 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024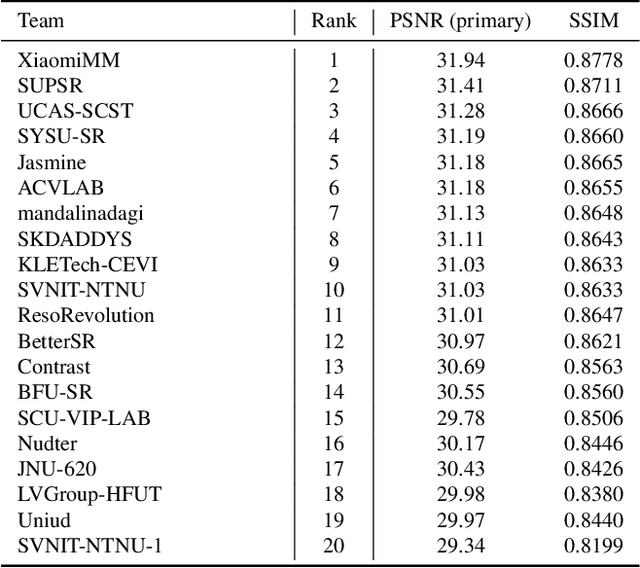
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
The Second Monocular Depth Estimation Challenge
Apr 26, 2023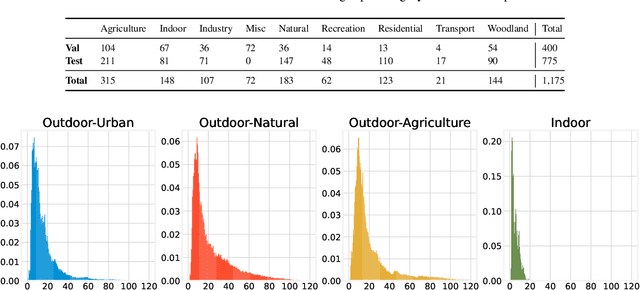
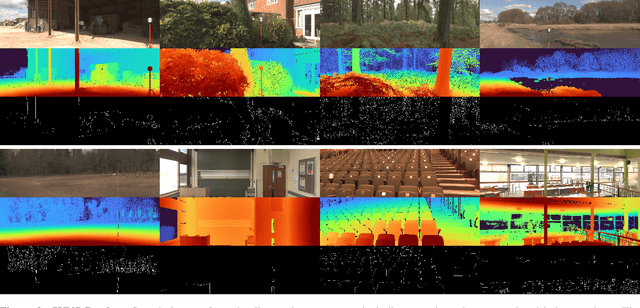
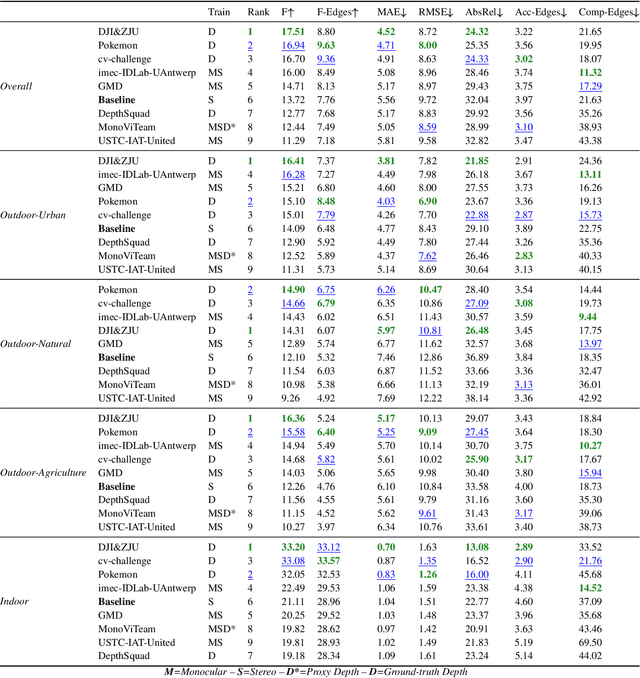
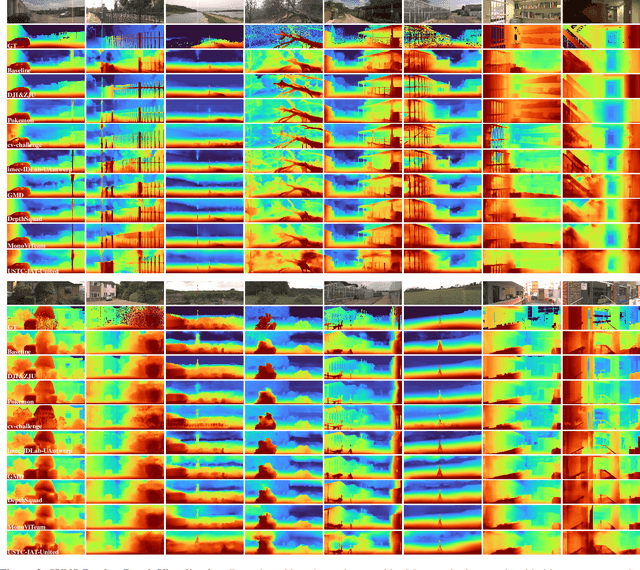
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
EdgeNet: A novel approach for Arabic numeral classification
Jul 30, 2019
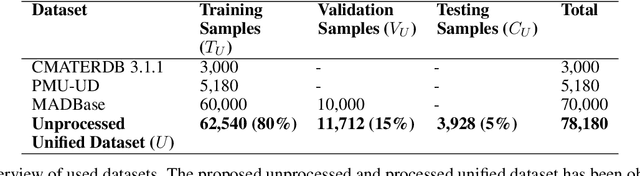


Despite the importance of handwritten numeral classification, a robust and effective method for a widely used language like Arabic is still due. This study focuses to overcome two major limitations of existing works: data diversity and effective learning method. Hence, the existing Arabic numeral datasets have been merged into a single dataset and augmented to introduce data diversity. Moreover, a novel deep model has been proposed to exploit diverse data samples of unified dataset. The proposed deep model utilizes the low-level edge features by propagating them through residual connection. To make a fair comparison with the proposed model, the existing works have been studied under the unified dataset. The comparison experiments illustrate that the unified dataset accelerates the performance of the existing works. Moreover, the proposed model outperforms the existing state-of-the-art Arabic handwritten numeral classification methods and obtain an accuracy of 99.59% in the validation phase. Apart from that, different state-of-the-art classification models have studied with the same dataset to reveal their feasibility for the Arabic numeral classification. Code available at http://github.com/sharif-apu/EdgeNet.