 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Modality Medical Image Synthesis for Improving Liver Segmentation
Mar 02, 2025Deep learning-based computer-aided diagnosis (CAD) of medical images requires large datasets. However, the lack of large publicly available labeled datasets limits the development of deep learning-based CAD systems. Generative Adversarial Networks (GANs), in particular, CycleGAN, can be used to generate new cross-domain images without paired training data. However, most CycleGAN-based synthesis methods lack the potential to overcome alignment and asymmetry between the input and generated data. We propose a two-stage technique for the synthesis of abdominal MRI using cross-modality translation of abdominal CT. We show that the synthetic data can help improve the performance of the liver segmentation network. We increase the number of abdominal MRI images through cross-modality image transformation of unpaired CT images using a CycleGAN inspired deformation invariant network called EssNet. Subsequently, we combine the synthetic MRI images with the original MRI images and use them to improve the accuracy of the U-Net on a liver segmentation task. We train the U-Net on real MRI images and then on real and synthetic MRI images. Consequently, by comparing both scenarios, we achieve an improvement in the performance of U-Net. In summary, the improvement achieved in the Intersection over Union (IoU) is 1.17%. The results show potential to address the data scarcity challenge in medical imaging.
R2U++: A Multiscale Recurrent Residual U-Net with Dense Skip Connections for Medical Image Segmentation
Jun 03, 2022U-Net is a widely adopted neural network in the domain of medical image segmentation. Despite its quick embracement by the medical imaging community, its performance suffers on complicated datasets. The problem can be ascribed to its simple feature extracting blocks: encoder/decoder, and the semantic gap between encoder and decoder. Variants of U-Net (such as R2U-Net) have been proposed to address the problem of simple feature extracting blocks by making the network deeper, but it does not deal with the semantic gap problem. On the other hand, another variant UNET++ deals with the semantic gap problem by introducing dense skip connections but has simple feature extraction blocks. To overcome these issues, we propose a new U-Net based medical image segmentation architecture R2U++. In the proposed architecture, the adapted changes from vanilla U-Net are: (1) the plain convolutional backbone is replaced by a deeper recurrent residual convolution block. The increased field of view with these blocks aids in extracting crucial features for segmentation which is proven by improvement in the overall performance of the network. (2) The semantic gap between encoder and decoder is reduced by dense skip pathways. These pathways accumulate features coming from multiple scales and apply concatenation accordingly. The modified architecture has embedded multi-depth models, and an ensemble of outputs taken from varying depths improves the performance on foreground objects appearing at various scales in the images. The performance of R2U++ is evaluated on four distinct medical imaging modalities: electron microscopy (EM), X-rays, fundus, and computed tomography (CT). The average gain achieved in IoU score is 1.5+-0.37% and in dice score is 0.9+-0.33% over UNET++, whereas, 4.21+-2.72 in IoU and 3.47+-1.89 in dice score over R2U-Net across different medical imaging segmentation datasets.
Segmentation of Lungs in Chest X-Ray Image Using Generative Adversarial Networks
Sep 12, 2020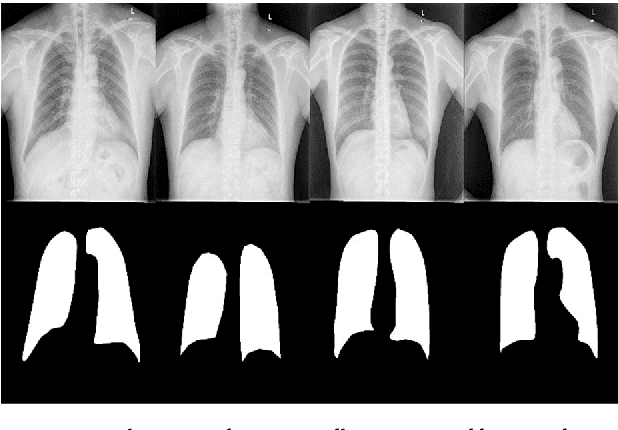

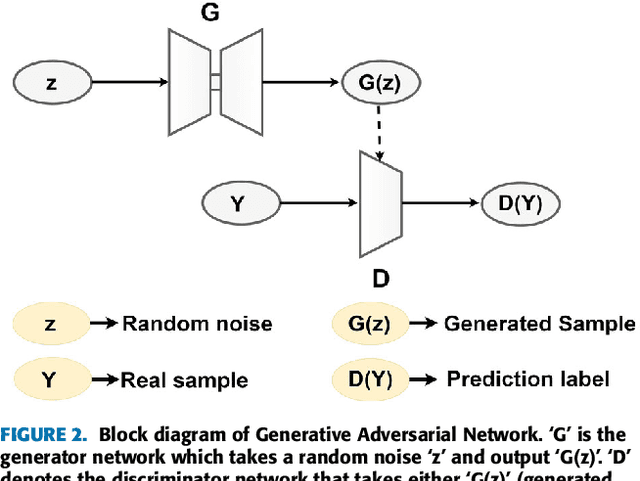
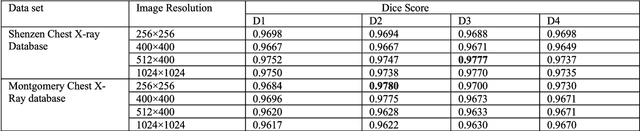
Chest X-ray (CXR) is a low-cost medical imaging technique. It is a common procedure for the identification of many respiratory diseases compared to MRI, CT, and PET scans. This paper presents the use of generative adversarial networks (GAN) to perform the task of lung segmentation on a given CXR. GANs are popular to generate realistic data by learning the mapping from one domain to another. In our work, the generator of the GAN is trained to generate a segmented mask of a given input CXR. The discriminator distinguishes between a ground truth and the generated mask, and updates the generator through the adversarial loss measure. The objective is to generate masks for the input CXR, which are as realistic as possible compared to the ground truth masks. The model is trained and evaluated using four different discriminators referred to as D1, D2, D3, and D4, respectively. Experimental results on three different CXR datasets reveal that the proposed model is able to achieve a dice-score of 0.9740, and IOU score of 0.943, which are better than other reported state-of-the art results.
* Volume 8, August 2020, Pages 153535 - 153545