 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSANDWiCH: Semantical Analysis of Neighbours for Disambiguating Words in Context ad Hoc
Mar 07, 2025



The rise of generative chat-based Large Language Models (LLMs) over the past two years has spurred a race to develop systems that promise near-human conversational and reasoning experiences. However, recent studies indicate that the language understanding offered by these models remains limited and far from human-like performance, particularly in grasping the contextual meanings of words, an essential aspect of reasoning. In this paper, we present a simple yet computationally efficient framework for multilingual Word Sense Disambiguation (WSD). Our approach reframes the WSD task as a cluster discrimination analysis over a semantic network refined from BabelNet using group algebra. We validate our methodology across multiple WSD benchmarks, achieving a new state of the art for all languages and tasks, as well as in individual assessments by part of speech. Notably, our model significantly surpasses the performance of current alternatives, even in low-resource languages, while reducing the parameter count by 72%.
Back to the Basics: A Quantitative Analysis of Statistical and Graph-Based Term Weighting Schemes for Keyword Extraction
Apr 16, 2021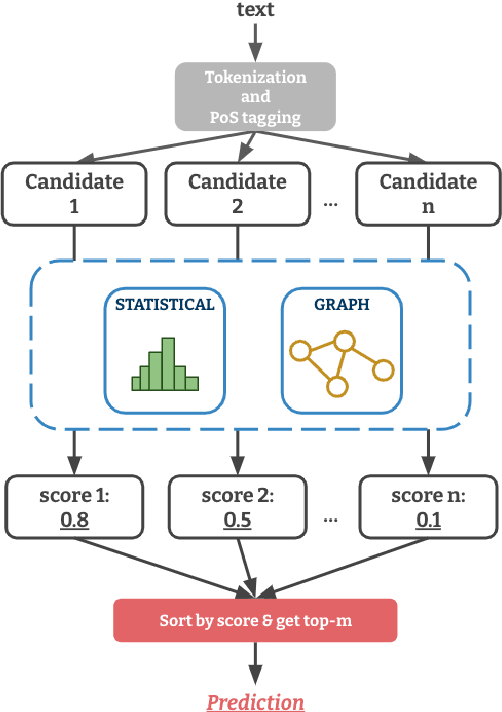
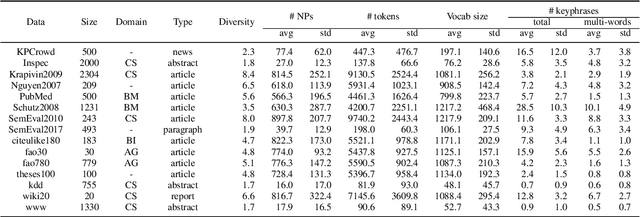
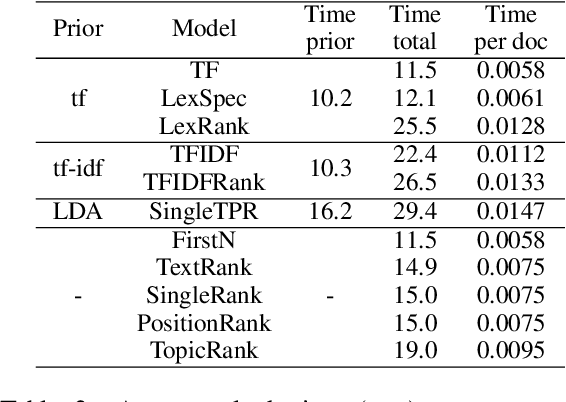
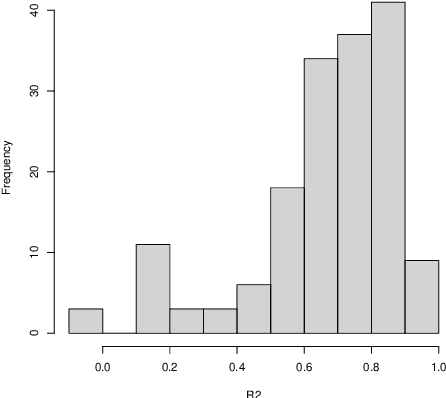
Term weighting schemes are widely used in Natural Language Processing and Information Retrieval. In particular, term weighting is the basis for keyword extraction. However, there are relatively few evaluation studies that shed light about the strengths and shortcomings of each weighting scheme. In fact, in most cases researchers and practitioners resort to the well-known tf-idf as default, despite the existence of other suitable alternatives, including graph-based models. In this paper, we perform an exhaustive and large-scale empirical comparison of both statistical and graph-based term weighting methods in the context of keyword extraction. Our analysis reveals some interesting findings such as the advantages of the less-known lexical specificity with respect to tf-idf, or the qualitative differences between statistical and graph-based methods. Finally, based on our findings we discuss and devise some suggestions for practitioners. We release our code at https://github.com/asahi417/kex .