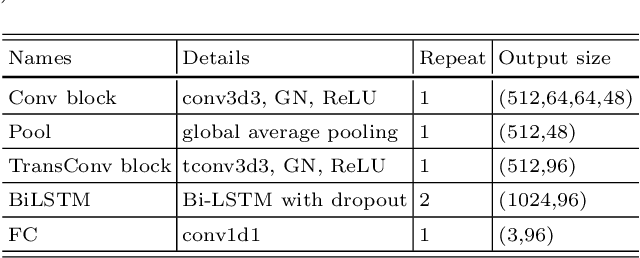
Brain tumor segmentation plays an essential role in medical image analysis. In recent studies, deep convolution neural networks (DCNNs) are extremely powerful to tackle tumor segmentation tasks. We propose in this paper a novel training method that enhances the segmentation results by adding an additional classification branch to the network. The whole network was trained end-to-end on the Multimodal Brain Tumor Segmentation Challenge (BraTS) 2020 training dataset. On the BraTS's validation set, it achieved an average Dice score of 78.43%, 89.99%, and 84.22% respectively for the enhancing tumor, the whole tumor, and the tumor core.
A CNN-LSTM Architecture for Detection of Intracranial Hemorrhage on CT scans
May 25, 2020We propose a novel method that combines a convolutional neural network (CNN) with a long short-term memory (LSTM) mechanism for accurate prediction of intracranial hemorrhage on computed tomography (CT) scans. The CNN plays the role of a slice-wise feature extractor while the LSTM is responsible for linking the features across slices. The whole architecture is trained end-to-end with input being an RGB-like image formed by stacking 3 different viewing windows of a single slice. We validate the method on the recent RSNA Intracranial Hemorrhage Detection challenge and on the CQ500 dataset. For the RSNA challenge, our best single model achieves a weighted log loss of 0.0522 on the leaderboard, which is comparable to the top 3% performances, almost all of which make use of ensemble learning. Importantly, our method generalizes very well: the model trained on the RSNA dataset significantly outperforms the 2D model, which does not take into account the relationship between slices, on CQ500. Our codes and models is publicly avaiable at https://github.com/nhannguyen2709/RSNA.