 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Self-improving Token Embeddings
Apr 21, 2025This article introduces a novel and fast method for refining pre-trained static word or, more generally, token embeddings. By incorporating the embeddings of neighboring tokens in text corpora, it continuously updates the representation of each token, including those without pre-assigned embeddings. This approach effectively addresses the out-of-vocabulary problem, too. Operating independently of large language models and shallow neural networks, it enables versatile applications such as corpus exploration, conceptual search, and word sense disambiguation. The method is designed to enhance token representations within topically homogeneous corpora, where the vocabulary is restricted to a specific domain, resulting in more meaningful embeddings compared to general-purpose pre-trained vectors. As an example, the methodology is applied to explore storm events and their impacts on infrastructure and communities using narratives from a subset of the NOAA Storm Events database. The article also demonstrates how the approach improves the representation of storm-related terms over time, providing valuable insights into the evolving nature of disaster narratives.
Improving Aspect Term Extraction with Bidirectional Dependency Tree Representation
May 21, 2018

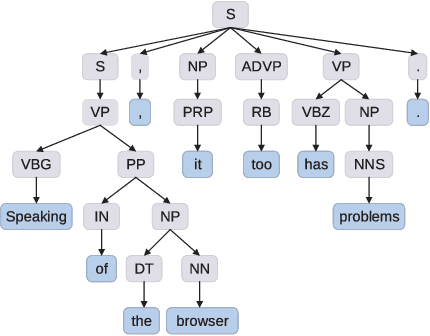

Aspect term extraction is one of the important subtasks in aspect-based sentiment analysis. Previous studies have shown that dependency tree structure representation is promising for this task. In this paper, we propose a novel bidirectional dependency tree network to extract dependency structure features from the given sentences. The key idea is to explicitly incorporate both representations gained separately from the bottom-up and top-down propagation on the given dependency syntactic tree. An end-to-end framework is proposed to integrate the embedded representations and BiLSTM plus CRF to learn both tree-structured and sequential features to solve the aspect term extraction problem. Experimental results demonstrate that the proposed model outperforms state-of-the-art baseline models on four benchmark SemEval datasets.