 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-to-Real Transfer of Robotic Assembly with Visual Inputs Using CycleGAN and Force Control
Aug 30, 2022
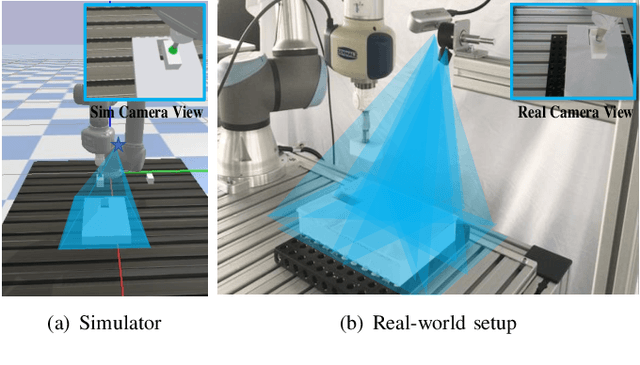
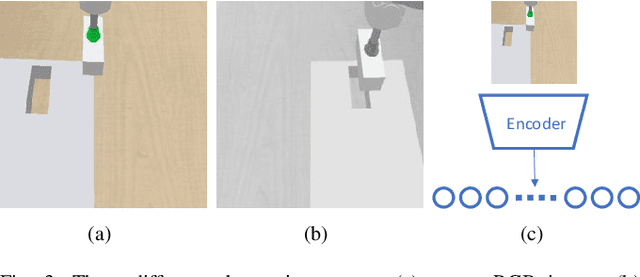
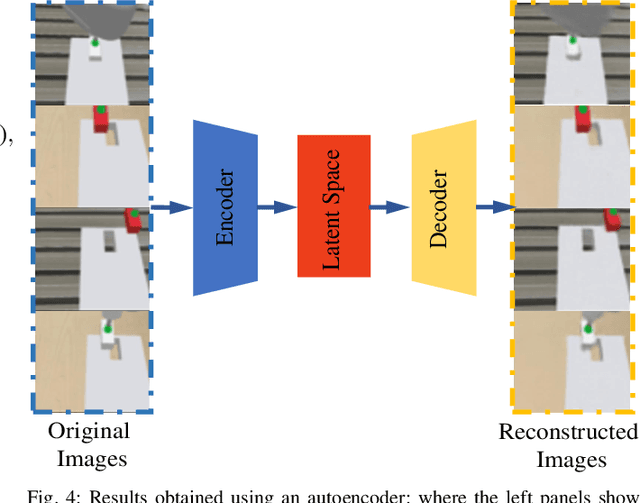
Recently, deep reinforcement learning (RL) has shown some impressive successes in robotic manipulation applications. However, training robots in the real world is nontrivial owing to sample efficiency and safety concerns. Sim-to-real transfer is proposed to address the aforementioned concerns but introduces a new issue called the reality gap. In this work, we introduce a sim-to-real learning framework for vision-based assembly tasks and perform training in a simulated environment by employing inputs from a single camera to address the aforementioned issues. We present a domain adaptation method based on cycle-consistent generative adversarial networks (CycleGAN) and a force control transfer approach to bridge the reality gap. We demonstrate that the proposed framework trained in a simulated environment can be successfully transferred to a real peg-in-hole setup.
Maximizing the Use of Environmental Constraints: A Pushing-Based Hybrid Position/Force Assembly Skill for Contact-Rich Tasks
Aug 12, 2022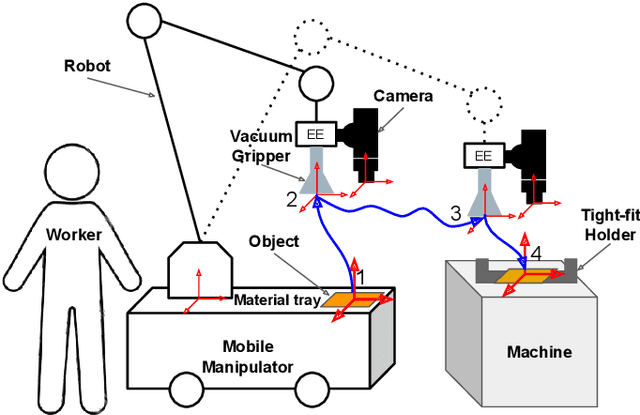
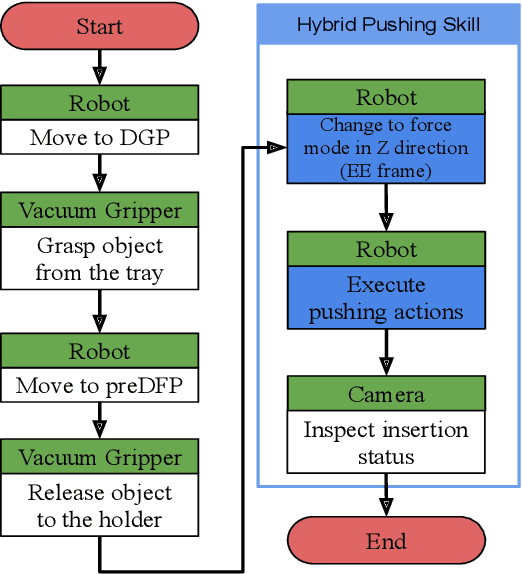
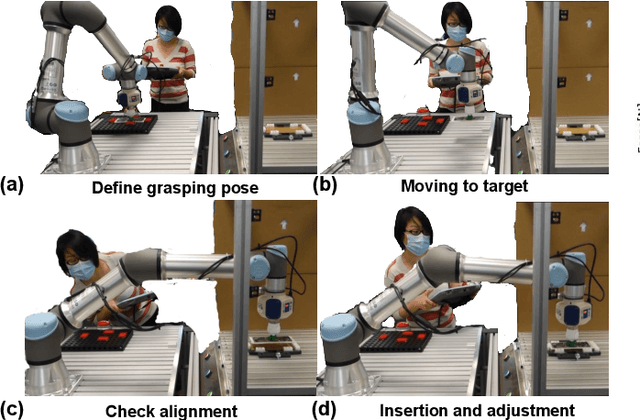
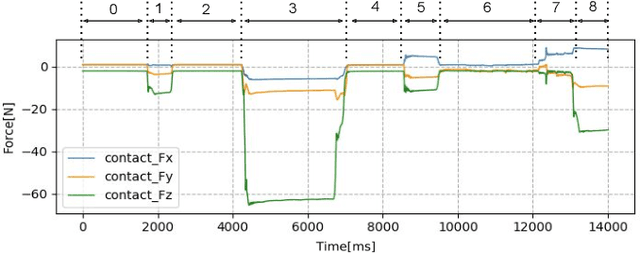
The need for contact-rich tasks is rapidly growing in modern manufacturing settings. However, few traditional robotic assembly skills consider environmental constraints during task execution, and most of them use these constraints as termination conditions. In this study, we present a pushing-based hybrid position/force assembly skill that can maximize environmental constraints during task execution. To the best of our knowledge, this is the first work that considers using pushing actions during the execution of the assembly tasks. We have proved that our skill can maximize the utilization of environmental constraints using mobile manipulator system assembly task experiments, and achieve a 100\% success rate in the executions.
Impedance Adaptation by Reinforcement Learning with Contact Dynamic Movement Primitives
Mar 21, 2022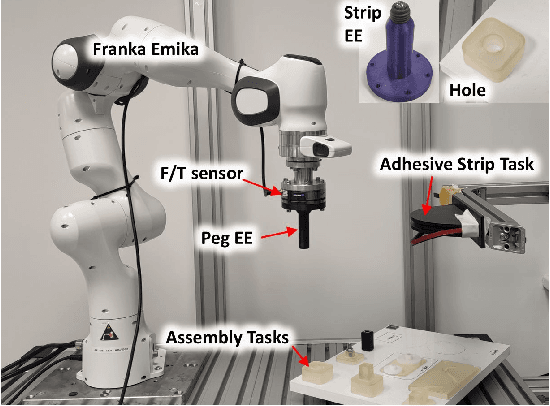
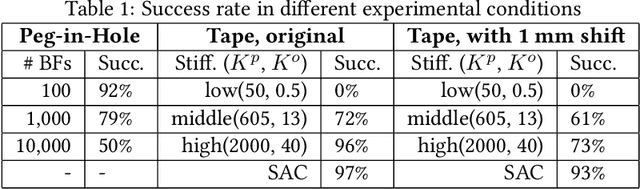
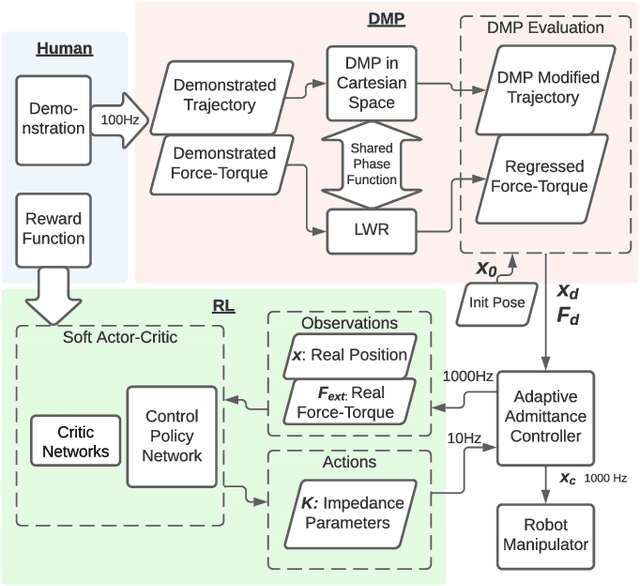
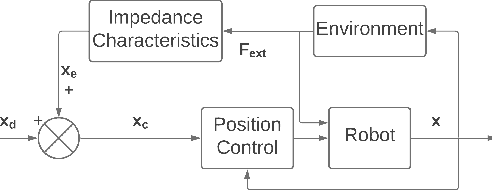
Dynamic movement primitives (DMPs) allow complex position trajectories to be efficiently demonstrated to a robot. In contact-rich tasks, where position trajectories alone may not be safe or robust over variation in contact geometry, DMPs have been extended to include force trajectories. However, different task phases or degrees of freedom may require the tracking of either position or force -- e.g., once contact is made, it may be more important to track the force demonstration trajectory in the contact direction. The robot impedance balances between following a position or force reference trajectory, where a high stiffness tracks position and a low stiffness tracks force. This paper proposes using DMPs to learn position and force trajectories from demonstrations, then adapting the impedance parameters online with a higher-level control policy trained by reinforcement learning. This allows one-shot demonstration of the task with DMPs, and improved robustness and performance from the impedance adaptation. The approach is validated on peg-in-hole and adhesive strip application tasks.