 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Sense Disambiguation
The task of Word Sense Disambiguation (WSD) consists of associating words in context with their most suitable entry in a pre-defined sense inventory. The de facto sense inventory for English in WSD is WordNet.
Papers and Code
Bridging Lexical Ambiguity and Vision: A Mini Review on Visual Word Sense Disambiguation
Feb 01, 2026This paper offers a mini review of Visual Word Sense Disambiguation (VWSD), which is a multimodal extension of traditional Word Sense Disambiguation (WSD). VWSD helps tackle lexical ambiguity in vision-language tasks. While conventional WSD depends only on text and lexical resources, VWSD uses visual cues to find the right meaning of ambiguous words with minimal text input. The review looks at developments from early multimodal fusion methods to new frameworks that use contrastive models like CLIP, diffusion-based text-to-image generation, and large language model (LLM) support. Studies from 2016 to 2025 are examined to show the growth of VWSD through feature-based, graph-based, and contrastive embedding techniques. It focuses on prompt engineering, fine-tuning, and adapting to multiple languages. Quantitative results show that CLIP-based fine-tuned models and LLM-enhanced VWSD systems consistently perform better than zero-shot baselines, achieving gains of up to 6-8\% in Mean Reciprocal Rank (MRR). However, challenges still exist, such as limitations in context, model bias toward common meanings, a lack of multilingual datasets, and the need for better evaluation frameworks. The analysis highlights the growing overlap of CLIP alignment, diffusion generation, and LLM reasoning as the future path for strong, context-aware, and multilingual disambiguation systems.
Creating a Hybrid Rule and Neural Network Based Semantic Tagger using Silver Standard Data: the PyMUSAS framework for Multilingual Semantic Annotation
Jan 14, 2026Word Sense Disambiguation (WSD) has been widely evaluated using the semantic frameworks of WordNet, BabelNet, and the Oxford Dictionary of English. However, for the UCREL Semantic Analysis System (USAS) framework, no open extensive evaluation has been performed beyond lexical coverage or single language evaluation. In this work, we perform the largest semantic tagging evaluation of the rule based system that uses the lexical resources in the USAS framework covering five different languages using four existing datasets and one novel Chinese dataset. We create a new silver labelled English dataset, to overcome the lack of manually tagged training data, that we train and evaluate various mono and multilingual neural models in both mono and cross-lingual evaluation setups with comparisons to their rule based counterparts, and show how a rule based system can be enhanced with a neural network model. The resulting neural network models, including the data they were trained on, the Chinese evaluation dataset, and all of the code have been released as open resources.
Quantum Visual Word Sense Disambiguation: Unraveling Ambiguities Through Quantum Inference Model
Dec 31, 2025Visual word sense disambiguation focuses on polysemous words, where candidate images can be easily confused. Traditional methods use classical probability to calculate the likelihood of an image matching each gloss of the target word, summing these to form a posterior probability. However, due to the challenge of semantic uncertainty, glosses from different sources inevitably carry semantic biases, which can lead to biased disambiguation results. Inspired by quantum superposition in modeling uncertainty, this paper proposes a Quantum Inference Model for Unsupervised Visual Word Sense Disambiguation (Q-VWSD). It encodes multiple glosses of the target word into a superposition state to mitigate semantic biases. Then, the quantum circuit is executed, and the results are observed. By formalizing our method, we find that Q-VWSD is a quantum generalization of the method based on classical probability. Building on this, we further designed a heuristic version of Q-VWSD that can run more efficiently on classical computing. The experiments demonstrate that our method outperforms state-of-the-art classical methods, particularly by effectively leveraging non-specialized glosses from large language models, which further enhances performance. Our approach showcases the potential of quantum machine learning in practical applications and provides a case for leveraging quantum modeling advantages on classical computers while quantum hardware remains immature.
LANE: Lexical Adversarial Negative Examples for Word Sense Disambiguation
Nov 14, 2025Fine-grained word meaning resolution remains a critical challenge for neural language models (NLMs) as they often overfit to global sentence representations, failing to capture local semantic details. We propose a novel adversarial training strategy, called LANE, to address this limitation by deliberately shifting the model's learning focus to the target word. This method generates challenging negative training examples through the selective marking of alternate words in the training set. The goal is to force the model to create a greater separability between same sentences with different marked words. Experimental results on lexical semantic change detection and word sense disambiguation benchmarks demonstrate that our approach yields more discriminative word representations, improving performance over standard contrastive learning baselines. We further provide qualitative analyses showing that the proposed negatives lead to representations that better capture subtle meaning differences even in challenging environments. Our method is model-agnostic and can be integrated into existing representation learning frameworks.
Adverbs Revisited: Enhancing WordNet Coverage of Adverbs with a Supersense Taxonomy
Nov 14, 2025WordNet offers rich supersense hierarchies for nouns and verbs, yet adverbs remain underdeveloped, lacking a systematic semantic classification. We introduce a linguistically grounded supersense typology for adverbs, empirically validated through annotation, that captures major semantic domains including manner, temporal, frequency, degree, domain, speaker-oriented, and subject-oriented functions. Results from a pilot annotation study demonstrate that these categories provide broad coverage of adverbs in natural text and can be reliably assigned by human annotators. Incorporating this typology extends WordNet's coverage, aligns it more closely with linguistic theory, and facilitates downstream NLP applications such as word sense disambiguation, event extraction, sentiment analysis, and discourse modeling. We present the proposed supersense categories, annotation outcomes, and directions for future work.
ViConBERT: Context-Gloss Aligned Vietnamese Word Embedding for Polysemous and Sense-Aware Representations
Nov 15, 2025Recent advances in contextualized word embeddings have greatly improved semantic tasks such as Word Sense Disambiguation (WSD) and contextual similarity, but most progress has been limited to high-resource languages like English. Vietnamese, in contrast, still lacks robust models and evaluation resources for fine-grained semantic understanding. In this paper, we present ViConBERT, a novel framework for learning Vietnamese contextualized embeddings that integrates contrastive learning (SimCLR) and gloss-based distillation to better capture word meaning. We also introduce ViConWSD, the first large-scale synthetic dataset for evaluating semantic understanding in Vietnamese, covering both WSD and contextual similarity. Experimental results show that ViConBERT outperforms strong baselines on WSD (F1 = 0.87) and achieves competitive performance on ViCon (AP = 0.88) and ViSim-400 (Spearman's rho = 0.60), demonstrating its effectiveness in modeling both discrete senses and graded semantic relations. Our code, models, and data are available at https://github.com/tkhangg0910/ViConBERT
\textsc{CantoNLU}: A benchmark for Cantonese natural language understanding
Oct 23, 2025Cantonese, although spoken by millions, remains under-resourced due to policy and diglossia. To address this scarcity of evaluation frameworks for Cantonese, we introduce \textsc{\textbf{CantoNLU}}, a benchmark for Cantonese natural language understanding (NLU). This novel benchmark spans seven tasks covering syntax and semantics, including word sense disambiguation, linguistic acceptability judgment, language detection, natural language inference, sentiment analysis, part-of-speech tagging, and dependency parsing. In addition to the benchmark, we provide model baseline performance across a set of models: a Mandarin model without Cantonese training, two Cantonese-adapted models obtained by continual pre-training a Mandarin model on Cantonese text, and a monolingual Cantonese model trained from scratch. Results show that Cantonese-adapted models perform best overall, while monolingual models perform better on syntactic tasks. Mandarin models remain competitive in certain settings, indicating that direct transfer may be sufficient when Cantonese domain data is scarce. We release all datasets, code, and model weights to facilitate future research in Cantonese NLP.
COLE: a Comprehensive Benchmark for French Language Understanding Evaluation
Oct 06, 2025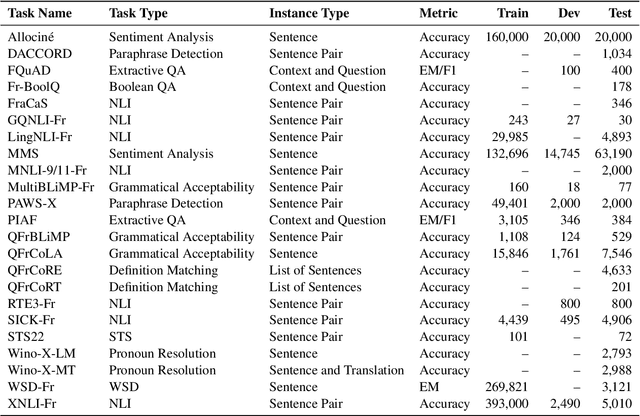
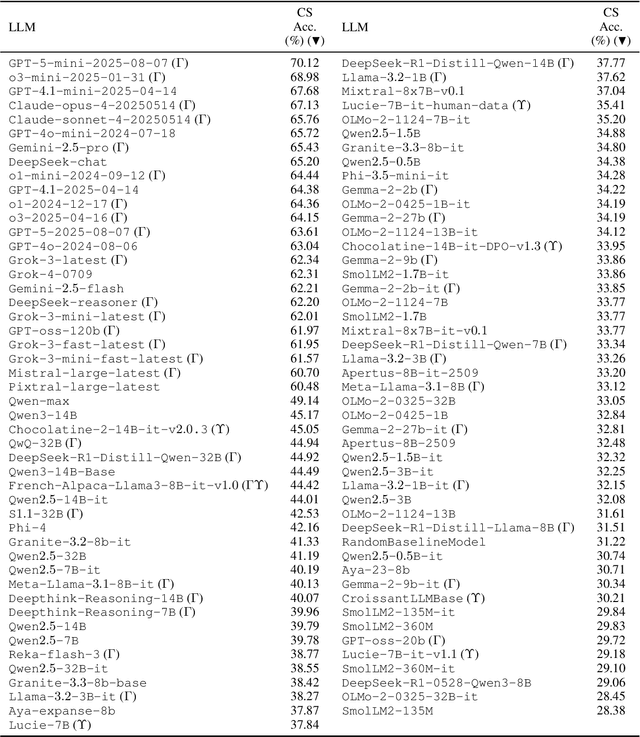


To address the need for a more comprehensive evaluation of French Natural Language Understanding (NLU), we introduce COLE, a new benchmark composed of 23 diverse task covering a broad range of NLU capabilities, including sentiment analysis, paraphrase detection, grammatical judgment, and reasoning, with a particular focus on linguistic phenomena relevant to the French language. We benchmark 94 large language models (LLM), providing an extensive analysis of the current state of French NLU. Our results highlight a significant performance gap between closed- and open-weights models and identify key challenging frontiers for current LLMs, such as zero-shot extractive question-answering (QA), fine-grained word sense disambiguation, and understanding of regional language variations. We release COLE as a public resource to foster further progress in French language modelling.
Do Large Language Models Understand Word Senses?
Sep 17, 2025
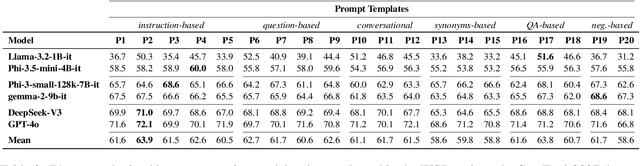
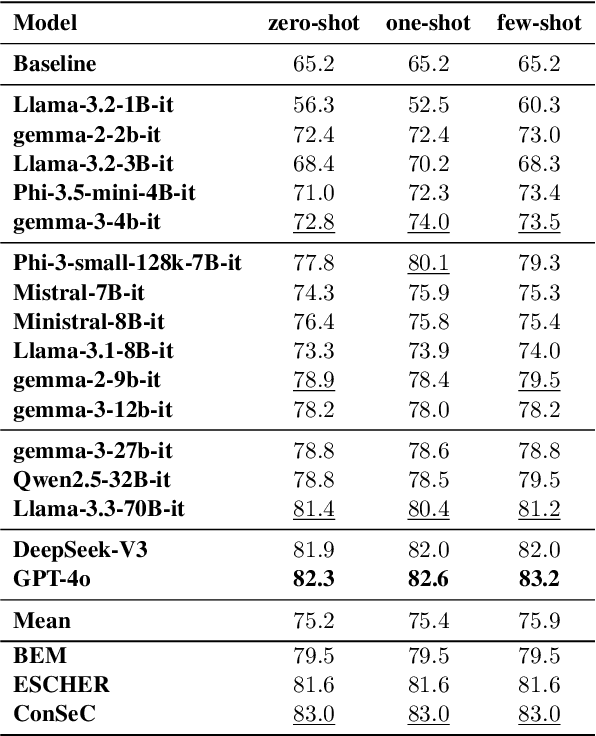
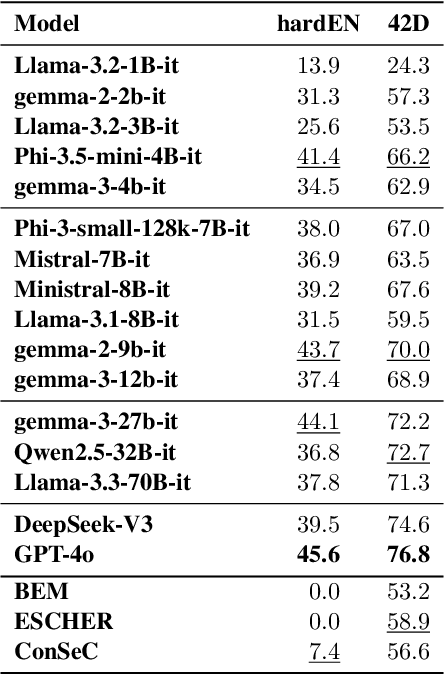
Understanding the meaning of words in context is a fundamental capability for Large Language Models (LLMs). Despite extensive evaluation efforts, the extent to which LLMs show evidence that they truly grasp word senses remains underexplored. In this paper, we address this gap by evaluating both i) the Word Sense Disambiguation (WSD) capabilities of instruction-tuned LLMs, comparing their performance to state-of-the-art systems specifically designed for the task, and ii) the ability of two top-performing open- and closed-source LLMs to understand word senses in three generative settings: definition generation, free-form explanation, and example generation. Notably, we find that, in the WSD task, leading models such as GPT-4o and DeepSeek-V3 achieve performance on par with specialized WSD systems, while also demonstrating greater robustness across domains and levels of difficulty. In the generation tasks, results reveal that LLMs can explain the meaning of words in context up to 98\% accuracy, with the highest performance observed in the free-form explanation task, which best aligns with their generative capabilities.
On Self-improving Token Embeddings
Apr 21, 2025This article introduces a novel and fast method for refining pre-trained static word or, more generally, token embeddings. By incorporating the embeddings of neighboring tokens in text corpora, it continuously updates the representation of each token, including those without pre-assigned embeddings. This approach effectively addresses the out-of-vocabulary problem, too. Operating independently of large language models and shallow neural networks, it enables versatile applications such as corpus exploration, conceptual search, and word sense disambiguation. The method is designed to enhance token representations within topically homogeneous corpora, where the vocabulary is restricted to a specific domain, resulting in more meaningful embeddings compared to general-purpose pre-trained vectors. As an example, the methodology is applied to explore storm events and their impacts on infrastructure and communities using narratives from a subset of the NOAA Storm Events database. The article also demonstrates how the approach improves the representation of storm-related terms over time, providing valuable insights into the evolving nature of disaster narratives.