 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTC-SUM: Lightweight Client-driven Personalized Video Summarization Framework Using 2D CNN
Jan 22, 2022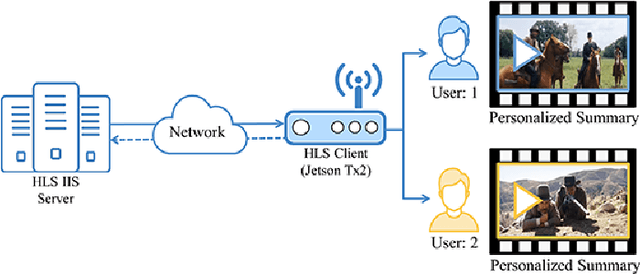
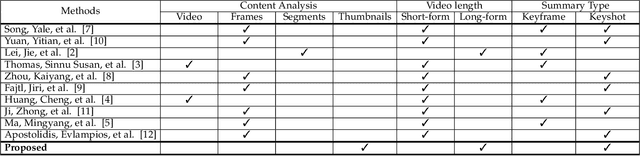
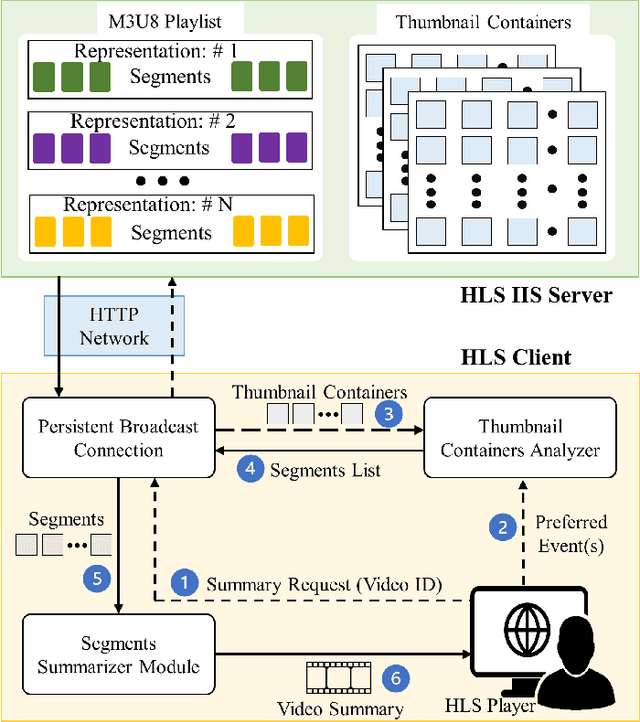
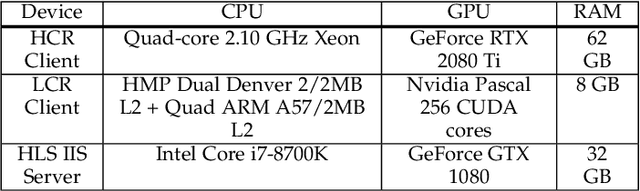
This paper proposes a novel lightweight thumbnail container-based summarization (LTC-SUM) framework for full feature-length videos. This framework generates a personalized keyshot summary for concurrent users by using the computational resource of the end-user device. State-of-the-art methods that acquire and process entire video data to generate video summaries are highly computationally intensive. In this regard, the proposed LTC-SUM method uses lightweight thumbnails to handle the complex process of detecting events. This significantly reduces computational complexity and improves communication and storage efficiency by resolving computational and privacy bottlenecks in resource-constrained end-user devices. These improvements were achieved by designing a lightweight 2D CNN model to extract features from thumbnails, which helped select and retrieve only a handful of specific segments. Extensive quantitative experiments on a set of full 18 feature-length videos (approximately 32.9 h in duration) showed that the proposed method is significantly computationally efficient than state-of-the-art methods on the same end-user device configurations. Joint qualitative assessments of the results of 56 participants showed that participants gave higher ratings to the summaries generated using the proposed method. To the best of our knowledge, this is the first attempt in designing a fully client-driven personalized keyshot video summarization framework using thumbnail containers for feature-length videos.
A Personalized Preference Learning Framework for Caching in Mobile Networks
Apr 15, 2019



This paper comprehensively studies a content-centric mobile network based on a preference learning framework, where each mobile user is equipped with finite-size cache. We consider a practical scenario where each user requests a content file according to its own preferences, which is motivated by the existence of heterogeneity in file preferences among different users. Under our model, we consider a single-hop-based device-to-device (D2D) content delivery protocol and characterize the average hit ratio for the following two file preference cases: the personalized file preferences and the common file preferences. By assuming that the model parameters such as user activity levels, user file preferences, and file popularity are unknown and thus need to be inferred, we present a collaborative filtering (CF)-based approach to learning these parameters. Then, we reformulate the hit ratio maximization problems into a submodular function maximization and propose several greedy algorithms to efficiently solve the cache allocation problems. We analyze the computational complexity of each algorithm along with the corresponding level of the approximation that it can achieve compared to the optimal solution. Using a real-world dataset, we demonstrate that the proposed framework employing the personalized file preferences brings substantial gains over its counterpart for various system parameters.