 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
Exploring Human-AI Conceptual Alignment through the Prism of Chess
Oct 29, 2025Do AI systems truly understand human concepts or merely mimic surface patterns? We investigate this through chess, where human creativity meets precise strategic concepts. Analyzing a 270M-parameter transformer that achieves grandmaster-level play, we uncover a striking paradox: while early layers encode human concepts like center control and knight outposts with up to 85\% accuracy, deeper layers, despite driving superior performance, drift toward alien representations, dropping to 50-65\% accuracy. To test conceptual robustness beyond memorization, we introduce the first Chess960 dataset: 240 expert-annotated positions across 6 strategic concepts. When opening theory is eliminated through randomized starting positions, concept recognition drops 10-20\% across all methods, revealing the model's reliance on memorized patterns rather than abstract understanding. Our layer-wise analysis exposes a fundamental tension in current architectures: the representations that win games diverge from those that align with human thinking. These findings suggest that as AI systems optimize for performance, they develop increasingly alien intelligence, a critical challenge for creative AI applications requiring genuine human-AI collaboration. Dataset and code are available at: https://github.com/slomasov/ChessConceptsLLM.
Addition in Four Movements: Mapping Layer-wise Information Trajectories in LLMs
Jun 09, 2025Multi-digit addition is a clear probe of the computational power of large language models. To dissect the internal arithmetic processes in LLaMA-3-8B-Instruct, we combine linear probing with logit-lens inspection. Inspired by the step-by-step manner in which humans perform addition, we propose and analyze a coherent four-stage trajectory in the forward pass:Formula-structure representations become linearly decodable first, while the answer token is still far down the candidate list.Core computational features then emerge prominently.At deeper activation layers, numerical abstractions of the result become clearer, enabling near-perfect detection and decoding of the individual digits in the sum.Near the output, the model organizes and generates the final content, with the correct token reliably occupying the top rank.This trajectory suggests a hierarchical process that favors internal computation over rote memorization. We release our code and data to facilitate reproducibility.
A Multifaceted Benchmarking of Synthetic Electronic Health Record Generation Models
Aug 02, 2022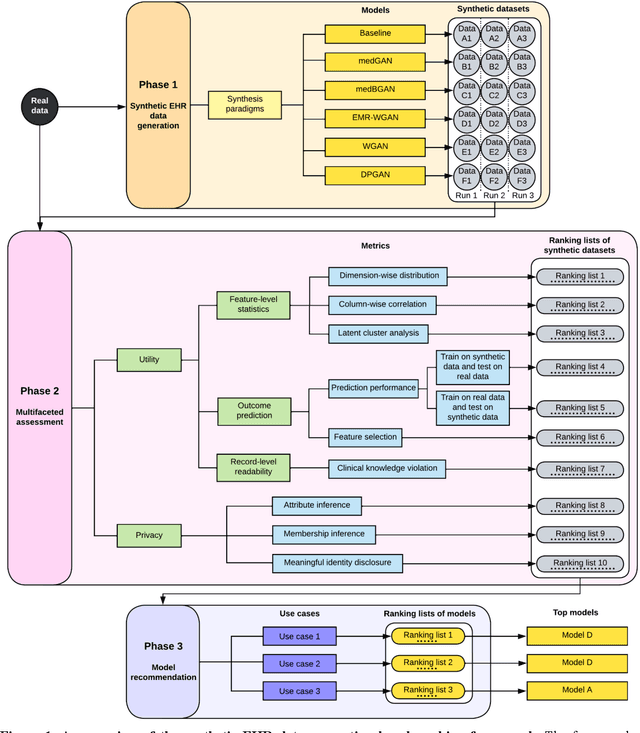
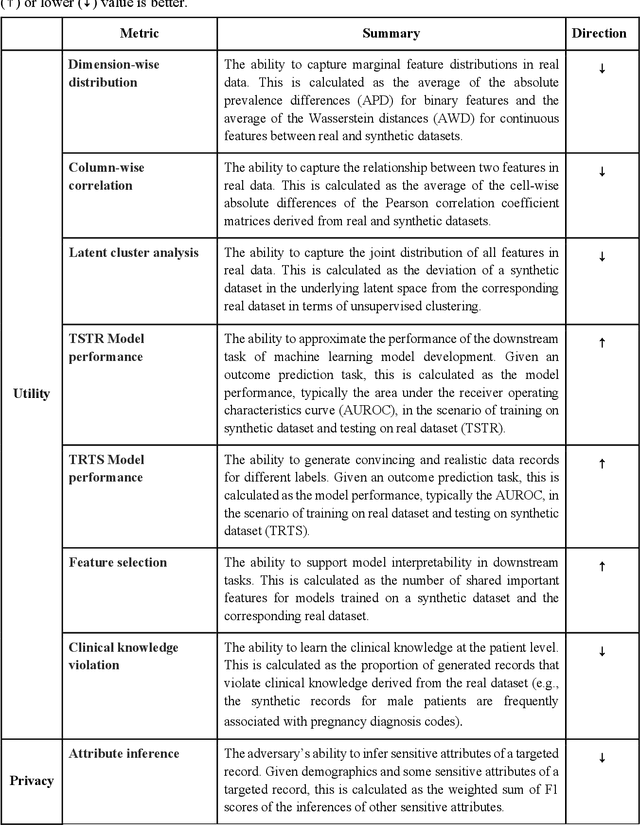


Synthetic health data have the potential to mitigate privacy concerns when sharing data to support biomedical research and the development of innovative healthcare applications. Modern approaches for data generation based on machine learning, generative adversarial networks (GAN) methods in particular, continue to evolve and demonstrate remarkable potential. Yet there is a lack of a systematic assessment framework to benchmark methods as they emerge and determine which methods are most appropriate for which use cases. In this work, we introduce a generalizable benchmarking framework to appraise key characteristics of synthetic health data with respect to utility and privacy metrics. We apply the framework to evaluate synthetic data generation methods for electronic health records (EHRs) data from two large academic medical centers with respect to several use cases. The results illustrate that there is a utility-privacy tradeoff for sharing synthetic EHR data. The results further indicate that no method is unequivocally the best on all criteria in each use case, which makes it evident why synthetic data generation methods need to be assessed in context.
The NLP Sandbox: an efficient model-to-data system to enable federated and unbiased evaluation of clinical NLP models
Jun 28, 2022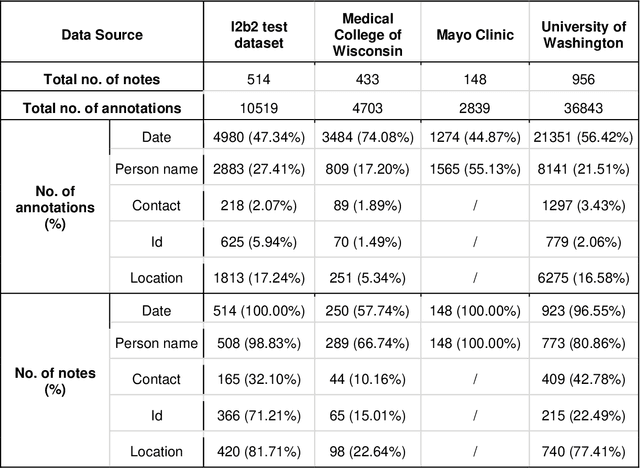
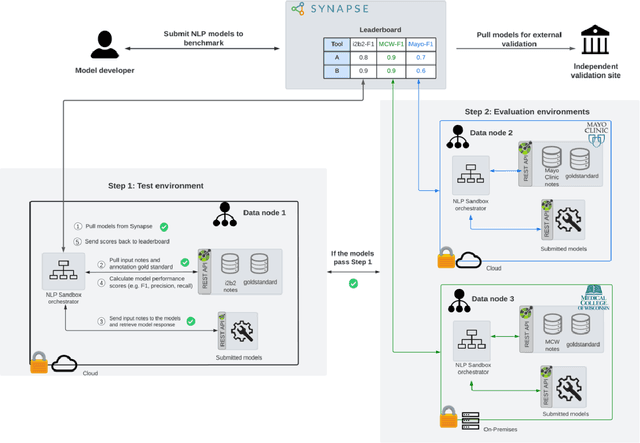
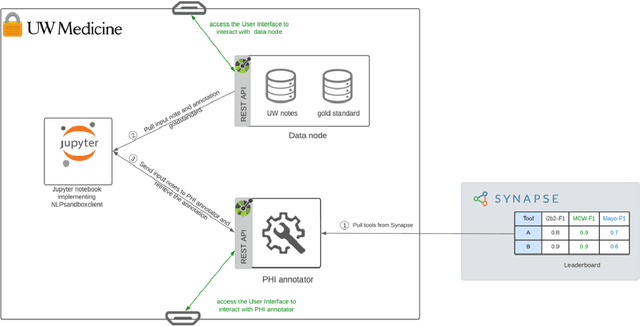
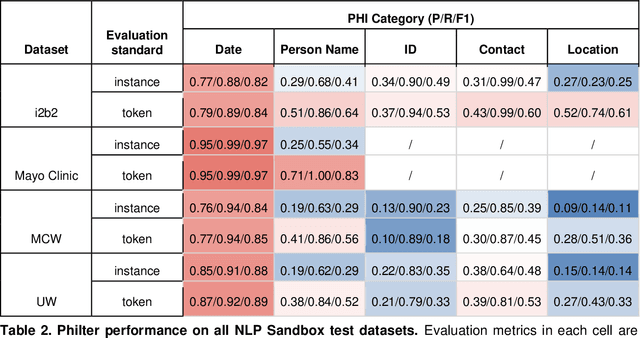
Objective The evaluation of natural language processing (NLP) models for clinical text de-identification relies on the availability of clinical notes, which is often restricted due to privacy concerns. The NLP Sandbox is an approach for alleviating the lack of data and evaluation frameworks for NLP models by adopting a federated, model-to-data approach. This enables unbiased federated model evaluation without the need for sharing sensitive data from multiple institutions. Materials and Methods We leveraged the Synapse collaborative framework, containerization software, and OpenAPI generator to build the NLP Sandbox (nlpsandbox.io). We evaluated two state-of-the-art NLP de-identification focused annotation models, Philter and NeuroNER, using data from three institutions. We further validated model performance using data from an external validation site. Results We demonstrated the usefulness of the NLP Sandbox through de-identification clinical model evaluation. The external developer was able to incorporate their model into the NLP Sandbox template and provide user experience feedback. Discussion We demonstrated the feasibility of using the NLP Sandbox to conduct a multi-site evaluation of clinical text de-identification models without the sharing of data. Standardized model and data schemas enable smooth model transfer and implementation. To generalize the NLP Sandbox, work is required on the part of data owners and model developers to develop suitable and standardized schemas and to adapt their data or model to fit the schemas. Conclusions The NLP Sandbox lowers the barrier to utilizing clinical data for NLP model evaluation and facilitates federated, multi-site, unbiased evaluation of NLP models.