 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGT-Rain Single Image Deraining Challenge Report
Mar 18, 2024


This report reviews the results of the GT-Rain challenge on single image deraining at the UG2+ workshop at CVPR 2023. The aim of this competition is to study the rainy weather phenomenon in real world scenarios, provide a novel real world rainy image dataset, and to spark innovative ideas that will further the development of single image deraining methods on real images. Submissions were trained on the GT-Rain dataset and evaluated on an extension of the dataset consisting of 15 additional scenes. Scenes in GT-Rain are comprised of real rainy image and ground truth image captured moments after the rain had stopped. 275 participants were registered in the challenge and 55 competed in the final testing phase.
Face-PAST: Facial Pose Awareness and Style Transfer Networks
Jul 18, 2023Facial style transfer has been quite popular among researchers due to the rise of emerging technologies such as eXtended Reality (XR), Metaverse, and Non-Fungible Tokens (NFTs). Furthermore, StyleGAN methods along with transfer-learning strategies have reduced the problem of limited data to some extent. However, most of the StyleGAN methods overfit the styles while adding artifacts to facial images. In this paper, we propose a facial pose awareness and style transfer (Face-PAST) network that preserves facial details and structures while generating high-quality stylized images. Dual StyleGAN inspires our work, but in contrast, our work uses a pre-trained style generation network in an external style pass with a residual modulation block instead of a transform coding block. Furthermore, we use the gated mapping unit and facial structure, identity, and segmentation losses to preserve the facial structure and details. This enables us to train the network with a very limited amount of data while generating high-quality stylized images. Our training process adapts curriculum learning strategy to perform efficient and flexible style mixing in the generative space. We perform extensive experiments to show the superiority of Face-PAST in comparison to existing state-of-the-art methods.
2nd Place Solutions for UG2+ Challenge 2022 -- D$^{3}$Net for Mitigating Atmospheric Turbulence from Images
Aug 25, 2022
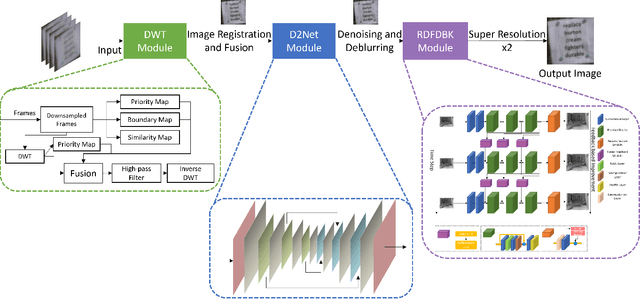

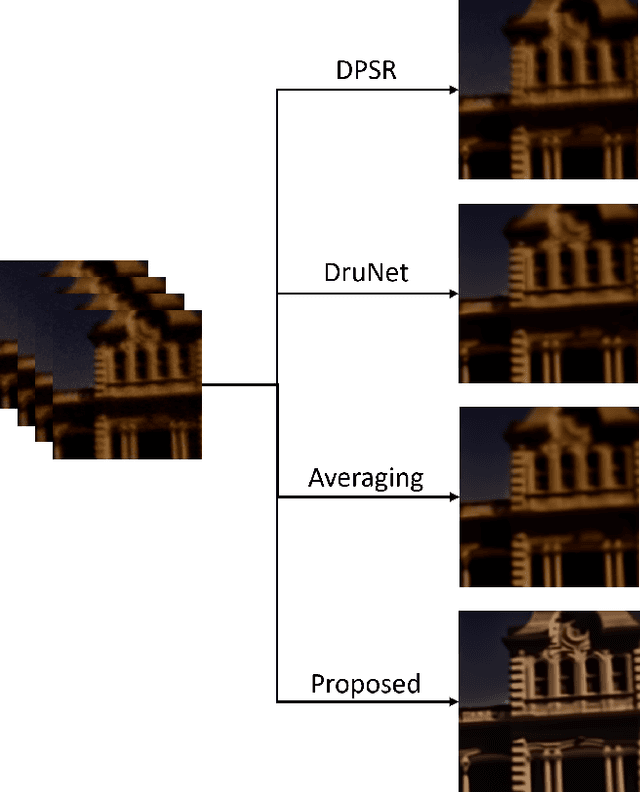
This technical report briefly introduces to the D$^{3}$Net proposed by our team "TUK-IKLAB" for Atmospheric Turbulence Mitigation in $UG2^{+}$ Challenge at CVPR 2022. In the light of test and validation results on textual images to improve text recognition performance and hot-air balloon images for image enhancement, we can say that the proposed method achieves state-of-the-art performance. Furthermore, we also provide a visual comparison with publicly available denoising, deblurring, and frame averaging methods with respect to the proposed work. The proposed method ranked 2nd on the final leader-board of the aforementioned challenge in the testing phase, respectively.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022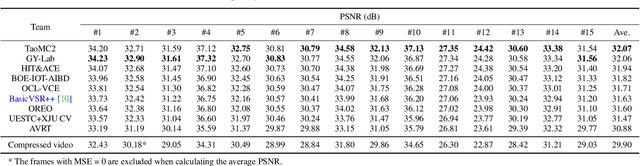
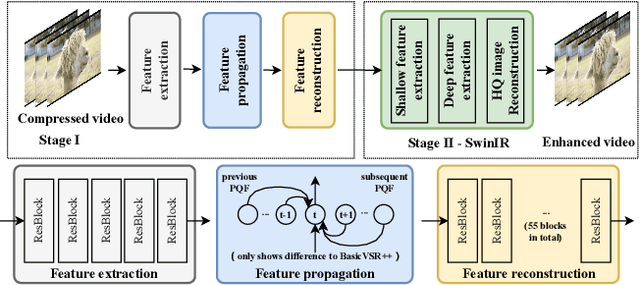
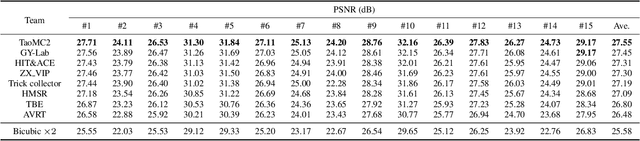

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.