 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-module GRPO: Composing Policy Gradients and Prompt Optimization for Language Model Programs
Aug 06, 2025Group Relative Policy Optimization (GRPO) has proven to be an effective tool for post-training language models (LMs). However, AI systems are increasingly expressed as modular programs that mix together multiple LM calls with distinct prompt templates and other tools, and it is not clear how best to leverage GRPO to improve these systems. We begin to address this challenge by defining mmGRPO, a simple multi-module generalization of GRPO that groups LM calls by module across rollouts and handles variable-length and interrupted trajectories. We find that mmGRPO, composed with automatic prompt optimization, improves accuracy by 11% on average across classification, many-hop search, and privacy-preserving delegation tasks against the post-trained LM, and by 5% against prompt optimization on its own. We open-source mmGRPO in DSPy as the dspy.GRPO optimizer.
HyperDAS: Towards Automating Mechanistic Interpretability with Hypernetworks
Mar 13, 2025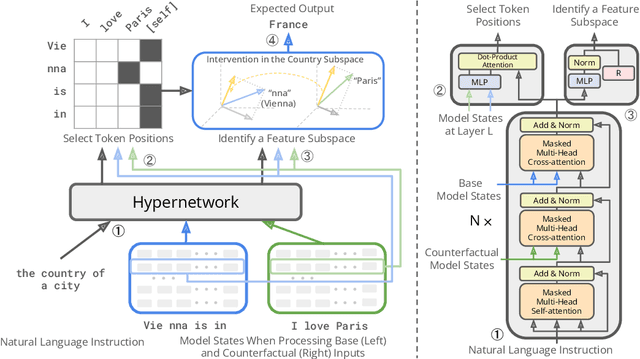
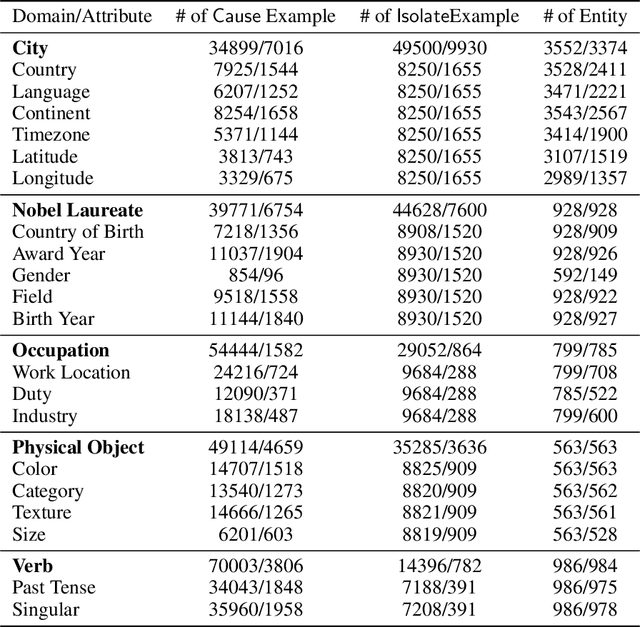
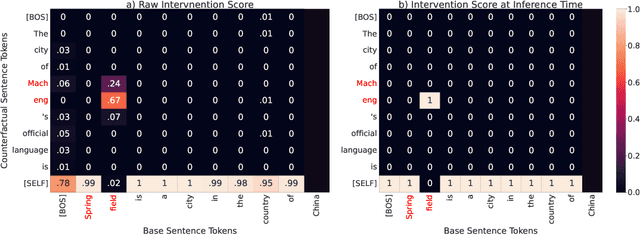
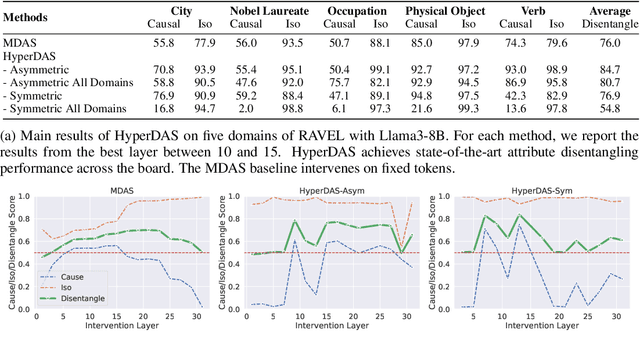
Mechanistic interpretability has made great strides in identifying neural network features (e.g., directions in hidden activation space) that mediate concepts(e.g., the birth year of a person) and enable predictable manipulation. Distributed alignment search (DAS) leverages supervision from counterfactual data to learn concept features within hidden states, but DAS assumes we can afford to conduct a brute force search over potential feature locations. To address this, we present HyperDAS, a transformer-based hypernetwork architecture that (1) automatically locates the token-positions of the residual stream that a concept is realized in and (2) constructs features of those residual stream vectors for the concept. In experiments with Llama3-8B, HyperDAS achieves state-of-the-art performance on the RAVEL benchmark for disentangling concepts in hidden states. In addition, we review the design decisions we made to mitigate the concern that HyperDAS (like all powerful interpretabilty methods) might inject new information into the target model rather than faithfully interpreting it.
Anchored Preference Optimization and Contrastive Revisions: Addressing Underspecification in Alignment
Aug 12, 2024



Large Language Models (LLMs) are often aligned using contrastive alignment objectives and preference pair datasets. The interaction between model, paired data, and objective makes alignment a complicated procedure, sometimes producing subpar results. We study this and find that (i) preference data gives a better learning signal when the underlying responses are contrastive, and (ii) alignment objectives lead to better performance when they specify more control over the model during training. Based on these insights, we introduce Contrastive Learning from AI Revisions (CLAIR), a data-creation method which leads to more contrastive preference pairs, and Anchored Preference Optimization (APO), a controllable and more stable alignment objective. We align Llama-3-8B-Instruct using various comparable datasets and alignment objectives and measure MixEval-Hard scores, which correlate highly with human judgments. The CLAIR preferences lead to the strongest performance out of all datasets, and APO consistently outperforms less controllable objectives. Our best model, trained on 32K CLAIR preferences with APO, improves Llama-3-8B-Instruct by 7.65%, closing the gap with GPT4-turbo by 45%. Our code is available at https://github.com/ContextualAI/CLAIR_and_APO.
Updating CLIP to Prefer Descriptions Over Captions
Jun 12, 2024Although CLIPScore is a powerful generic metric that captures the similarity between a text and an image, it fails to distinguish between a caption that is meant to complement the information in an image and a description that is meant to replace an image entirely, e.g., for accessibility. We address this shortcoming by updating the CLIP model with the Concadia dataset to assign higher scores to descriptions than captions using parameter efficient fine-tuning and a loss objective derived from work on causal interpretability. This model correlates with the judgements of blind and low-vision people while preserving transfer capabilities and has interpretable structure that sheds light on the caption--description distinction.
In-Context Learning for Extreme Multi-Label Classification
Jan 22, 2024Multi-label classification problems with thousands of classes are hard to solve with in-context learning alone, as language models (LMs) might lack prior knowledge about the precise classes or how to assign them, and it is generally infeasible to demonstrate every class in a prompt. We propose a general program, $\texttt{Infer--Retrieve--Rank}$, that defines multi-step interactions between LMs and retrievers to efficiently tackle such problems. We implement this program using the $\texttt{DSPy}$ programming model, which specifies in-context systems in a declarative manner, and use $\texttt{DSPy}$ optimizers to tune it towards specific datasets by bootstrapping only tens of few-shot examples. Our primary extreme classification program, optimized separately for each task, attains state-of-the-art results across three benchmarks (HOUSE, TECH, TECHWOLF). We apply the same program to a benchmark with vastly different characteristics and attain competitive performance as well (BioDEX). Unlike prior work, our proposed solution requires no finetuning, is easily applicable to new tasks, alleviates prompt engineering, and requires only tens of labeled examples. Our code is public at https://github.com/KarelDO/xmc.dspy.
Flexible Model Interpretability through Natural Language Model Editing
Nov 17, 2023Model interpretability and model editing are crucial goals in the age of large language models. Interestingly, there exists a link between these two goals: if a method is able to systematically edit model behavior with regard to a human concept of interest, this editor method can help make internal representations more interpretable by pointing towards relevant representations and systematically manipulating them.
CAW-coref: Conjunction-Aware Word-level Coreference Resolution
Oct 19, 2023


State-of-the-art coreference resolutions systems depend on multiple LLM calls per document and are thus prohibitively expensive for many use cases (e.g., information extraction with large corpora). The leading word-level coreference system (WL-coref) attains 96.6% of these SOTA systems' performance while being much more efficient. In this work, we identify a routine yet important failure case of WL-coref: dealing with conjoined mentions such as 'Tom and Mary'. We offer a simple yet effective solution that improves the performance on the OntoNotes test set by 0.9% F1, shrinking the gap between efficient word-level coreference resolution and expensive SOTA approaches by 34.6%. Our Conjunction-Aware Word-level coreference model (CAW-coref) and code is available at https://github.com/KarelDO/wl-coref.
Rigorously Assessing Natural Language Explanations of Neurons
Sep 19, 2023Natural language is an appealing medium for explaining how large language models process and store information, but evaluating the faithfulness of such explanations is challenging. To help address this, we develop two modes of evaluation for natural language explanations that claim individual neurons represent a concept in a text input. In the observational mode, we evaluate claims that a neuron $a$ activates on all and only input strings that refer to a concept picked out by the proposed explanation $E$. In the intervention mode, we construe $E$ as a claim that the neuron $a$ is a causal mediator of the concept denoted by $E$. We apply our framework to the GPT-4-generated explanations of GPT-2 XL neurons of Bills et al. (2023) and show that even the most confident explanations have high error rates and little to no causal efficacy. We close the paper by critically assessing whether natural language is a good choice for explanations and whether neurons are the best level of analysis.
BioDEX: Large-Scale Biomedical Adverse Drug Event Extraction for Real-World Pharmacovigilance
May 22, 2023



Timely and accurate extraction of Adverse Drug Events (ADE) from biomedical literature is paramount for public safety, but involves slow and costly manual labor. We set out to improve drug safety monitoring (pharmacovigilance, PV) through the use of Natural Language Processing (NLP). We introduce BioDEX, a large-scale resource for Biomedical adverse Drug Event Extraction, rooted in the historical output of drug safety reporting in the U.S. BioDEX consists of 65k abstracts and 19k full-text biomedical papers with 256k associated document-level safety reports created by medical experts. The core features of these reports include the reported weight, age, and biological sex of a patient, a set of drugs taken by the patient, the drug dosages, the reactions experienced, and whether the reaction was life threatening. In this work, we consider the task of predicting the core information of the report given its originating paper. We estimate human performance to be 72.0% F1, whereas our best model achieves 62.3% F1, indicating significant headroom on this task. We also begin to explore ways in which these models could help professional PV reviewers. Our code and data are available: https://github.com/KarelDO/BioDEX.
Causal Proxy Models for Concept-Based Model Explanations
Sep 28, 2022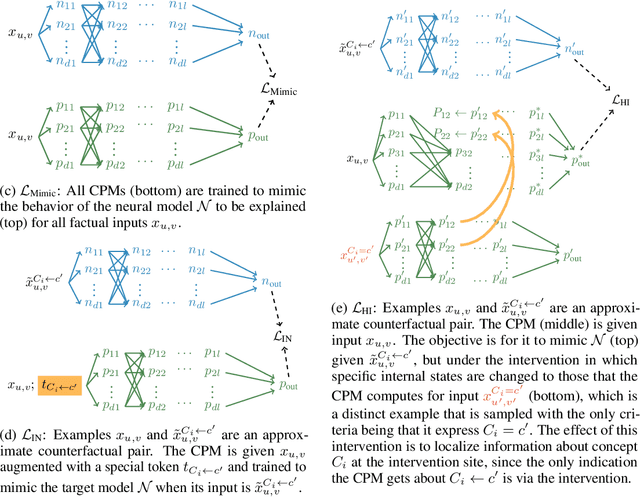
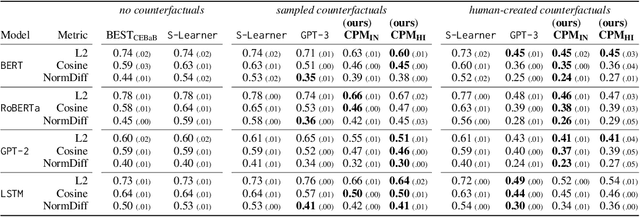

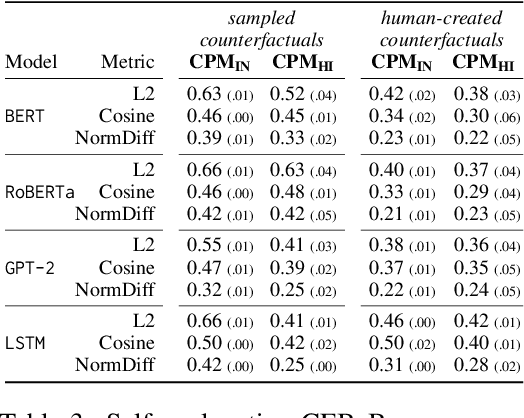
Explainability methods for NLP systems encounter a version of the fundamental problem of causal inference: for a given ground-truth input text, we never truly observe the counterfactual texts necessary for isolating the causal effects of model representations on outputs. In response, many explainability methods make no use of counterfactual texts, assuming they will be unavailable. In this paper, we show that robust causal explainability methods can be created using approximate counterfactuals, which can be written by humans to approximate a specific counterfactual or simply sampled using metadata-guided heuristics. The core of our proposal is the Causal Proxy Model (CPM). A CPM explains a black-box model $\mathcal{N}$ because it is trained to have the same actual input/output behavior as $\mathcal{N}$ while creating neural representations that can be intervened upon to simulate the counterfactual input/output behavior of $\mathcal{N}$. Furthermore, we show that the best CPM for $\mathcal{N}$ performs comparably to $\mathcal{N}$ in making factual predictions, which means that the CPM can simply replace $\mathcal{N}$, leading to more explainable deployed models. Our code is available at https://github.com/frankaging/Causal-Proxy-Model.