 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe NLP Sandbox: an efficient model-to-data system to enable federated and unbiased evaluation of clinical NLP models
Jun 28, 2022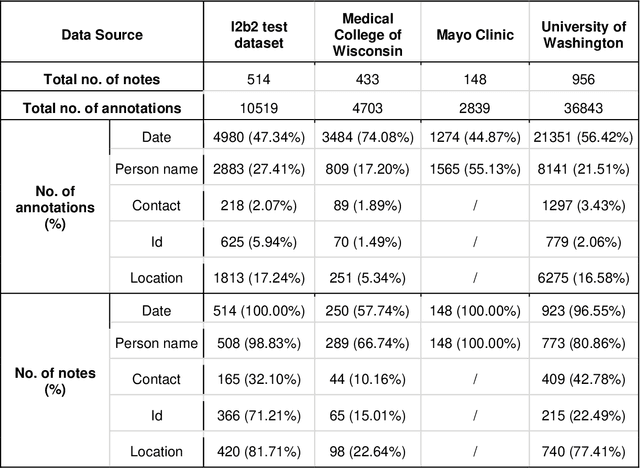
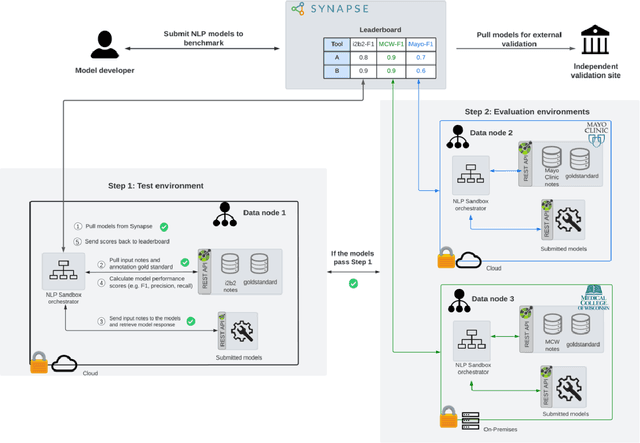
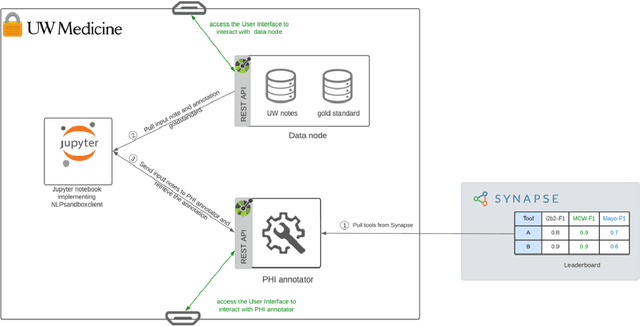
Objective The evaluation of natural language processing (NLP) models for clinical text de-identification relies on the availability of clinical notes, which is often restricted due to privacy concerns. The NLP Sandbox is an approach for alleviating the lack of data and evaluation frameworks for NLP models by adopting a federated, model-to-data approach. This enables unbiased federated model evaluation without the need for sharing sensitive data from multiple institutions. Materials and Methods We leveraged the Synapse collaborative framework, containerization software, and OpenAPI generator to build the NLP Sandbox (nlpsandbox.io). We evaluated two state-of-the-art NLP de-identification focused annotation models, Philter and NeuroNER, using data from three institutions. We further validated model performance using data from an external validation site. Results We demonstrated the usefulness of the NLP Sandbox through de-identification clinical model evaluation. The external developer was able to incorporate their model into the NLP Sandbox template and provide user experience feedback. Discussion We demonstrated the feasibility of using the NLP Sandbox to conduct a multi-site evaluation of clinical text de-identification models without the sharing of data. Standardized model and data schemas enable smooth model transfer and implementation. To generalize the NLP Sandbox, work is required on the part of data owners and model developers to develop suitable and standardized schemas and to adapt their data or model to fit the schemas. Conclusions The NLP Sandbox lowers the barrier to utilizing clinical data for NLP model evaluation and facilitates federated, multi-site, unbiased evaluation of NLP models.
Performance of Automatic De-identification Across Different Note Types
Feb 17, 2021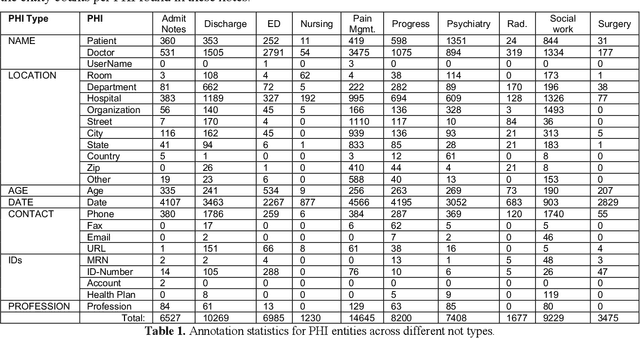
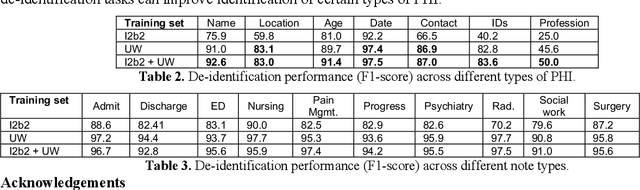
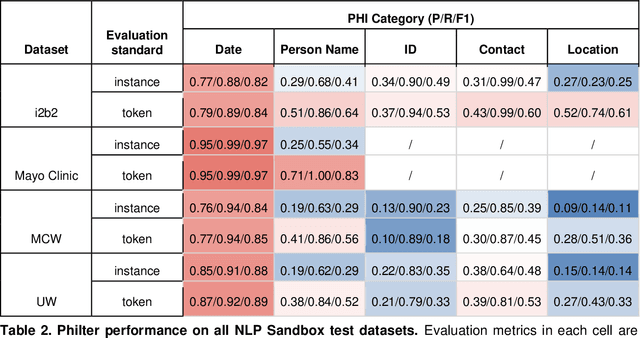
Free-text clinical notes detail all aspects of patient care and have great potential to facilitate quality improvement and assurance initiatives as well as advance clinical research. However, concerns about patient privacy and confidentiality limit the use of clinical notes for research. As a result, the information documented in these notes remains unavailable for most researchers. De-identification (de-id), i.e., locating and removing personally identifying protected health information (PHI), is one way of improving access to clinical narratives. However, there are limited off-the-shelf de-identification systems able to consistently detect PHI across different data sources and medical specialties. In this abstract, we present the performance of a state-of-the art de-id system called NeuroNER1 on a diverse set of notes from University of Washington (UW) when the models are trained on data from an external institution (Partners Healthcare) vs. from the same institution (UW). We present results at the level of PHI and note types.