 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiNUS: Lightweight Automatic Segmentation of Deep Brain Nuclei for Real-Time DBS Surgery
Jan 21, 2026This paper proposes LiNUS, a lightweight deep learning framework for the automatic segmentation of the Subthalamic Nucleus (STN) in Deep Brain Stimulation (DBS) surgery. Addressing the challenges of small target volume and class imbalance in MRI data, LiNUS improves upon the U-Net architecture by introducing spectral normalization constraints, bilinear interpolation upsampling, and a multi-scale feature fusion mechanism. Experimental results on the Tsinghua DBS dataset (TT14) demonstrate that LiNUS achieves a Dice coefficient of 0.679 with an inference time of only 0.05 seconds per subject, significantly outperforming traditional manual and registration-based methods. Further validation on high-resolution data confirms the model's robustness, achieving a Dice score of 0.89. A dedicated Graphical User Interface (GUI) was also developed to facilitate real-time clinical application.
Efficient and Effective In-context Demonstration Selection with Coreset
Nov 12, 2025In-context learning (ICL) has emerged as a powerful paradigm for Large Visual Language Models (LVLMs), enabling them to leverage a few examples directly from input contexts. However, the effectiveness of this approach is heavily reliant on the selection of demonstrations, a process that is NP-hard. Traditional strategies, including random, similarity-based sampling and infoscore-based sampling, often lead to inefficiencies or suboptimal performance, struggling to balance both efficiency and effectiveness in demonstration selection. In this paper, we propose a novel demonstration selection framework named Coreset-based Dual Retrieval (CoDR). We show that samples within a diverse subset achieve a higher expected mutual information. To implement this, we introduce a cluster-pruning method to construct a diverse coreset that aligns more effectively with the query while maintaining diversity. Additionally, we develop a dual retrieval mechanism that enhances the selection process by achieving global demonstration selection while preserving efficiency. Experimental results demonstrate that our method significantly improves the ICL performance compared to the existing strategies, providing a robust solution for effective and efficient demonstration selection.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
FLASH: Latent-Aware Semi-Autoregressive Speculative Decoding for Multimodal Tasks
May 19, 2025Large language and multimodal models (LLMs and LMMs) exhibit strong inference capabilities but are often limited by slow decoding speeds. This challenge is especially acute in LMMs, where visual inputs typically comprise more tokens with lower information density than text -- an issue exacerbated by recent trends toward finer-grained visual tokenizations to boost performance. Speculative decoding has been effective in accelerating LLM inference by using a smaller draft model to generate candidate tokens, which are then selectively verified by the target model, improving speed without sacrificing output quality. While this strategy has been extended to LMMs, existing methods largely overlook the unique properties of visual inputs and depend solely on text-based draft models. In this work, we propose \textbf{FLASH} (Fast Latent-Aware Semi-Autoregressive Heuristics), a speculative decoding framework designed specifically for LMMs, which leverages two key properties of multimodal data to design the draft model. First, to address redundancy in visual tokens, we propose a lightweight latent-aware token compression mechanism. Second, recognizing that visual objects often co-occur within a scene, we employ a semi-autoregressive decoding strategy to generate multiple tokens per forward pass. These innovations accelerate draft decoding while maintaining high acceptance rates, resulting in faster overall inference. Experiments show that FLASH significantly outperforms prior speculative decoding approaches in both unimodal and multimodal settings, achieving up to \textbf{2.68$\times$} speed-up on video captioning and \textbf{2.55$\times$} on visual instruction tuning tasks compared to the original LMM.
Cyclic Learning: Bridging Image-level Labels and Nuclei Instance Segmentation
Jun 05, 2023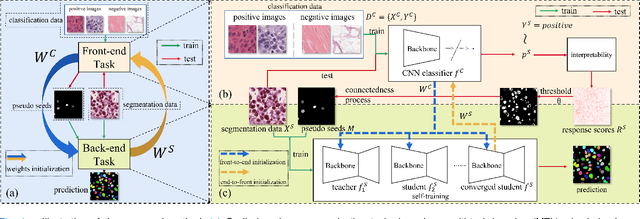



Nuclei instance segmentation on histopathology images is of great clinical value for disease analysis. Generally, fully-supervised algorithms for this task require pixel-wise manual annotations, which is especially time-consuming and laborious for the high nuclei density. To alleviate the annotation burden, we seek to solve the problem through image-level weakly supervised learning, which is underexplored for nuclei instance segmentation. Compared with most existing methods using other weak annotations (scribble, point, etc.) for nuclei instance segmentation, our method is more labor-saving. The obstacle to using image-level annotations in nuclei instance segmentation is the lack of adequate location information, leading to severe nuclei omission or overlaps. In this paper, we propose a novel image-level weakly supervised method, called cyclic learning, to solve this problem. Cyclic learning comprises a front-end classification task and a back-end semi-supervised instance segmentation task to benefit from multi-task learning (MTL). We utilize a deep learning classifier with interpretability as the front-end to convert image-level labels to sets of high-confidence pseudo masks and establish a semi-supervised architecture as the back-end to conduct nuclei instance segmentation under the supervision of these pseudo masks. Most importantly, cyclic learning is designed to circularly share knowledge between the front-end classifier and the back-end semi-supervised part, which allows the whole system to fully extract the underlying information from image-level labels and converge to a better optimum. Experiments on three datasets demonstrate the good generality of our method, which outperforms other image-level weakly supervised methods for nuclei instance segmentation, and achieves comparable performance to fully-supervised methods.
Transforming Visual Scene Graphs to Image Captions
May 05, 2023



We propose to Transform Scene Graphs (TSG) into more descriptive captions. In TSG, we apply multi-head attention (MHA) to design the Graph Neural Network (GNN) for embedding scene graphs. After embedding, different graph embeddings contain diverse specific knowledge for generating the words with different part-of-speech, e.g., object/attribute embedding is good for generating nouns/adjectives. Motivated by this, we design a Mixture-of-Expert (MOE)-based decoder, where each expert is built on MHA, for discriminating the graph embeddings to generate different kinds of words. Since both the encoder and decoder are built based on the MHA, as a result, we construct a homogeneous encoder-decoder unlike the previous heterogeneous ones which usually apply Fully-Connected-based GNN and LSTM-based decoder. The homogeneous architecture enables us to unify the training configuration of the whole model instead of specifying different training strategies for diverse sub-networks as in the heterogeneous pipeline, which releases the training difficulty. Extensive experiments on the MS-COCO captioning benchmark validate the effectiveness of our TSG. The code is in: https://anonymous.4open.science/r/ACL23_TSG.
Adaptively Clustering Neighbor Elements for Image Captioning
Jan 05, 2023We design a novel global-local Transformer named \textbf{Ada-ClustFormer} (\textbf{ACF}) to generate captions. We use this name since each layer of ACF can adaptively cluster input elements to carry self-attention (Self-ATT) for learning local context. Compared with other global-local Transformers which carry Self-ATT in fixed-size windows, ACF can capture varying graininess, \eg, an object may cover different numbers of grids or a phrase may contain diverse numbers of words. To build ACF, we insert a probabilistic matrix C into the Self-ATT layer. For an input sequence {{s}_1,...,{s}_N , C_{i,j} softly determines whether the sub-sequence {s_i,...,s_j} should be clustered for carrying Self-ATT. For implementation, {C}_{i,j} is calculated from the contexts of {{s}_i,...,{s}_j}, thus ACF can exploit the input itself to decide which local contexts should be learned. By using ACF to build the vision encoder and language decoder, the captioning model can automatically discover the hidden structures in both vision and language, which encourages the model to learn a unified structural space for transferring more structural commonalities. The experiment results demonstrate the effectiveness of ACF that we achieve CIDEr of 137.8, which outperforms most SOTA captioning models and achieve comparable scores compared with some BERT-based models. The code will be available in the supplementary material.