 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Continuous Colormap Recovery from a 2D Scalar Field Visualization without a Legend
Jul 28, 2025Recovering a continuous colormap from a single 2D scalar field visualization can be quite challenging, especially in the absence of a corresponding color legend. In this paper, we propose a novel colormap recovery approach that extracts the colormap from a color-encoded 2D scalar field visualization by simultaneously predicting the colormap and underlying data using a decoupling-and-reconstruction strategy. Our approach first separates the input visualization into colormap and data using a decoupling module, then reconstructs the visualization with a differentiable color-mapping module. To guide this process, we design a reconstruction loss between the input and reconstructed visualizations, which serves both as a constraint to ensure strong correlation between colormap and data during training, and as a self-supervised optimizer for fine-tuning the predicted colormap of unseen visualizations during inferencing. To ensure smoothness and correct color ordering in the extracted colormap, we introduce a compact colormap representation using cubic B-spline curves and an associated color order loss. We evaluate our method quantitatively and qualitatively on a synthetic dataset and a collection of real-world visualizations from the VIS30K dataset. Additionally, we demonstrate its utility in two prototype applications -- colormap adjustment and colormap transfer -- and explore its generalization to visualizations with color legends and ones encoded using discrete color palettes.
Combining Learning from Demonstration with Learning by Exploration to Facilitate Contact-Rich Tasks
Mar 10, 2021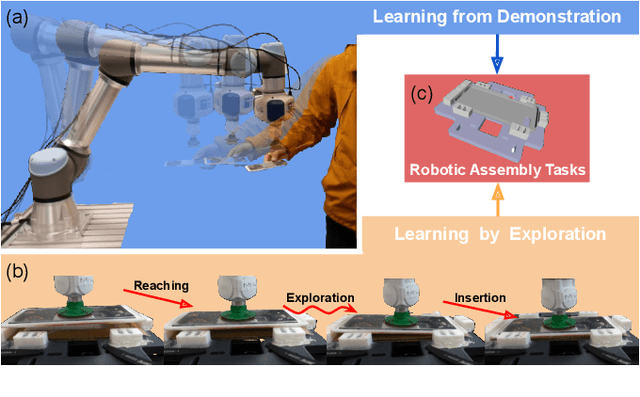

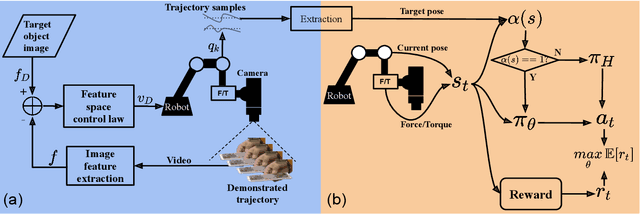

Collaborative robots are expected to be able to work alongside humans and in some cases directly replace existing human workers, thus effectively responding to rapid assembly line changes. Current methods for programming contact-rich tasks, especially in heavily constrained space, tend to be fairly inefficient. Therefore, faster and more intuitive approaches to robot teaching are urgently required. This work focuses on combining visual servoing based learning from demonstration (LfD) and force-based learning by exploration (LbE), to enable fast and intuitive programming of contact-rich tasks with minimal user effort required. Two learning approaches were developed and integrated into a framework, and one relying on human to robot motion mapping (the visual servoing approach) and one on force-based reinforcement learning. The developed framework implements the non-contact demonstration teaching method based on visual servoing approach and optimizes the demonstrated robot target positions according to the detected contact state. The framework has been compared with two most commonly used baseline techniques, pendant-based teaching and hand-guiding teaching. The efficiency and reliability of the framework have been validated through comparison experiments involving the teaching and execution of contact-rich tasks. The framework proposed in this paper has performed the best in terms of teaching time, execution success rate, risk of damage, and ease of use.
Proactive Action Visual Residual Reinforcement Learning for Contact-Rich Tasks Using a Torque-Controlled Robot
Oct 25, 2020

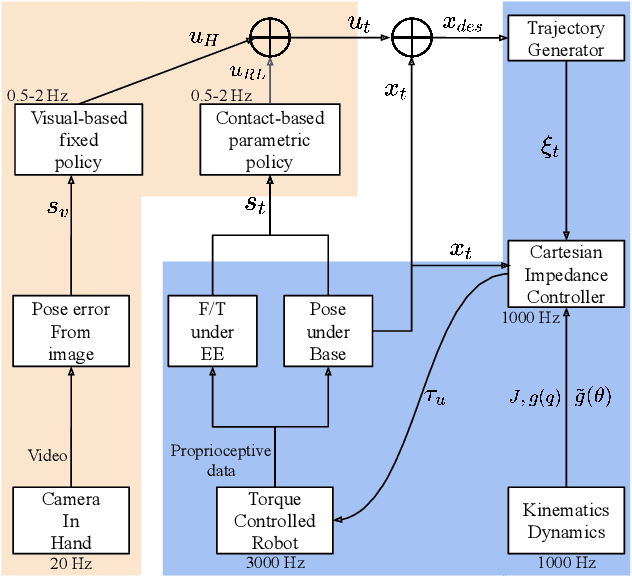
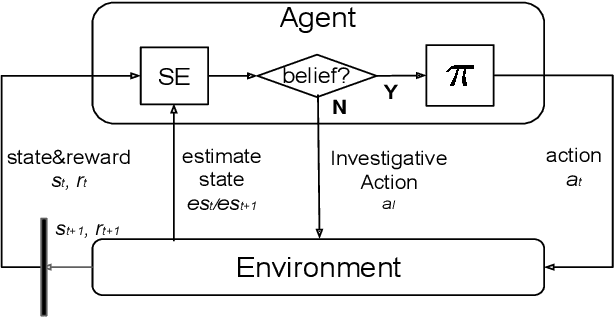
Contact-rich manipulation tasks are commonly found in modern manufacturing settings. However, manually designing a robot controller is considered hard for traditional control methods as the controller requires an effective combination of modalities and vastly different characteristics. In this paper, we firstly consider incorporating operational space visual and haptic information into reinforcement learning(RL) methods to solve the target uncertainty problem in unstructured environments. Moreover, we propose a novel idea of introducing a proactive action to solve the partially observable Markov decision process problem. Together with these two ideas, our method can either adapt to reasonable variations in unstructured environments and improve the sample efficiency of policy learning. We evaluated our method on a task that involved inserting a random-access memory using a torque-controlled robot, and we tested the success rates of the different baselines used in the traditional methods. We proved that our method is robust and can tolerate environmental variations very well.