 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precise Model-free Robotic Grasping with Sim-to-Real Transfer Learning
Jan 28, 2023Precise robotic grasping of several novel objects is a huge challenge in manufacturing, automation, and logistics. Most of the current methods for model-free grasping are disadvantaged by the sparse data in grasping datasets and by errors in sensor data and contact models. This study combines data generation and sim-to-real transfer learning in a grasping framework that reduces the sim-to-real gap and enables precise and reliable model-free grasping. A large-scale robotic grasping dataset with dense grasp labels is generated using domain randomization methods and a novel data augmentation method for deep learning-based robotic grasping to solve data sparse problem. We present an end-to-end robotic grasping network with a grasp optimizer. The grasp policies are trained with sim-to-real transfer learning. The presented results suggest that our grasping framework reduces the uncertainties in grasping datasets, sensor data, and contact models. In physical robotic experiments, our grasping framework grasped single known objects and novel complex-shaped household objects with a success rate of 90.91%. In a complex scenario with multi-objects robotic grasping, the success rate was 85.71%. The proposed grasping framework outperformed two state-of-the-art methods in both known and unknown object robotic grasping.
* 8 pages, 11 figures
Sim-to-Real Transfer of Robotic Assembly with Visual Inputs Using CycleGAN and Force Control
Aug 30, 2022
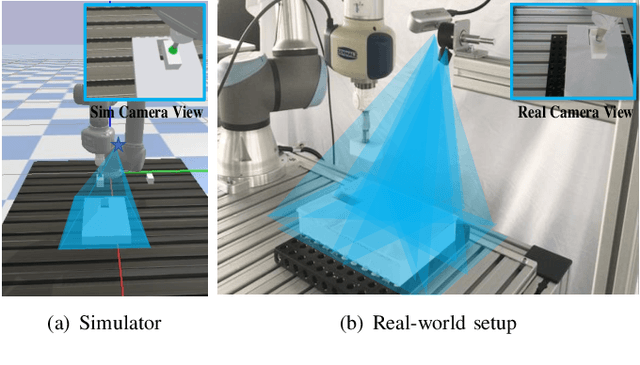
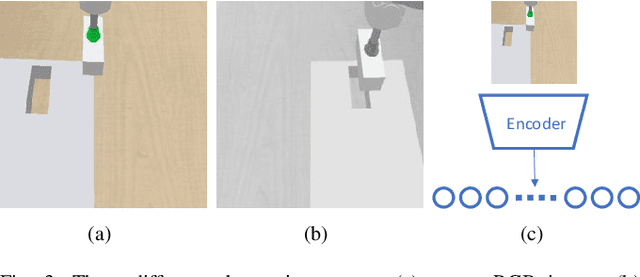
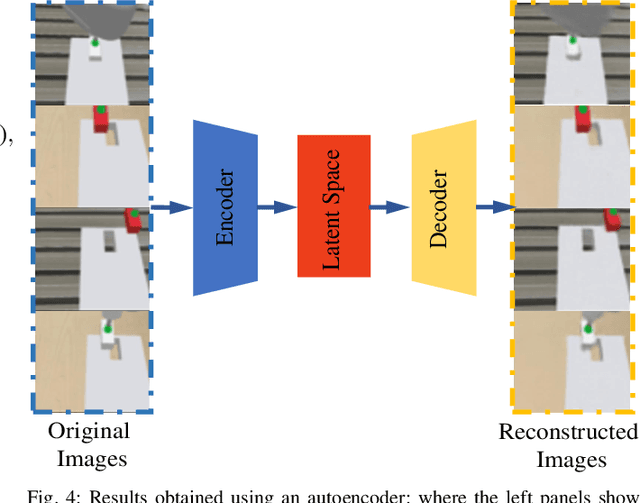
Recently, deep reinforcement learning (RL) has shown some impressive successes in robotic manipulation applications. However, training robots in the real world is nontrivial owing to sample efficiency and safety concerns. Sim-to-real transfer is proposed to address the aforementioned concerns but introduces a new issue called the reality gap. In this work, we introduce a sim-to-real learning framework for vision-based assembly tasks and perform training in a simulated environment by employing inputs from a single camera to address the aforementioned issues. We present a domain adaptation method based on cycle-consistent generative adversarial networks (CycleGAN) and a force control transfer approach to bridge the reality gap. We demonstrate that the proposed framework trained in a simulated environment can be successfully transferred to a real peg-in-hole setup.
Maximizing the Use of Environmental Constraints: A Pushing-Based Hybrid Position/Force Assembly Skill for Contact-Rich Tasks
Aug 12, 2022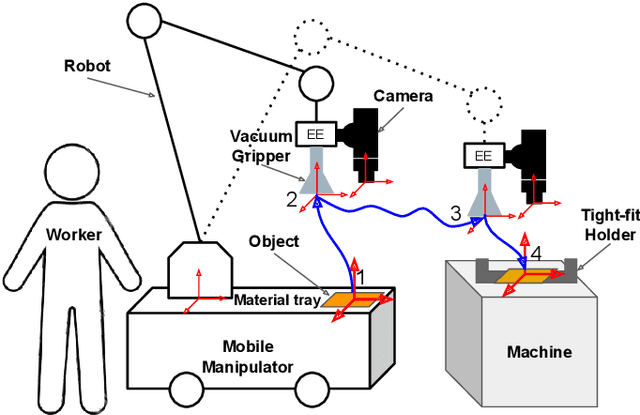
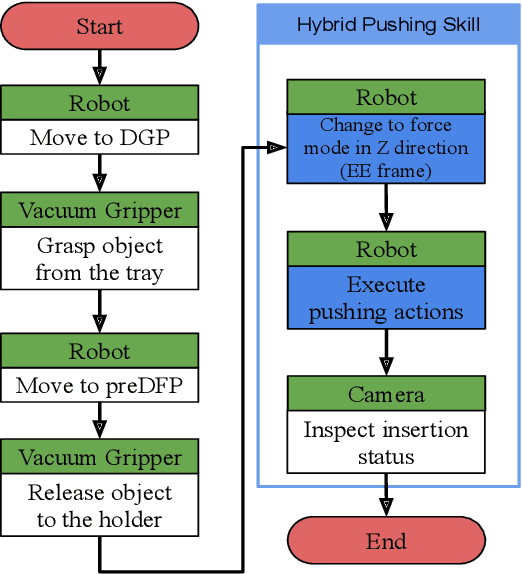
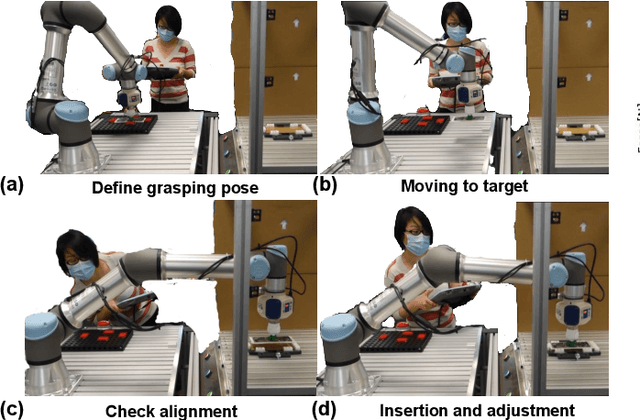
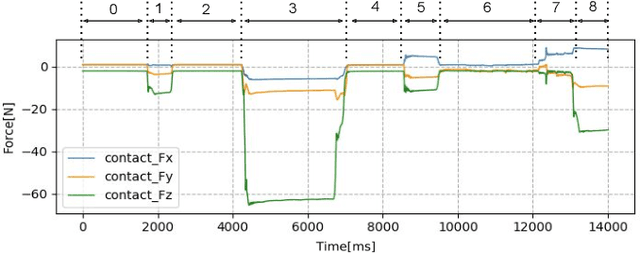
The need for contact-rich tasks is rapidly growing in modern manufacturing settings. However, few traditional robotic assembly skills consider environmental constraints during task execution, and most of them use these constraints as termination conditions. In this study, we present a pushing-based hybrid position/force assembly skill that can maximize environmental constraints during task execution. To the best of our knowledge, this is the first work that considers using pushing actions during the execution of the assembly tasks. We have proved that our skill can maximize the utilization of environmental constraints using mobile manipulator system assembly task experiments, and achieve a 100\% success rate in the executions.
Impedance Adaptation by Reinforcement Learning with Contact Dynamic Movement Primitives
Mar 21, 2022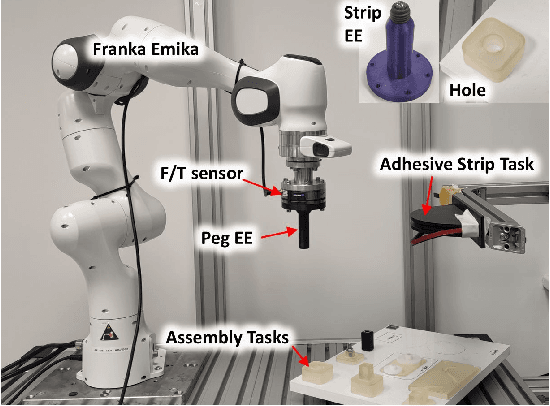
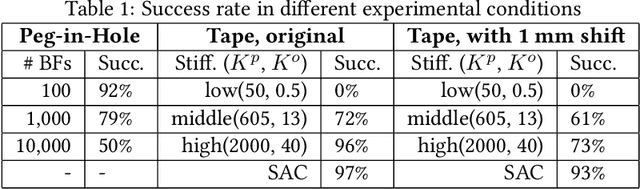
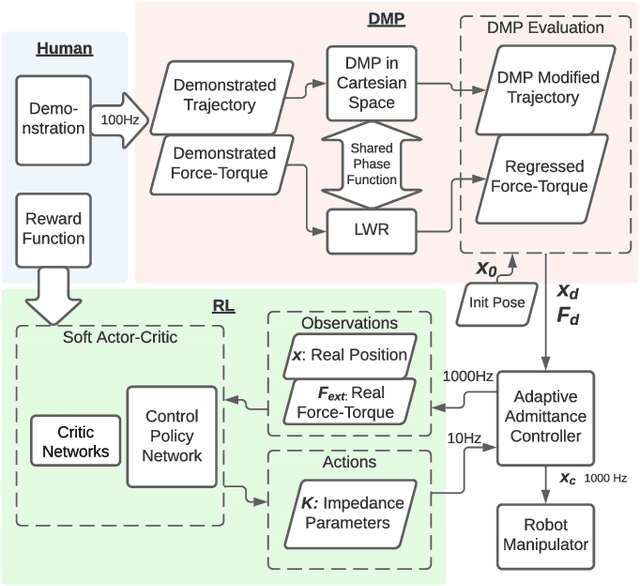
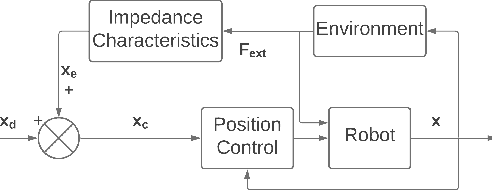
Dynamic movement primitives (DMPs) allow complex position trajectories to be efficiently demonstrated to a robot. In contact-rich tasks, where position trajectories alone may not be safe or robust over variation in contact geometry, DMPs have been extended to include force trajectories. However, different task phases or degrees of freedom may require the tracking of either position or force -- e.g., once contact is made, it may be more important to track the force demonstration trajectory in the contact direction. The robot impedance balances between following a position or force reference trajectory, where a high stiffness tracks position and a low stiffness tracks force. This paper proposes using DMPs to learn position and force trajectories from demonstrations, then adapting the impedance parameters online with a higher-level control policy trained by reinforcement learning. This allows one-shot demonstration of the task with DMPs, and improved robustness and performance from the impedance adaptation. The approach is validated on peg-in-hole and adhesive strip application tasks.
Combining Learning from Demonstration with Learning by Exploration to Facilitate Contact-Rich Tasks
Mar 10, 2021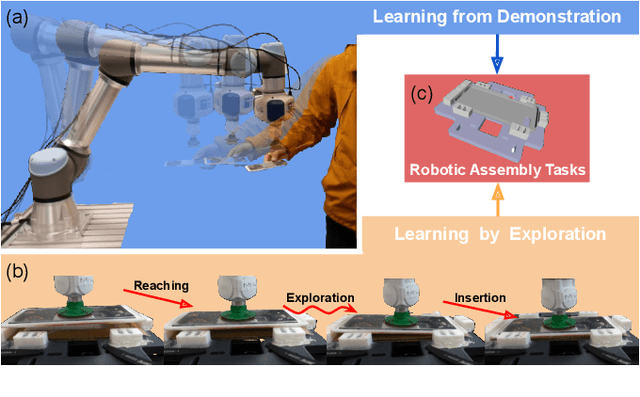

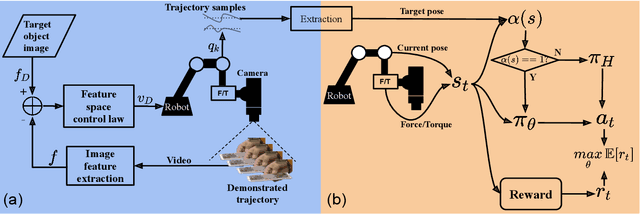

Collaborative robots are expected to be able to work alongside humans and in some cases directly replace existing human workers, thus effectively responding to rapid assembly line changes. Current methods for programming contact-rich tasks, especially in heavily constrained space, tend to be fairly inefficient. Therefore, faster and more intuitive approaches to robot teaching are urgently required. This work focuses on combining visual servoing based learning from demonstration (LfD) and force-based learning by exploration (LbE), to enable fast and intuitive programming of contact-rich tasks with minimal user effort required. Two learning approaches were developed and integrated into a framework, and one relying on human to robot motion mapping (the visual servoing approach) and one on force-based reinforcement learning. The developed framework implements the non-contact demonstration teaching method based on visual servoing approach and optimizes the demonstrated robot target positions according to the detected contact state. The framework has been compared with two most commonly used baseline techniques, pendant-based teaching and hand-guiding teaching. The efficiency and reliability of the framework have been validated through comparison experiments involving the teaching and execution of contact-rich tasks. The framework proposed in this paper has performed the best in terms of teaching time, execution success rate, risk of damage, and ease of use.
Proactive Action Visual Residual Reinforcement Learning for Contact-Rich Tasks Using a Torque-Controlled Robot
Oct 25, 2020

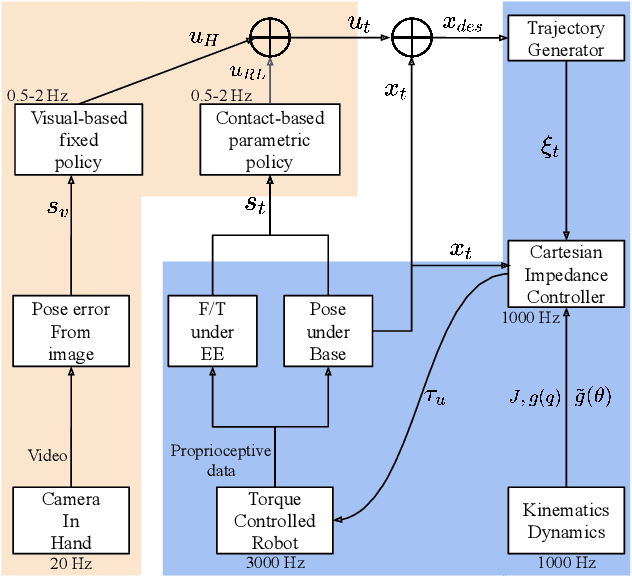
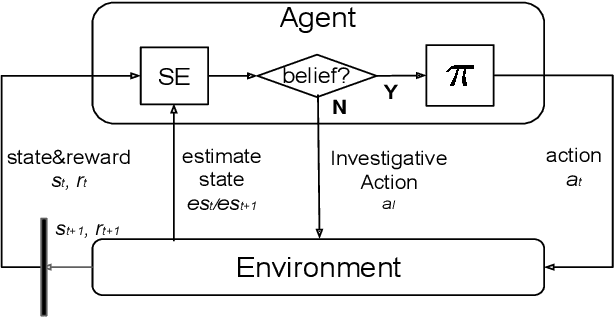
Contact-rich manipulation tasks are commonly found in modern manufacturing settings. However, manually designing a robot controller is considered hard for traditional control methods as the controller requires an effective combination of modalities and vastly different characteristics. In this paper, we firstly consider incorporating operational space visual and haptic information into reinforcement learning(RL) methods to solve the target uncertainty problem in unstructured environments. Moreover, we propose a novel idea of introducing a proactive action to solve the partially observable Markov decision process problem. Together with these two ideas, our method can either adapt to reasonable variations in unstructured environments and improve the sample efficiency of policy learning. We evaluated our method on a task that involved inserting a random-access memory using a torque-controlled robot, and we tested the success rates of the different baselines used in the traditional methods. We proved that our method is robust and can tolerate environmental variations very well.