 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Competitions and Benchmarks, Practical issues: Proposals, grant money, sponsors, prizes, dissemination, publicity
Jan 09, 2024This chapter provides a comprehensive overview of the pragmatic aspects involved in organizing AI competitions. We begin by discussing strategies to incentivize participation, touching upon effective communication techniques, aligning with trending topics in the field, structuring awards, potential recruitment opportunities, and more. We then shift to the essence of community engagement, and into organizational best practices and effective means of disseminating challenge outputs. Lastly, the chapter addresses the logistics, exposing on costs, required manpower, and resource allocation for effectively managing and executing a challenge. By examining these practical problems, readers will gain actionable insights to navigate the multifaceted landscape of AI competition organization, from inception to completion.
AI Competitions and Benchmarks: The life cycle of challenges and benchmarks
Dec 08, 2023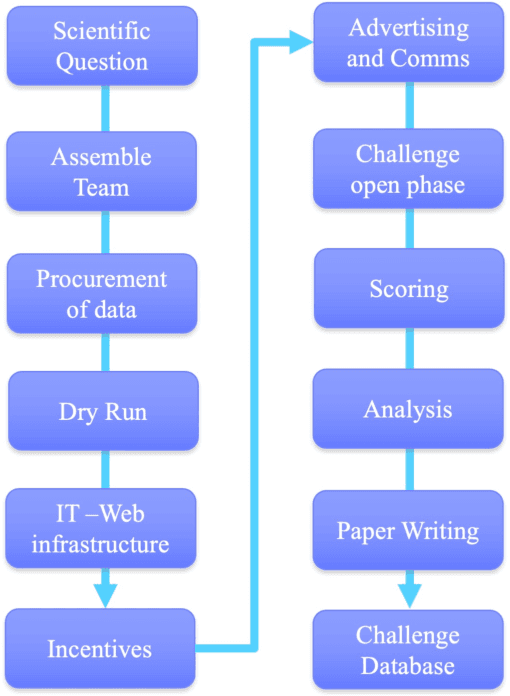
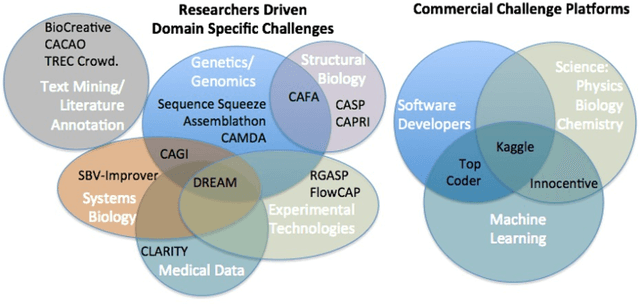
Data Science research is undergoing a revolution fueled by the transformative power of technology, the Internet, and an ever increasing computational capacity. The rate at which sophisticated algorithms can be developed is unprecedented, yet they remain outpaced by the massive amounts of data that are increasingly available to researchers. Here we argue for the need to creatively leverage the scientific research and algorithm development community as an axis of robust innovation. Engaging these communities in the scientific discovery enterprise by critical assessments, community experiments, and/or crowdsourcing will multiply opportunities to develop new data driven, reproducible and well benchmarked algorithmic solutions to fundamental and applied problems of current interest. Coordinated community engagement in the analysis of highly complex and massive data has emerged as one approach to find robust methodologies that best address these challenges. When community engagement is done in the form of competitions, also known as challenges, the validation of the analytical methodology is inherently addressed, establishing performance benchmarks. Finally, challenges foster open innovation across multiple disciplines to create communities that collaborate directly or indirectly to address significant scientific gaps. Together, participants can solve important problems as varied as health research, climate change, and social equity. Ultimately, challenges can catalyze and accelerate the synthesis of complex data into knowledge or actionable information, and should be viewed a powerful tool to make lasting social and research contributions.
Unsupervised Evaluation and Weighted Aggregation of Ranked Predictions
Feb 13, 2018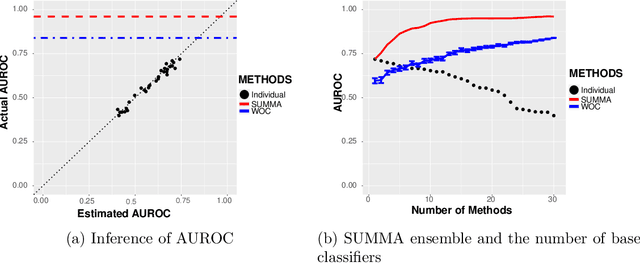
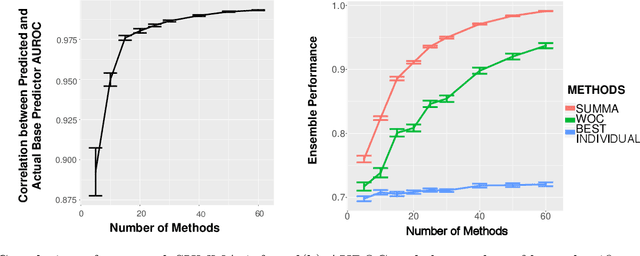
Learning algorithms that aggregate predictions from an ensemble of diverse base classifiers consistently outperform individual methods. Many of these strategies have been developed in a supervised setting, where the accuracy of each base classifier can be empirically measured and this information is incorporated in the training process. However, the reliance on labeled data precludes the application of ensemble methods to many real world problems where labeled data has not been curated. To this end we developed a new theoretical framework for binary classification, the Strategy for Unsupervised Multiple Method Aggregation (SUMMA), to estimate the performances of base classifiers and an optimal strategy for ensemble learning from unlabeled data.