 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealth AI Developer Foundations
Nov 26, 2024



Robust medical Machine Learning (ML) models have the potential to revolutionize healthcare by accelerating clinical research, improving workflows and outcomes, and producing novel insights or capabilities. Developing such ML models from scratch is cost prohibitive and requires substantial compute, data, and time (e.g., expert labeling). To address these challenges, we introduce Health AI Developer Foundations (HAI-DEF), a suite of pre-trained, domain-specific foundation models, tools, and recipes to accelerate building ML for health applications. The models cover various modalities and domains, including radiology (X-rays and computed tomography), histopathology, dermatological imaging, and audio. These models provide domain specific embeddings that facilitate AI development with less labeled data, shorter training times, and reduced computational costs compared to traditional approaches. In addition, we utilize a common interface and style across these models, and prioritize usability to enable developers to integrate HAI-DEF efficiently. We present model evaluations across various tasks and conclude with a discussion of their application and evaluation, covering the importance of ensuring efficacy, fairness, and equity. Finally, while HAI-DEF and specifically the foundation models lower the barrier to entry for ML in healthcare, we emphasize the importance of validation with problem- and population-specific data for each desired usage setting. This technical report will be updated over time as more modalities and features are added.
PathAlign: A vision-language model for whole slide images in histopathology
Jun 27, 2024Microscopic interpretation of histopathology images underlies many important diagnostic and treatment decisions. While advances in vision-language modeling raise new opportunities for analysis of such images, the gigapixel-scale size of whole slide images (WSIs) introduces unique challenges. Additionally, pathology reports simultaneously highlight key findings from small regions while also aggregating interpretation across multiple slides, often making it difficult to create robust image-text pairs. As such, pathology reports remain a largely untapped source of supervision in computational pathology, with most efforts relying on region-of-interest annotations or self-supervision at the patch-level. In this work, we develop a vision-language model based on the BLIP-2 framework using WSIs paired with curated text from pathology reports. This enables applications utilizing a shared image-text embedding space, such as text or image retrieval for finding cases of interest, as well as integration of the WSI encoder with a frozen large language model (LLM) for WSI-based generative text capabilities such as report generation or AI-in-the-loop interactions. We utilize a de-identified dataset of over 350,000 WSIs and diagnostic text pairs, spanning a wide range of diagnoses, procedure types, and tissue types. We present pathologist evaluation of text generation and text retrieval using WSI embeddings, as well as results for WSI classification and workflow prioritization (slide-level triaging). Model-generated text for WSIs was rated by pathologists as accurate, without clinically significant error or omission, for 78% of WSIs on average. This work demonstrates exciting potential capabilities for language-aligned WSI embeddings.
Domain-specific optimization and diverse evaluation of self-supervised models for histopathology
Oct 20, 2023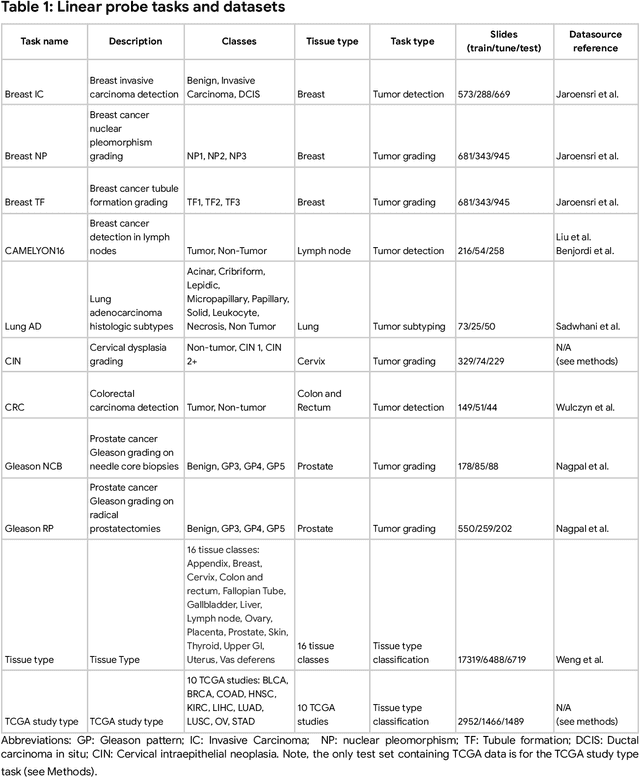
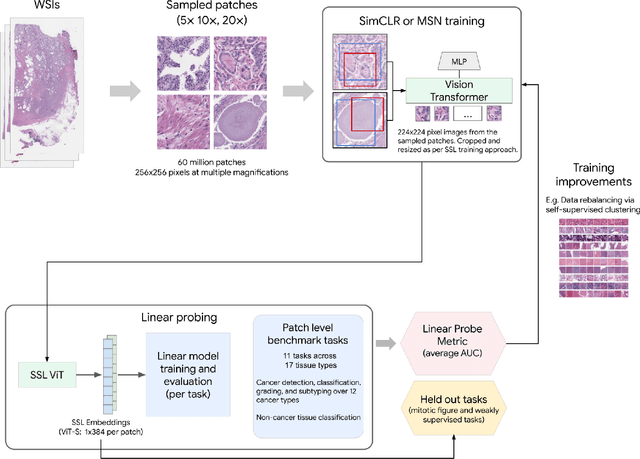
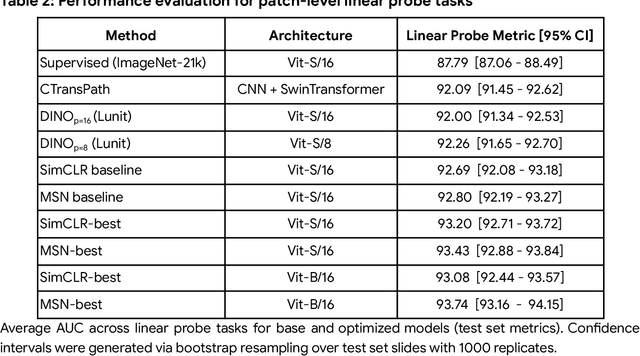
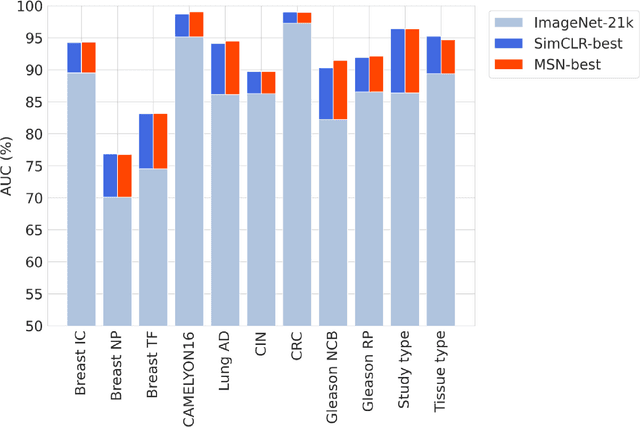
Task-specific deep learning models in histopathology offer promising opportunities for improving diagnosis, clinical research, and precision medicine. However, development of such models is often limited by availability of high-quality data. Foundation models in histopathology that learn general representations across a wide range of tissue types, diagnoses, and magnifications offer the potential to reduce the data, compute, and technical expertise necessary to develop task-specific deep learning models with the required level of model performance. In this work, we describe the development and evaluation of foundation models for histopathology via self-supervised learning (SSL). We first establish a diverse set of benchmark tasks involving 17 unique tissue types and 12 unique cancer types and spanning different optimal magnifications and task types. Next, we use this benchmark to explore and evaluate histopathology-specific SSL methods followed by further evaluation on held out patch-level and weakly supervised tasks. We found that standard SSL methods thoughtfully applied to histopathology images are performant across our benchmark tasks and that domain-specific methodological improvements can further increase performance. Our findings reinforce the value of using domain-specific SSL methods in pathology, and establish a set of high quality foundation models to enable further research across diverse applications.
Predicting Prostate Cancer-Specific Mortality with A.I.-based Gleason Grading
Nov 25, 2020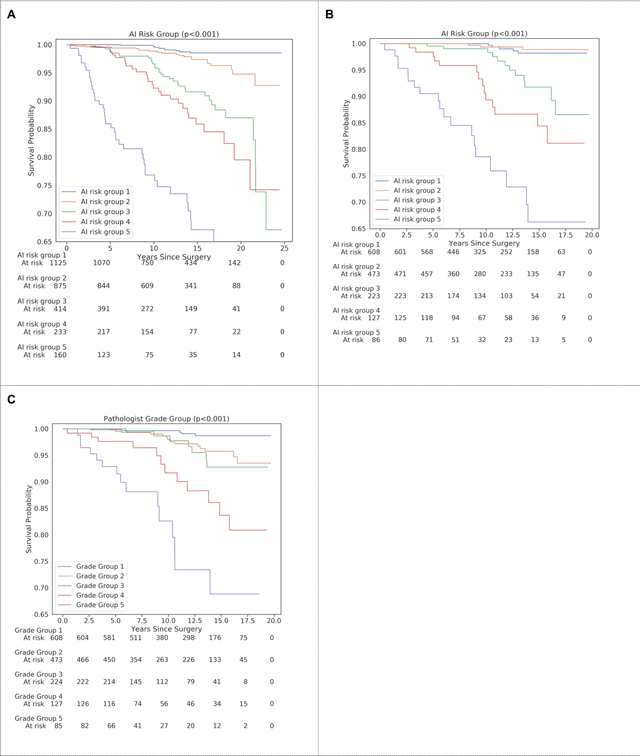
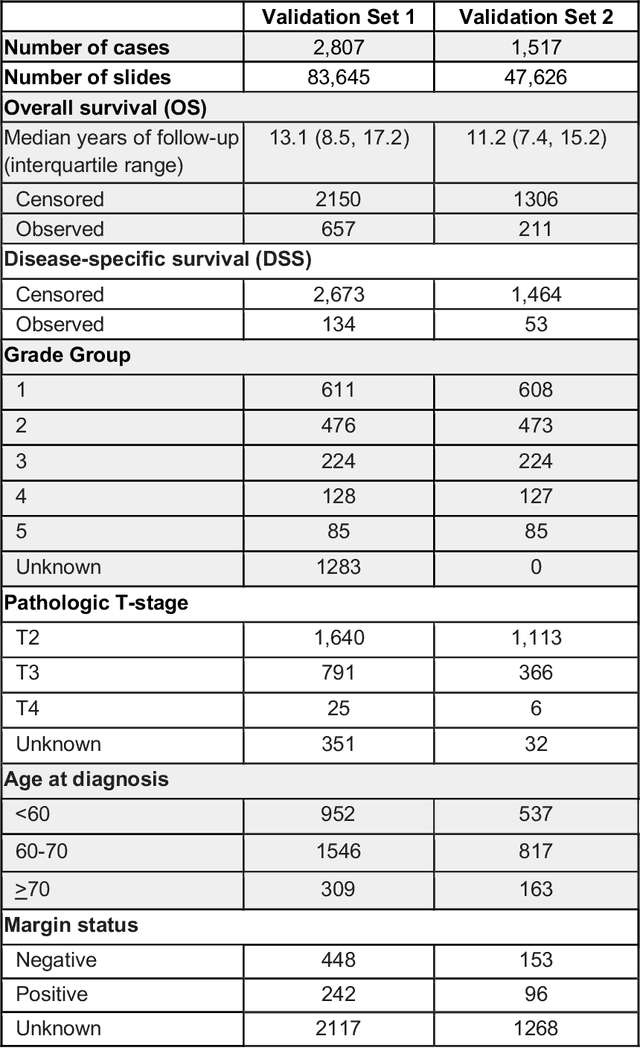
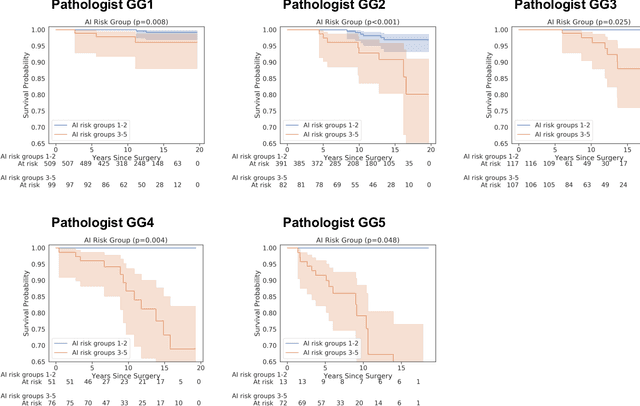
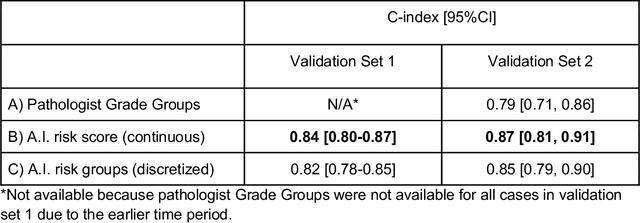
Gleason grading of prostate cancer is an important prognostic factor but suffers from poor reproducibility, particularly among non-subspecialist pathologists. Although artificial intelligence (A.I.) tools have demonstrated Gleason grading on-par with expert pathologists, it remains an open question whether A.I. grading translates to better prognostication. In this study, we developed a system to predict prostate-cancer specific mortality via A.I.-based Gleason grading and subsequently evaluated its ability to risk-stratify patients on an independent retrospective cohort of 2,807 prostatectomy cases from a single European center with 5-25 years of follow-up (median: 13, interquartile range 9-17). The A.I.'s risk scores produced a C-index of 0.84 (95%CI 0.80-0.87) for prostate cancer-specific mortality. Upon discretizing these risk scores into risk groups analogous to pathologist Grade Groups (GG), the A.I. had a C-index of 0.82 (95%CI 0.78-0.85). On the subset of cases with a GG in the original pathology report (n=1,517), the A.I.'s C-indices were 0.87 and 0.85 for continuous and discrete grading, respectively, compared to 0.79 (95%CI 0.71-0.86) for GG obtained from the reports. These represent improvements of 0.08 (95%CI 0.01-0.15) and 0.07 (95%CI 0.00-0.14) respectively. Our results suggest that A.I.-based Gleason grading can lead to effective risk-stratification and warrants further evaluation for improving disease management.
Interpretable Survival Prediction for Colorectal Cancer using Deep Learning
Nov 17, 2020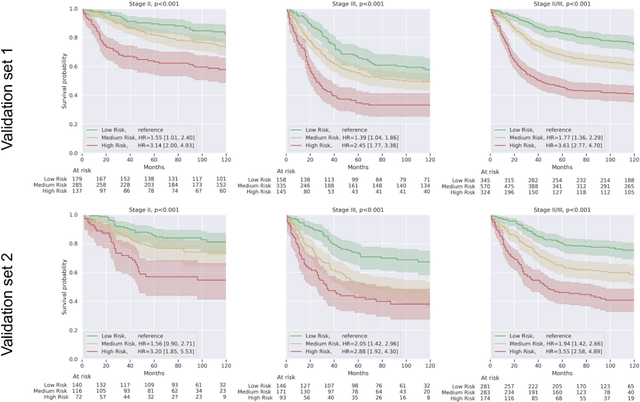
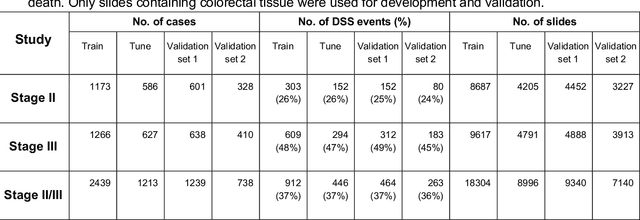
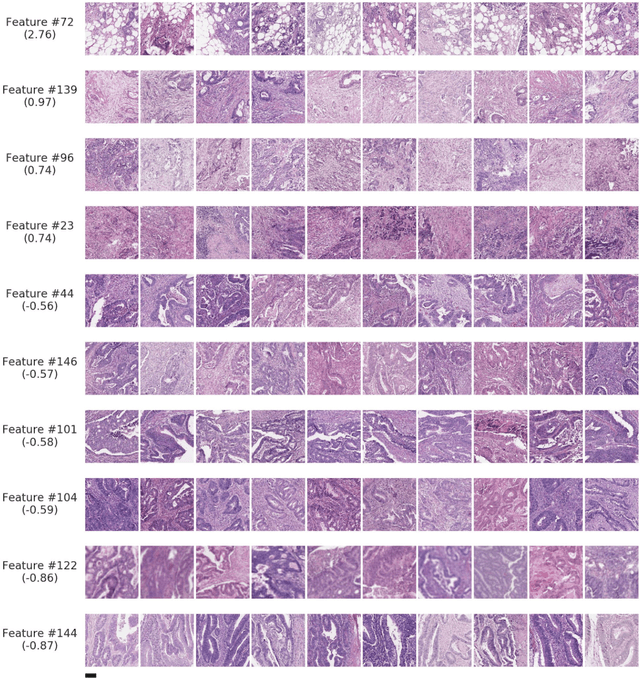
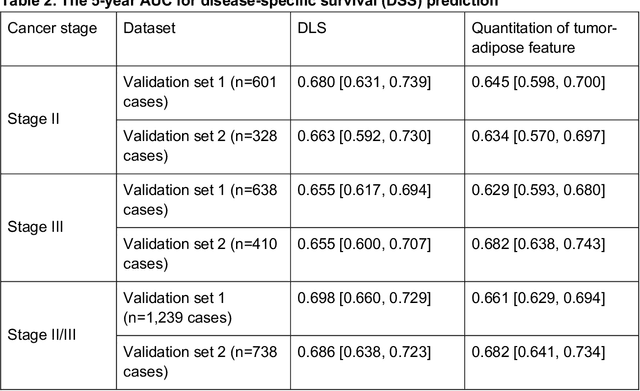
Deriving interpretable prognostic features from deep-learning-based prognostic histopathology models remains a challenge. In this study, we developed a deep learning system (DLS) for predicting disease specific survival for stage II and III colorectal cancer using 3,652 cases (27,300 slides). When evaluated on two validation datasets containing 1,239 cases (9,340 slides) and 738 cases (7,140 slides) respectively, the DLS achieved a 5-year disease-specific survival AUC of 0.70 (95%CI 0.66-0.73) and 0.69 (95%CI 0.64-0.72), and added significant predictive value to a set of 9 clinicopathologic features. To interpret the DLS, we explored the ability of different human-interpretable features to explain the variance in DLS scores. We observed that clinicopathologic features such as T-category, N-category, and grade explained a small fraction of the variance in DLS scores (R2=18% in both validation sets). Next, we generated human-interpretable histologic features by clustering embeddings from a deep-learning based image-similarity model and showed that they explain the majority of the variance (R2 of 73% to 80%). Furthermore, the clustering-derived feature most strongly associated with high DLS scores was also highly prognostic in isolation. With a distinct visual appearance (poorly differentiated tumor cell clusters adjacent to adipose tissue), this feature was identified by annotators with 87.0-95.5% accuracy. Our approach can be used to explain predictions from a prognostic deep learning model and uncover potentially-novel prognostic features that can be reliably identified by people for future validation studies.
Deep learning-based survival prediction for multiple cancer types using histopathology images
Dec 16, 2019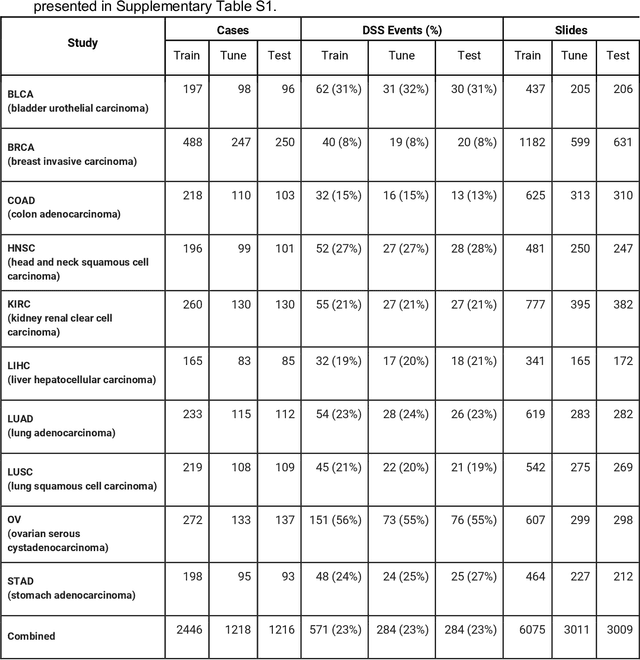
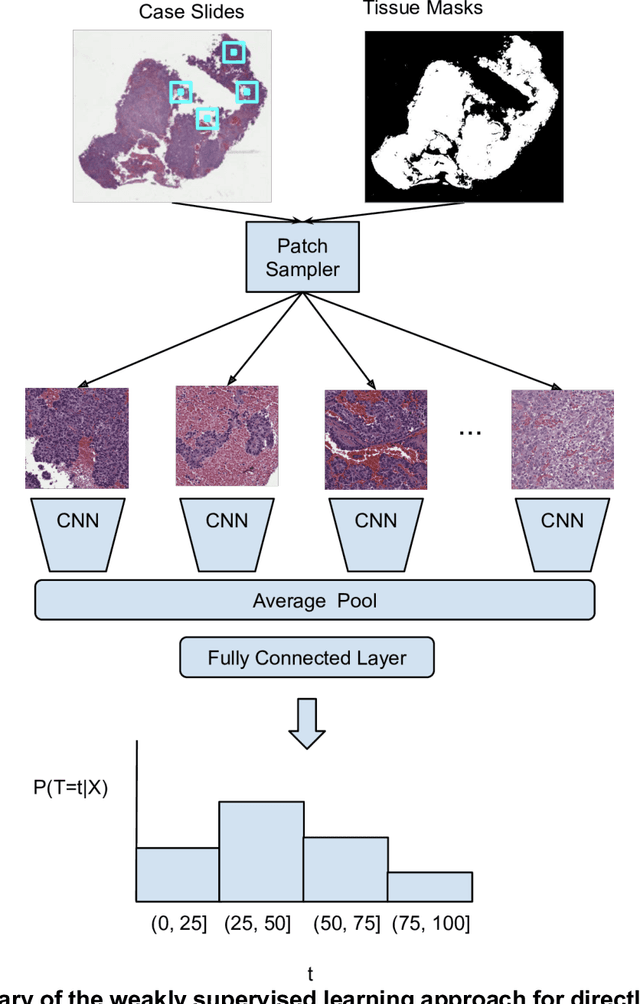
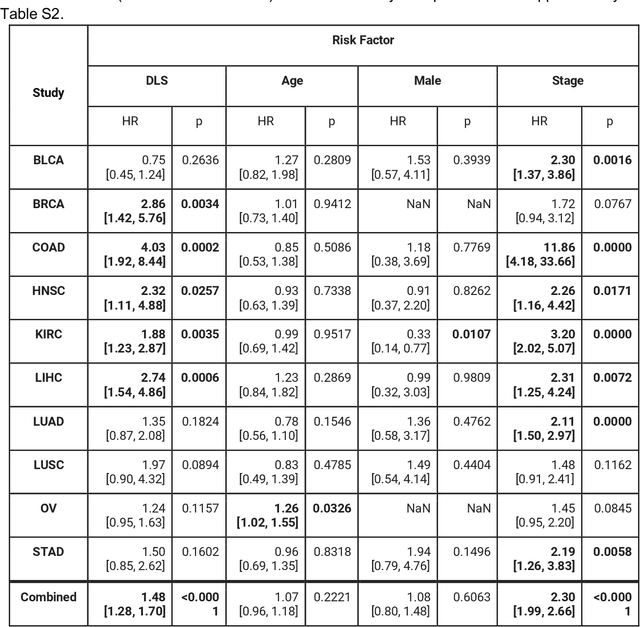
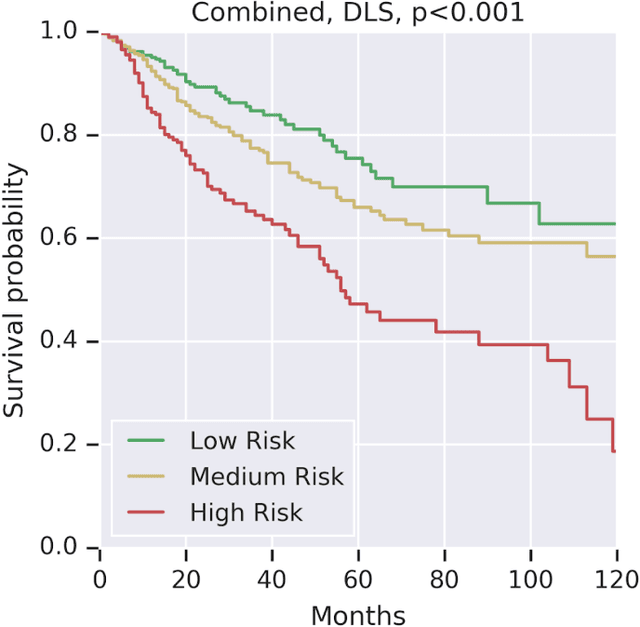
Prognostic information at diagnosis has important implications for cancer treatment and monitoring. Although cancer staging, histopathological assessment, molecular features, and clinical variables can provide useful prognostic insights, improving risk stratification remains an active research area. We developed a deep learning system (DLS) to predict disease specific survival across 10 cancer types from The Cancer Genome Atlas (TCGA). We used a weakly-supervised approach without pixel-level annotations, and tested three different survival loss functions. The DLS was developed using 9,086 slides from 3,664 cases and evaluated using 3,009 slides from 1,216 cases. In multivariable Cox regression analysis of the combined cohort including all 10 cancers, the DLS was significantly associated with disease specific survival (hazard ratio of 1.58, 95% CI 1.28-1.70, p<0.0001) after adjusting for cancer type, stage, age, and sex. In a per-cancer adjusted subanalysis, the DLS remained a significant predictor of survival in 5 of 10 cancer types. Compared to a baseline model including stage, age, and sex, the c-index of the model demonstrated an absolute 3.7% improvement (95% CI 1.0-6.5) in the combined cohort. Additionally, our models stratified patients within individual cancer stages, particularly stage II (p=0.025) and stage III (p<0.001). By developing and evaluating prognostic models across multiple cancer types, this work represents one of the most comprehensive studies exploring the direct prediction of clinical outcomes using deep learning and histopathology images. Our analysis demonstrates the potential for this approach to provide prognostic information in multiple cancer types, and even within specific pathologic stages. However, given the relatively small number of clinical events, we observed wide confidence intervals, suggesting that future work will benefit from larger datasets.