 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Competitions and Benchmarks, Practical issues: Proposals, grant money, sponsors, prizes, dissemination, publicity
Jan 09, 2024This chapter provides a comprehensive overview of the pragmatic aspects involved in organizing AI competitions. We begin by discussing strategies to incentivize participation, touching upon effective communication techniques, aligning with trending topics in the field, structuring awards, potential recruitment opportunities, and more. We then shift to the essence of community engagement, and into organizational best practices and effective means of disseminating challenge outputs. Lastly, the chapter addresses the logistics, exposing on costs, required manpower, and resource allocation for effectively managing and executing a challenge. By examining these practical problems, readers will gain actionable insights to navigate the multifaceted landscape of AI competition organization, from inception to completion.
A Multifaceted Benchmarking of Synthetic Electronic Health Record Generation Models
Aug 02, 2022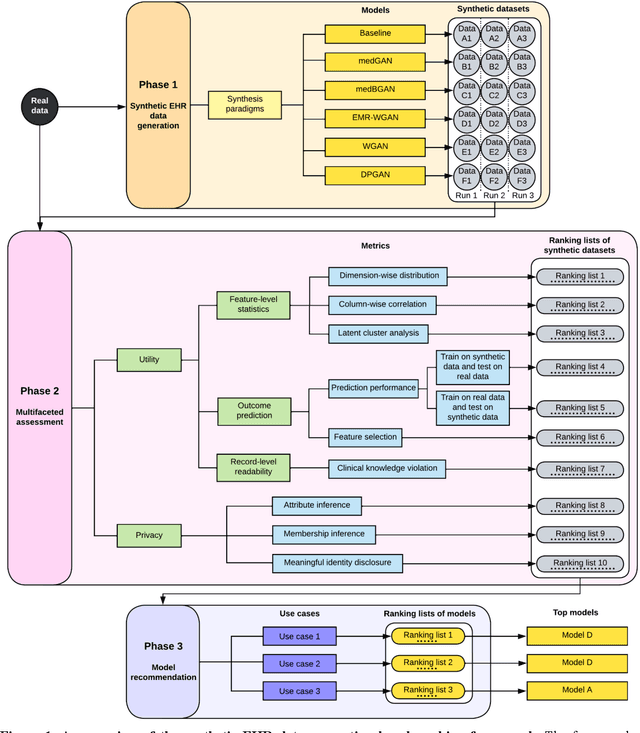
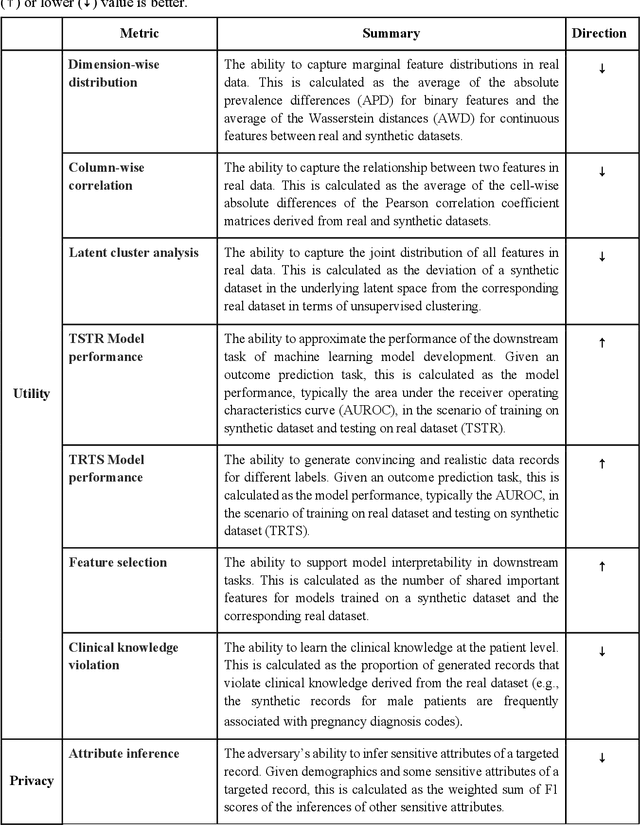


Synthetic health data have the potential to mitigate privacy concerns when sharing data to support biomedical research and the development of innovative healthcare applications. Modern approaches for data generation based on machine learning, generative adversarial networks (GAN) methods in particular, continue to evolve and demonstrate remarkable potential. Yet there is a lack of a systematic assessment framework to benchmark methods as they emerge and determine which methods are most appropriate for which use cases. In this work, we introduce a generalizable benchmarking framework to appraise key characteristics of synthetic health data with respect to utility and privacy metrics. We apply the framework to evaluate synthetic data generation methods for electronic health records (EHRs) data from two large academic medical centers with respect to several use cases. The results illustrate that there is a utility-privacy tradeoff for sharing synthetic EHR data. The results further indicate that no method is unequivocally the best on all criteria in each use case, which makes it evident why synthetic data generation methods need to be assessed in context.
The NLP Sandbox: an efficient model-to-data system to enable federated and unbiased evaluation of clinical NLP models
Jun 28, 2022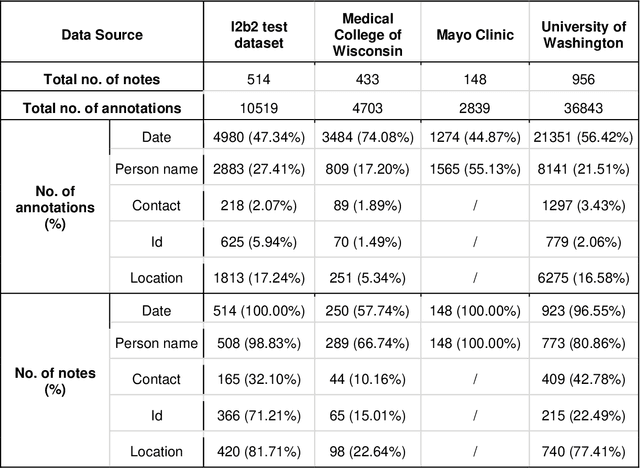
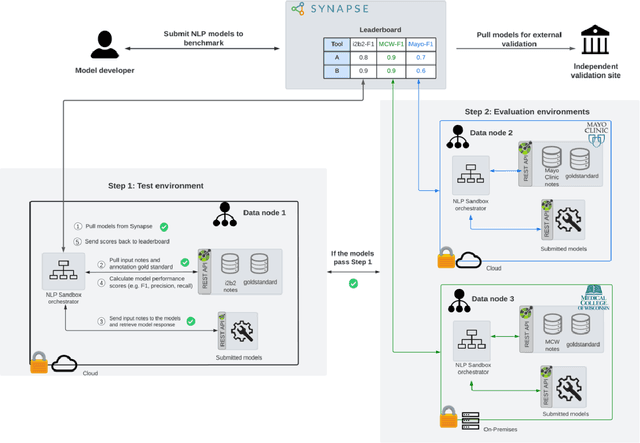
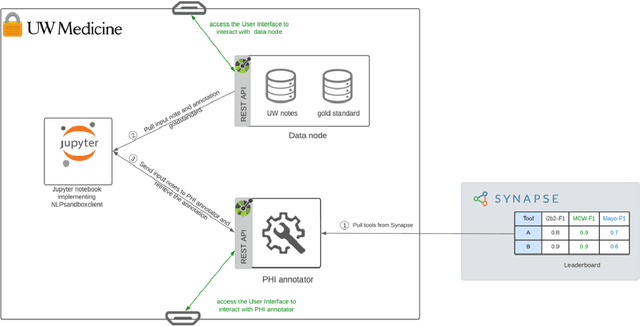
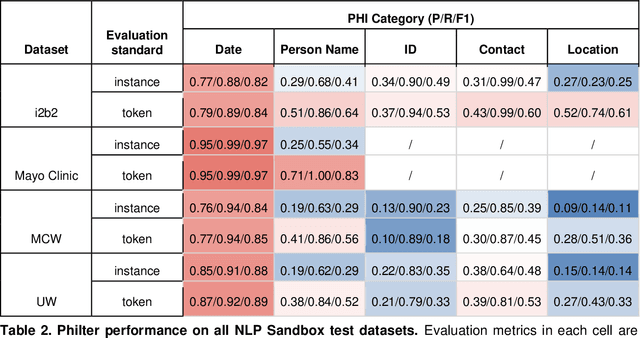
Objective The evaluation of natural language processing (NLP) models for clinical text de-identification relies on the availability of clinical notes, which is often restricted due to privacy concerns. The NLP Sandbox is an approach for alleviating the lack of data and evaluation frameworks for NLP models by adopting a federated, model-to-data approach. This enables unbiased federated model evaluation without the need for sharing sensitive data from multiple institutions. Materials and Methods We leveraged the Synapse collaborative framework, containerization software, and OpenAPI generator to build the NLP Sandbox (nlpsandbox.io). We evaluated two state-of-the-art NLP de-identification focused annotation models, Philter and NeuroNER, using data from three institutions. We further validated model performance using data from an external validation site. Results We demonstrated the usefulness of the NLP Sandbox through de-identification clinical model evaluation. The external developer was able to incorporate their model into the NLP Sandbox template and provide user experience feedback. Discussion We demonstrated the feasibility of using the NLP Sandbox to conduct a multi-site evaluation of clinical text de-identification models without the sharing of data. Standardized model and data schemas enable smooth model transfer and implementation. To generalize the NLP Sandbox, work is required on the part of data owners and model developers to develop suitable and standardized schemas and to adapt their data or model to fit the schemas. Conclusions The NLP Sandbox lowers the barrier to utilizing clinical data for NLP model evaluation and facilitates federated, multi-site, unbiased evaluation of NLP models.