 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Prostate Cancer-Specific Mortality with A.I.-based Gleason Grading
Nov 25, 2020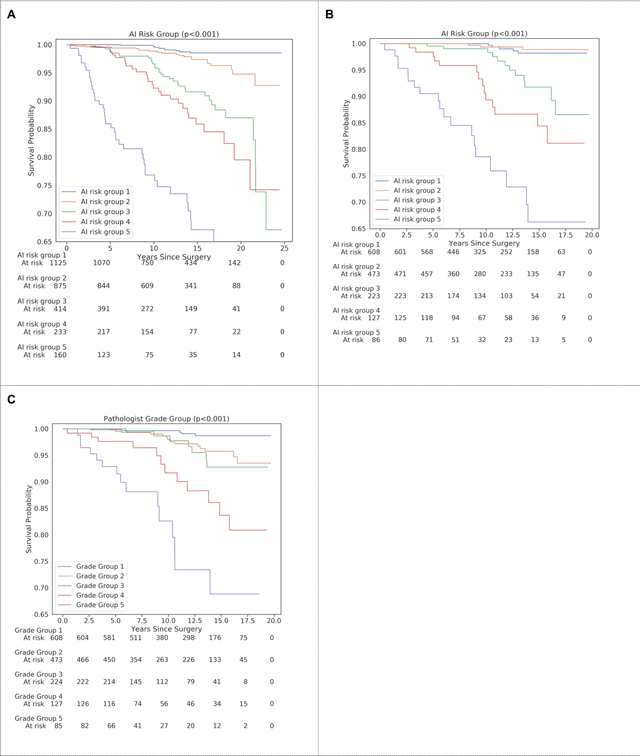
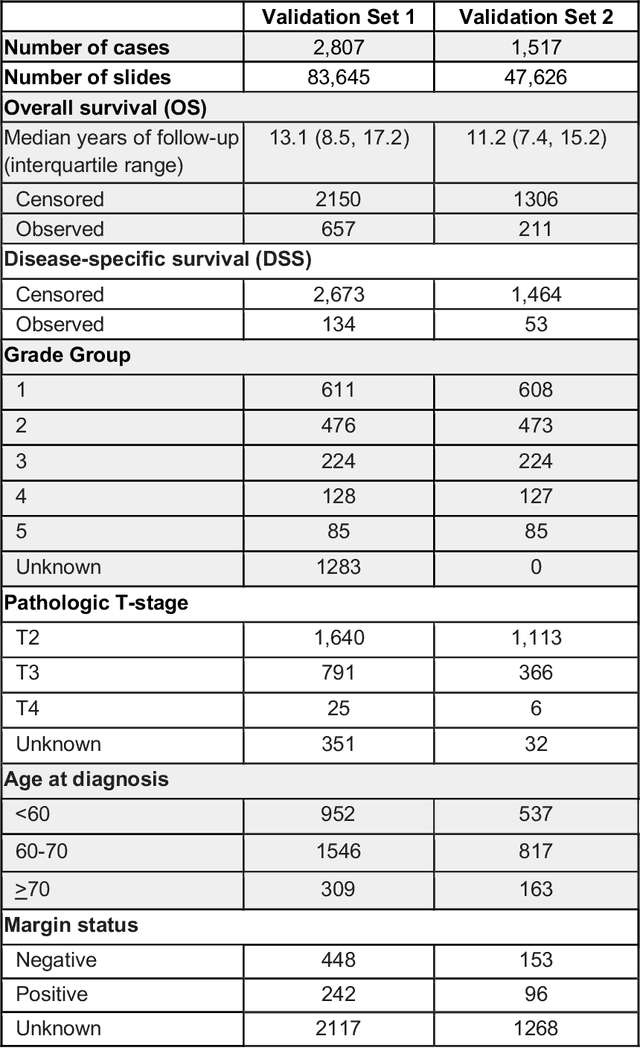
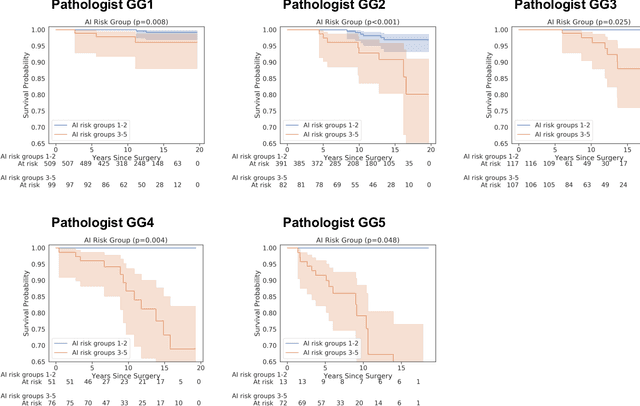
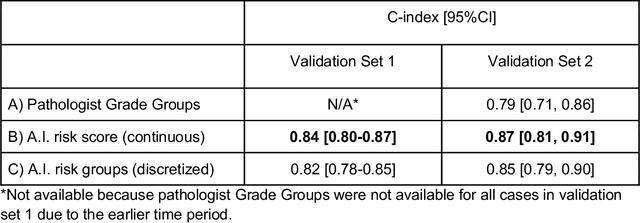
Gleason grading of prostate cancer is an important prognostic factor but suffers from poor reproducibility, particularly among non-subspecialist pathologists. Although artificial intelligence (A.I.) tools have demonstrated Gleason grading on-par with expert pathologists, it remains an open question whether A.I. grading translates to better prognostication. In this study, we developed a system to predict prostate-cancer specific mortality via A.I.-based Gleason grading and subsequently evaluated its ability to risk-stratify patients on an independent retrospective cohort of 2,807 prostatectomy cases from a single European center with 5-25 years of follow-up (median: 13, interquartile range 9-17). The A.I.'s risk scores produced a C-index of 0.84 (95%CI 0.80-0.87) for prostate cancer-specific mortality. Upon discretizing these risk scores into risk groups analogous to pathologist Grade Groups (GG), the A.I. had a C-index of 0.82 (95%CI 0.78-0.85). On the subset of cases with a GG in the original pathology report (n=1,517), the A.I.'s C-indices were 0.87 and 0.85 for continuous and discrete grading, respectively, compared to 0.79 (95%CI 0.71-0.86) for GG obtained from the reports. These represent improvements of 0.08 (95%CI 0.01-0.15) and 0.07 (95%CI 0.00-0.14) respectively. Our results suggest that A.I.-based Gleason grading can lead to effective risk-stratification and warrants further evaluation for improving disease management.
Interpretable Survival Prediction for Colorectal Cancer using Deep Learning
Nov 17, 2020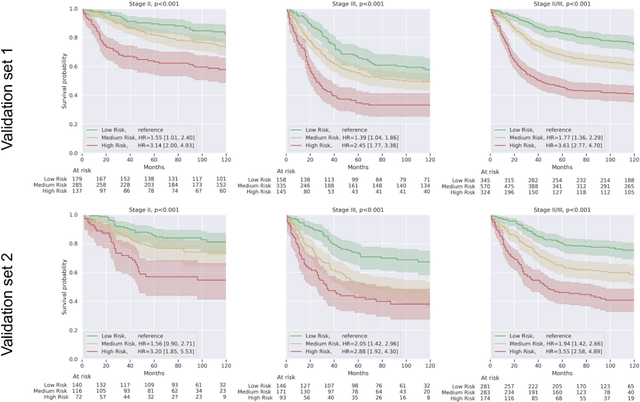
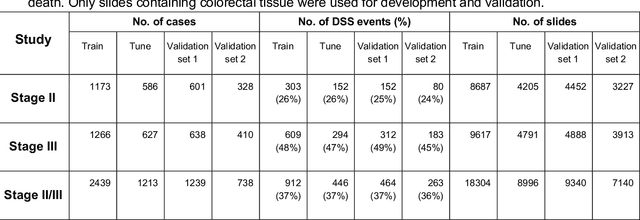
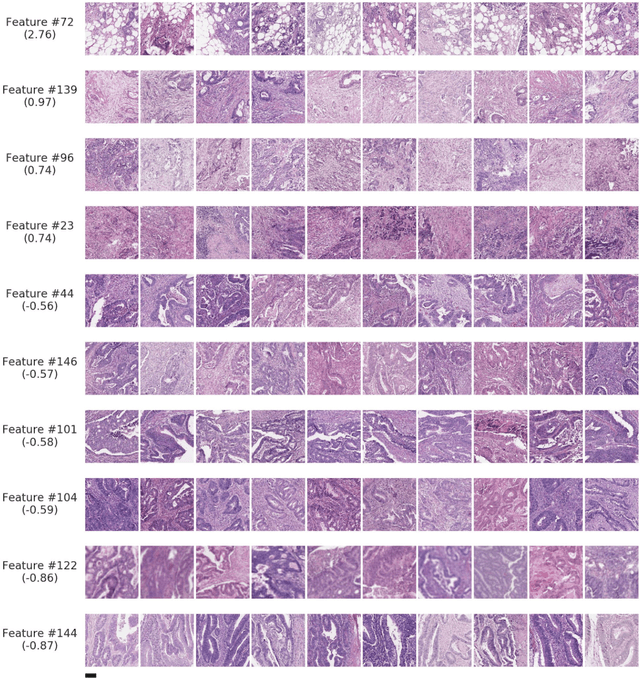
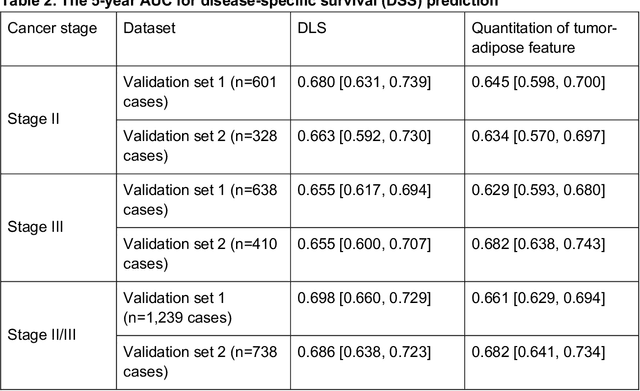
Deriving interpretable prognostic features from deep-learning-based prognostic histopathology models remains a challenge. In this study, we developed a deep learning system (DLS) for predicting disease specific survival for stage II and III colorectal cancer using 3,652 cases (27,300 slides). When evaluated on two validation datasets containing 1,239 cases (9,340 slides) and 738 cases (7,140 slides) respectively, the DLS achieved a 5-year disease-specific survival AUC of 0.70 (95%CI 0.66-0.73) and 0.69 (95%CI 0.64-0.72), and added significant predictive value to a set of 9 clinicopathologic features. To interpret the DLS, we explored the ability of different human-interpretable features to explain the variance in DLS scores. We observed that clinicopathologic features such as T-category, N-category, and grade explained a small fraction of the variance in DLS scores (R2=18% in both validation sets). Next, we generated human-interpretable histologic features by clustering embeddings from a deep-learning based image-similarity model and showed that they explain the majority of the variance (R2 of 73% to 80%). Furthermore, the clustering-derived feature most strongly associated with high DLS scores was also highly prognostic in isolation. With a distinct visual appearance (poorly differentiated tumor cell clusters adjacent to adipose tissue), this feature was identified by annotators with 87.0-95.5% accuracy. Our approach can be used to explain predictions from a prognostic deep learning model and uncover potentially-novel prognostic features that can be reliably identified by people for future validation studies.