 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Modality Medical Image Synthesis for Improving Liver Segmentation
Mar 02, 2025Deep learning-based computer-aided diagnosis (CAD) of medical images requires large datasets. However, the lack of large publicly available labeled datasets limits the development of deep learning-based CAD systems. Generative Adversarial Networks (GANs), in particular, CycleGAN, can be used to generate new cross-domain images without paired training data. However, most CycleGAN-based synthesis methods lack the potential to overcome alignment and asymmetry between the input and generated data. We propose a two-stage technique for the synthesis of abdominal MRI using cross-modality translation of abdominal CT. We show that the synthetic data can help improve the performance of the liver segmentation network. We increase the number of abdominal MRI images through cross-modality image transformation of unpaired CT images using a CycleGAN inspired deformation invariant network called EssNet. Subsequently, we combine the synthetic MRI images with the original MRI images and use them to improve the accuracy of the U-Net on a liver segmentation task. We train the U-Net on real MRI images and then on real and synthetic MRI images. Consequently, by comparing both scenarios, we achieve an improvement in the performance of U-Net. In summary, the improvement achieved in the Intersection over Union (IoU) is 1.17%. The results show potential to address the data scarcity challenge in medical imaging.
Face-PAST: Facial Pose Awareness and Style Transfer Networks
Jul 18, 2023Facial style transfer has been quite popular among researchers due to the rise of emerging technologies such as eXtended Reality (XR), Metaverse, and Non-Fungible Tokens (NFTs). Furthermore, StyleGAN methods along with transfer-learning strategies have reduced the problem of limited data to some extent. However, most of the StyleGAN methods overfit the styles while adding artifacts to facial images. In this paper, we propose a facial pose awareness and style transfer (Face-PAST) network that preserves facial details and structures while generating high-quality stylized images. Dual StyleGAN inspires our work, but in contrast, our work uses a pre-trained style generation network in an external style pass with a residual modulation block instead of a transform coding block. Furthermore, we use the gated mapping unit and facial structure, identity, and segmentation losses to preserve the facial structure and details. This enables us to train the network with a very limited amount of data while generating high-quality stylized images. Our training process adapts curriculum learning strategy to perform efficient and flexible style mixing in the generative space. We perform extensive experiments to show the superiority of Face-PAST in comparison to existing state-of-the-art methods.
ChatGPT in the Age of Generative AI and Large Language Models: A Concise Survey
Jul 15, 2023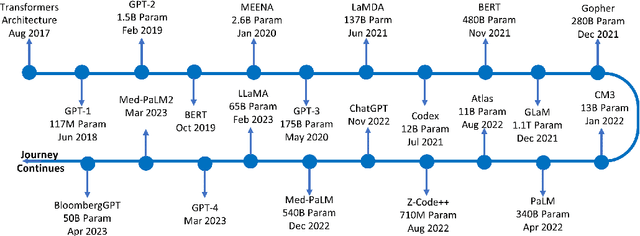
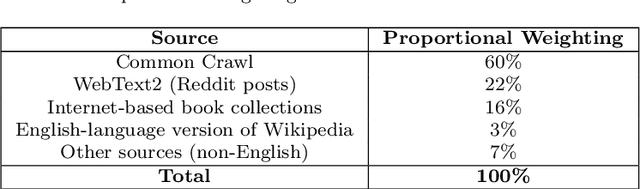
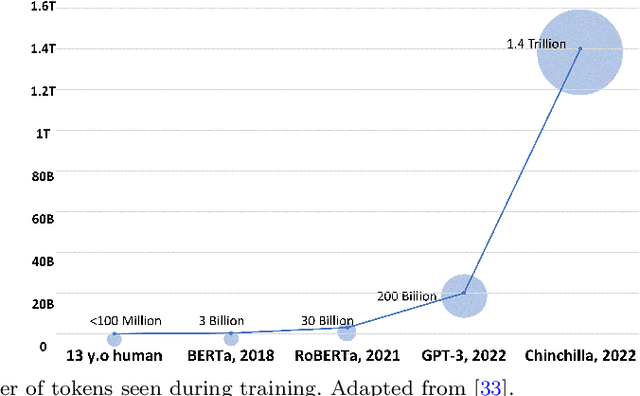
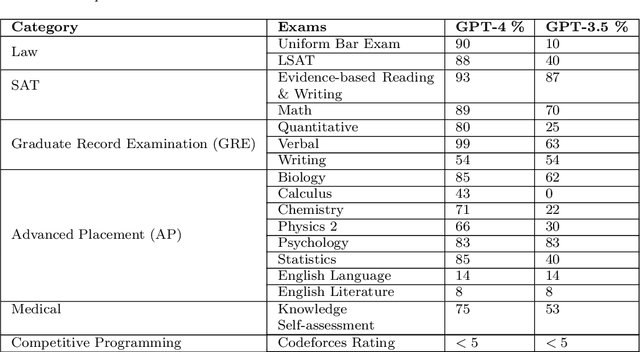
ChatGPT is a large language model (LLM) created by OpenAI that has been carefully trained on a large amount of data. It has revolutionized the field of natural language processing (NLP) and has pushed the boundaries of LLM capabilities. ChatGPT has played a pivotal role in enabling widespread public interaction with generative artificial intelligence (GAI) on a large scale. It has also sparked research interest in developing similar technologies and investigating their applications and implications. In this paper, our primary goal is to provide a concise survey on the current lines of research on ChatGPT and its evolution. We considered both the glass box and black box views of ChatGPT, encompassing the components and foundational elements of the technology, as well as its applications, impacts, and implications. The glass box approach focuses on understanding the inner workings of the technology, and the black box approach embraces it as a complex system, and thus examines its inputs, outputs, and effects. This paves the way for a comprehensive exploration of the technology and provides a road map for further research and experimentation. We also lay out essential foundational literature on LLMs and GAI in general and their connection with ChatGPT. This overview sheds light on existing and missing research lines in the emerging field of LLMs, benefiting both public users and developers. Furthermore, the paper delves into the broad spectrum of applications and significant concerns in fields such as education, research, healthcare, finance, etc.
LTC-GIF: Attracting More Clicks on Feature-length Sports Videos
Jan 22, 2022

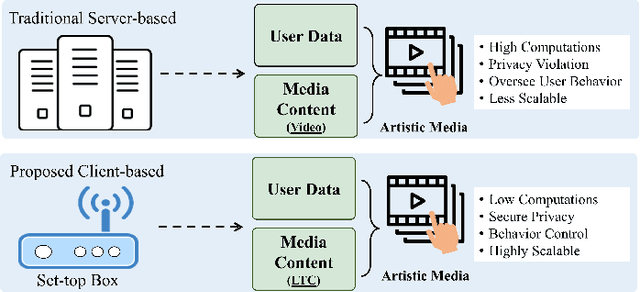
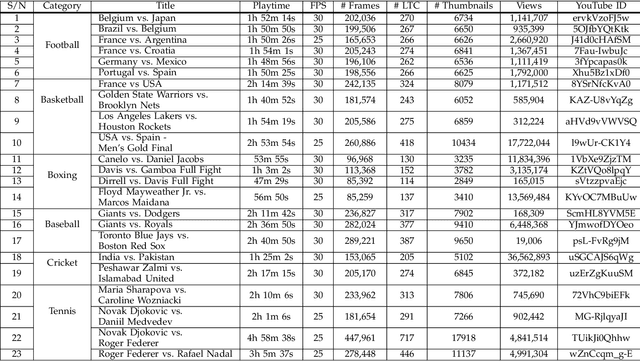
This paper proposes a lightweight method to attract users and increase views of the video by presenting personalized artistic media -- i.e, static thumbnails and animated GIFs. This method analyzes lightweight thumbnail containers (LTC) using computational resources of the client device to recognize personalized events from full-length sports videos. In addition, instead of processing the entire video, small video segments are processed to generate artistic media. This makes the proposed approach more computationally efficient compared to the baseline approaches that create artistic media using the entire video. The proposed method retrieves and uses thumbnail containers and video segments, which reduces the required transmission bandwidth as well as the amount of locally stored data used during artistic media generation. When extensive experiments were conducted on the Nvidia Jetson TX2, the computational complexity of the proposed method was 3.57 times lower than that of the SoA method. In the qualitative assessment, GIFs generated using the proposed method received 1.02 higher overall ratings compared to the SoA method. To the best of our knowledge, this is the first technique that uses LTC to generate artistic media while providing lightweight and high-performance services even on resource-constrained devices.
LTC-SUM: Lightweight Client-driven Personalized Video Summarization Framework Using 2D CNN
Jan 22, 2022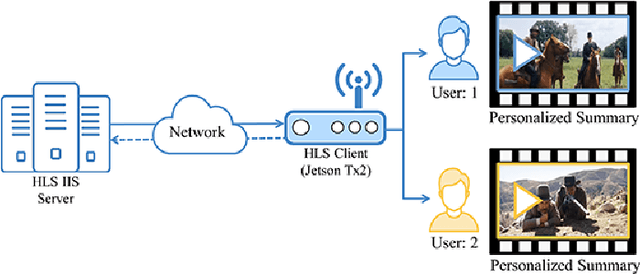
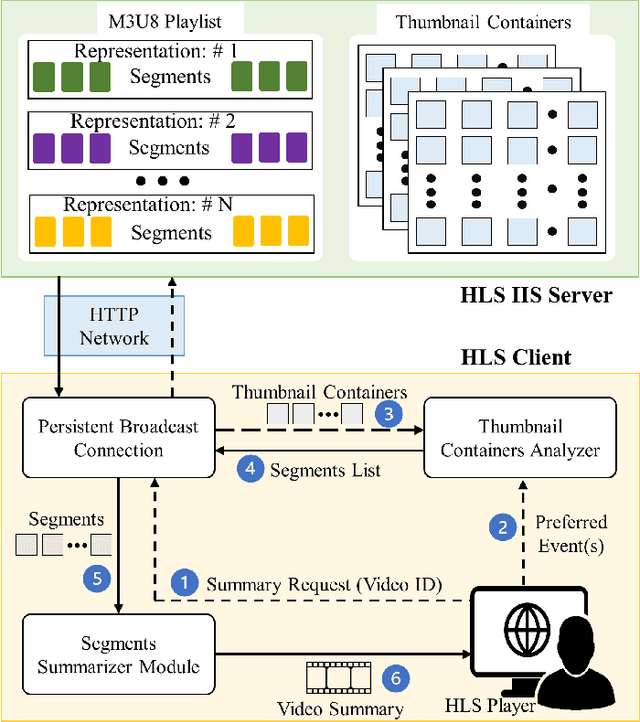
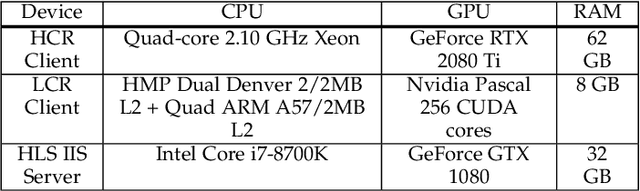
This paper proposes a novel lightweight thumbnail container-based summarization (LTC-SUM) framework for full feature-length videos. This framework generates a personalized keyshot summary for concurrent users by using the computational resource of the end-user device. State-of-the-art methods that acquire and process entire video data to generate video summaries are highly computationally intensive. In this regard, the proposed LTC-SUM method uses lightweight thumbnails to handle the complex process of detecting events. This significantly reduces computational complexity and improves communication and storage efficiency by resolving computational and privacy bottlenecks in resource-constrained end-user devices. These improvements were achieved by designing a lightweight 2D CNN model to extract features from thumbnails, which helped select and retrieve only a handful of specific segments. Extensive quantitative experiments on a set of full 18 feature-length videos (approximately 32.9 h in duration) showed that the proposed method is significantly computationally efficient than state-of-the-art methods on the same end-user device configurations. Joint qualitative assessments of the results of 56 participants showed that participants gave higher ratings to the summaries generated using the proposed method. To the best of our knowledge, this is the first attempt in designing a fully client-driven personalized keyshot video summarization framework using thumbnail containers for feature-length videos.
Urdu text in natural scene images: a new dataset and preliminary text detection
Sep 16, 2021


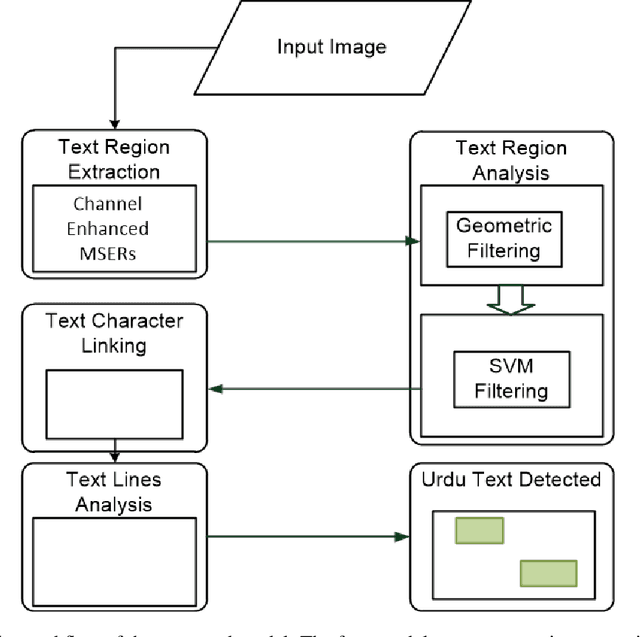
Text detection in natural scene images for content analysis is an interesting task. The research community has seen some great developments for English/Mandarin text detection. However, Urdu text extraction in natural scene images is a task not well addressed. In this work, firstly, a new dataset is introduced for Urdu text in natural scene images. The dataset comprises of 500 standalone images acquired from real scenes. Secondly, the channel enhanced Maximally Stable Extremal Region (MSER) method is applied to extract Urdu text regions as candidates in an image. Two-stage filtering mechanism is applied to eliminate non-candidate regions. In the first stage, text and noise are classified based on their geometric properties. In the second stage, a support vector machine classifier is trained to discard non-text candidate regions. After this, text candidate regions are linked using centroid-based vertical and horizontal distances. Text lines are further analyzed by a different classifier based on HOG features to remove non-text regions. Extensive experimentation is performed on the locally developed dataset to evaluate the performance. The experimental results show good performance on test set images. The dataset will be made available for research use. To the best of our knowledge, the work is the first of its kind for the Urdu language and would provide a good dataset for free research use and serve as a baseline performance on the task of Urdu text extraction.
EdgeNet: A novel approach for Arabic numeral classification
Jul 30, 2019
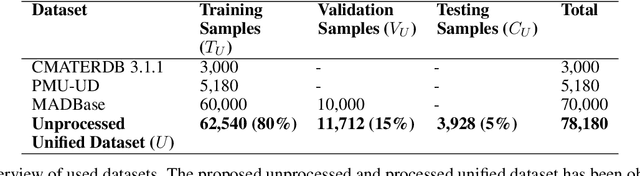


Despite the importance of handwritten numeral classification, a robust and effective method for a widely used language like Arabic is still due. This study focuses to overcome two major limitations of existing works: data diversity and effective learning method. Hence, the existing Arabic numeral datasets have been merged into a single dataset and augmented to introduce data diversity. Moreover, a novel deep model has been proposed to exploit diverse data samples of unified dataset. The proposed deep model utilizes the low-level edge features by propagating them through residual connection. To make a fair comparison with the proposed model, the existing works have been studied under the unified dataset. The comparison experiments illustrate that the unified dataset accelerates the performance of the existing works. Moreover, the proposed model outperforms the existing state-of-the-art Arabic handwritten numeral classification methods and obtain an accuracy of 99.59% in the validation phase. Apart from that, different state-of-the-art classification models have studied with the same dataset to reveal their feasibility for the Arabic numeral classification. Code available at http://github.com/sharif-apu/EdgeNet.