 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization, Generalization and Differential Privacy Bounds for Gradient Descent on Kolmogorov-Arnold Networks
Jan 29, 2026Kolmogorov--Arnold Networks (KANs) have recently emerged as a structured alternative to standard MLPs, yet a principled theory for their training dynamics, generalization, and privacy properties remains limited. In this paper, we analyze gradient descent (GD) for training two-layer KANs and derive general bounds that characterize their training dynamics, generalization, and utility under differential privacy (DP). As a concrete instantiation, we specialize our analysis to logistic loss under an NTK-separable assumption, where we show that polylogarithmic network width suffices for GD to achieve an optimization rate of order $1/T$ and a generalization rate of order $1/n$, with $T$ denoting the number of GD iterations and $n$ the sample size. In the private setting, we characterize the noise required for $(ε,δ)$-DP and obtain a utility bound of order $\sqrt{d}/(nε)$ (with $d$ the input dimension), matching the classical lower bound for general convex Lipschitz problems. Our results imply that polylogarithmic width is not only sufficient but also necessary under differential privacy, revealing a qualitative gap between non-private (sufficiency only) and private (necessity also emerges) training regimes. Experiments further illustrate how these theoretical insights can guide practical choices, including network width selection and early stopping.
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
3DGabSplat: 3D Gabor Splatting for Frequency-adaptive Radiance Field Rendering
Aug 07, 2025Recent prominence in 3D Gaussian Splatting (3DGS) has enabled real-time rendering while maintaining high-fidelity novel view synthesis. However, 3DGS resorts to the Gaussian function that is low-pass by nature and is restricted in representing high-frequency details in 3D scenes. Moreover, it causes redundant primitives with degraded training and rendering efficiency and excessive memory overhead. To overcome these limitations, we propose 3D Gabor Splatting (3DGabSplat) that leverages a novel 3D Gabor-based primitive with multiple directional 3D frequency responses for radiance field representation supervised by multi-view images. The proposed 3D Gabor-based primitive forms a filter bank incorporating multiple 3D Gabor kernels at different frequencies to enhance flexibility and efficiency in capturing fine 3D details. Furthermore, to achieve novel view rendering, an efficient CUDA-based rasterizer is developed to project the multiple directional 3D frequency components characterized by 3D Gabor-based primitives onto the 2D image plane, and a frequency-adaptive mechanism is presented for adaptive joint optimization of primitives. 3DGabSplat is scalable to be a plug-and-play kernel for seamless integration into existing 3DGS paradigms to enhance both efficiency and quality of novel view synthesis. Extensive experiments demonstrate that 3DGabSplat outperforms 3DGS and its variants using alternative primitives, and achieves state-of-the-art rendering quality across both real-world and synthetic scenes. Remarkably, we achieve up to 1.35 dB PSNR gain over 3DGS with simultaneously reduced number of primitives and memory consumption.
Generalization analysis with deep ReLU networks for metric and similarity learning
May 10, 2024While considerable theoretical progress has been devoted to the study of metric and similarity learning, the generalization mystery is still missing. In this paper, we study the generalization performance of metric and similarity learning by leveraging the specific structure of the true metric (the target function). Specifically, by deriving the explicit form of the true metric for metric and similarity learning with the hinge loss, we construct a structured deep ReLU neural network as an approximation of the true metric, whose approximation ability relies on the network complexity. Here, the network complexity corresponds to the depth, the number of nonzero weights and the computation units of the network. Consider the hypothesis space which consists of the structured deep ReLU networks, we develop the excess generalization error bounds for a metric and similarity learning problem by estimating the approximation error and the estimation error carefully. An optimal excess risk rate is derived by choosing the proper capacity of the constructed hypothesis space. To the best of our knowledge, this is the first-ever-known generalization analysis providing the excess generalization error for metric and similarity learning. In addition, we investigate the properties of the true metric of metric and similarity learning with general losses.
Optimal Estimates for Pairwise Learning with Deep ReLU Networks
May 31, 2023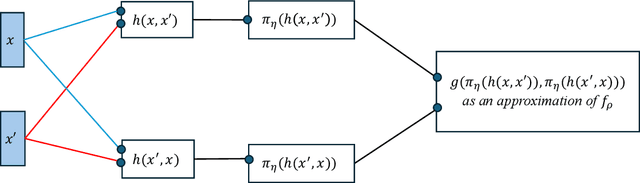
Pairwise learning refers to learning tasks where a loss takes a pair of samples into consideration. In this paper, we study pairwise learning with deep ReLU networks and estimate the excess generalization error. For a general loss satisfying some mild conditions, a sharp bound for the estimation error of order $O((V\log(n) /n)^{1/(2-\beta)})$ is established. In particular, with the pairwise least squares loss, we derive a nearly optimal bound of the excess generalization error which achieves the minimax lower bound up to a logrithmic term when the true predictor satisfies some smoothness regularities.