 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoder-Free Distillation for Quantized Image Restoration
Mar 10, 2026Quantization-Aware Training (QAT), combined with Knowledge Distillation (KD), holds immense promise for compressing models for edge deployment. However, joint optimization for precision-sensitive image restoration (IR) to recover visual quality from degraded images remains largely underexplored. Directly adapting QAT-KD to low-level vision reveals three critical bottlenecks: teacher-student capacity mismatch, spatial error amplification during decoder distillation, and an optimization "tug-of-war" between reconstruction and distillation losses caused by quantization noise. To tackle these, we introduce Quantization-aware Distilled Restoration (QDR), a framework for edge-deployed IR. QDR eliminates capacity mismatch via FP32 self-distillation and prevents error amplification through Decoder-Free Distillation (DFD), which corrects quantization errors strictly at the network bottleneck. To stabilize the optimization tug-of-war, we propose a Learnable Magnitude Reweighting (LMR) that dynamically balances competing gradients. Finally, we design an Edge-Friendly Model (EFM) featuring a lightweight Learnable Degradation Gating (LDG) to dynamically modulate spatial degradation localization. Extensive experiments across four IR tasks demonstrate that our Int8 model recovers 96.5% of FP32 performance, achieves 442 frames per second (FPS) on an NVIDIA Jetson Orin, and boosts downstream object detection by 16.3 mAP
AIM 2022 Challenge on Instagram Filter Removal: Methods and Results
Oct 17, 2022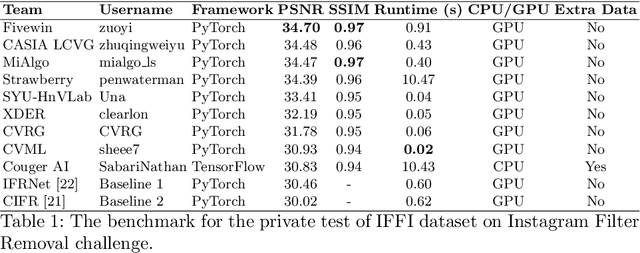

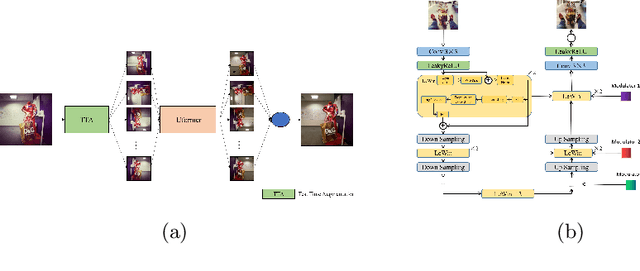
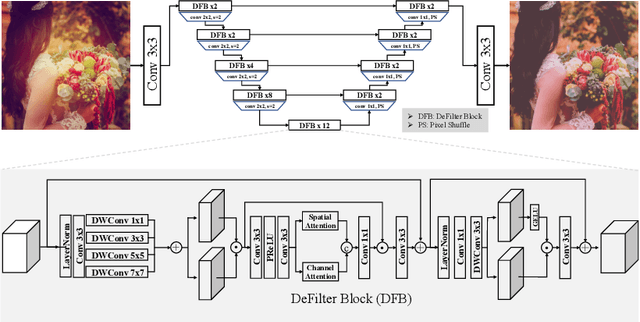
This paper introduces the methods and the results of AIM 2022 challenge on Instagram Filter Removal. Social media filters transform the images by consecutive non-linear operations, and the feature maps of the original content may be interpolated into a different domain. This reduces the overall performance of the recent deep learning strategies. The main goal of this challenge is to produce realistic and visually plausible images where the impact of the filters applied is mitigated while preserving the content. The proposed solutions are ranked in terms of the PSNR value with respect to the original images. There are two prior studies on this task as the baseline, and a total of 9 teams have competed in the final phase of the challenge. The comparison of qualitative results of the proposed solutions and the benchmark for the challenge are presented in this report.
EdgeNet: A novel approach for Arabic numeral classification
Jul 30, 2019
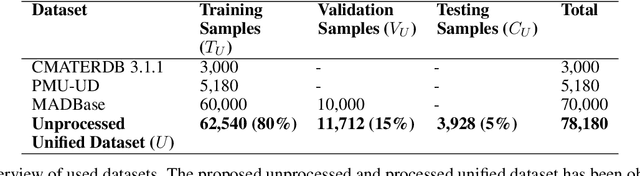


Despite the importance of handwritten numeral classification, a robust and effective method for a widely used language like Arabic is still due. This study focuses to overcome two major limitations of existing works: data diversity and effective learning method. Hence, the existing Arabic numeral datasets have been merged into a single dataset and augmented to introduce data diversity. Moreover, a novel deep model has been proposed to exploit diverse data samples of unified dataset. The proposed deep model utilizes the low-level edge features by propagating them through residual connection. To make a fair comparison with the proposed model, the existing works have been studied under the unified dataset. The comparison experiments illustrate that the unified dataset accelerates the performance of the existing works. Moreover, the proposed model outperforms the existing state-of-the-art Arabic handwritten numeral classification methods and obtain an accuracy of 99.59% in the validation phase. Apart from that, different state-of-the-art classification models have studied with the same dataset to reveal their feasibility for the Arabic numeral classification. Code available at http://github.com/sharif-apu/EdgeNet.