 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrdu text in natural scene images: a new dataset and preliminary text detection
Paper and Code
Sep 16, 2021


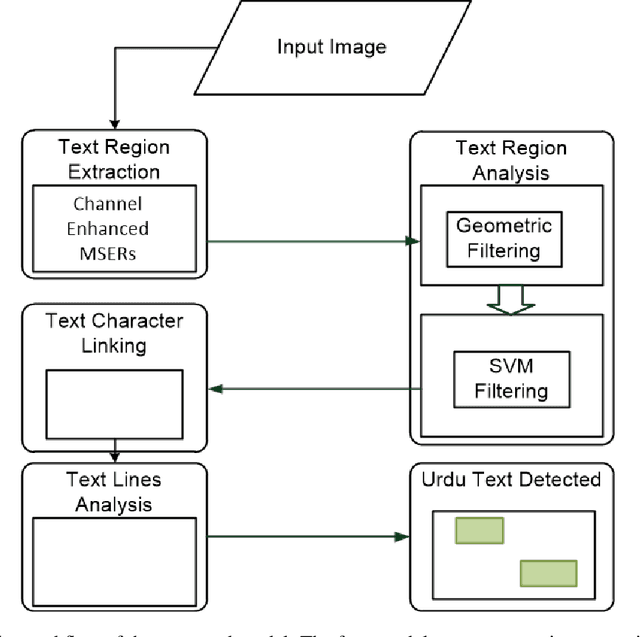
Text detection in natural scene images for content analysis is an interesting task. The research community has seen some great developments for English/Mandarin text detection. However, Urdu text extraction in natural scene images is a task not well addressed. In this work, firstly, a new dataset is introduced for Urdu text in natural scene images. The dataset comprises of 500 standalone images acquired from real scenes. Secondly, the channel enhanced Maximally Stable Extremal Region (MSER) method is applied to extract Urdu text regions as candidates in an image. Two-stage filtering mechanism is applied to eliminate non-candidate regions. In the first stage, text and noise are classified based on their geometric properties. In the second stage, a support vector machine classifier is trained to discard non-text candidate regions. After this, text candidate regions are linked using centroid-based vertical and horizontal distances. Text lines are further analyzed by a different classifier based on HOG features to remove non-text regions. Extensive experimentation is performed on the locally developed dataset to evaluate the performance. The experimental results show good performance on test set images. The dataset will be made available for research use. To the best of our knowledge, the work is the first of its kind for the Urdu language and would provide a good dataset for free research use and serve as a baseline performance on the task of Urdu text extraction.