 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Competitions and Benchmarks, Practical issues: Proposals, grant money, sponsors, prizes, dissemination, publicity
Jan 09, 2024This chapter provides a comprehensive overview of the pragmatic aspects involved in organizing AI competitions. We begin by discussing strategies to incentivize participation, touching upon effective communication techniques, aligning with trending topics in the field, structuring awards, potential recruitment opportunities, and more. We then shift to the essence of community engagement, and into organizational best practices and effective means of disseminating challenge outputs. Lastly, the chapter addresses the logistics, exposing on costs, required manpower, and resource allocation for effectively managing and executing a challenge. By examining these practical problems, readers will gain actionable insights to navigate the multifaceted landscape of AI competition organization, from inception to completion.
Codabench: Flexible, Easy-to-Use and Reproducible Benchmarking for Everyone
Oct 12, 2021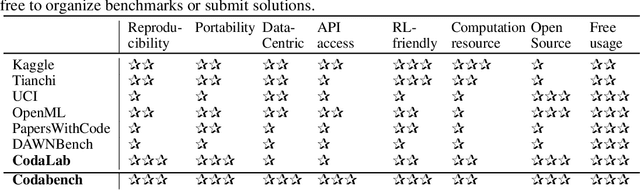
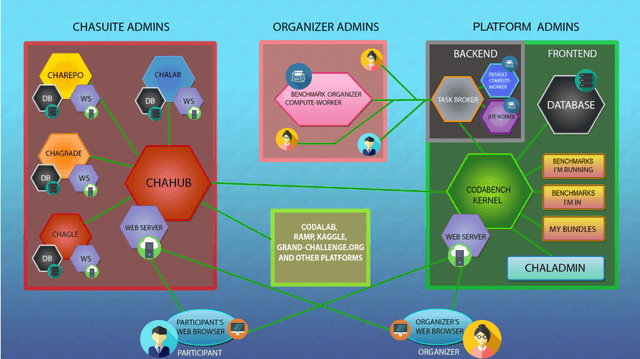
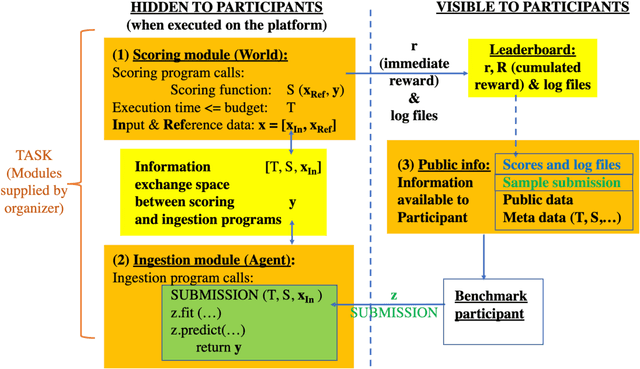
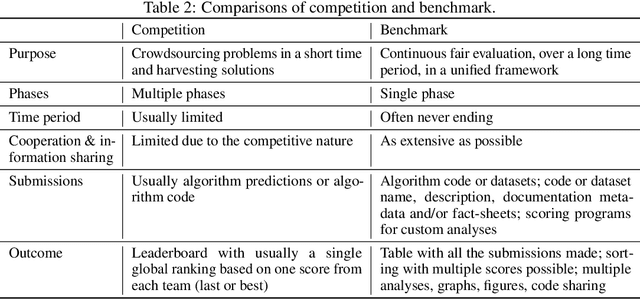
Obtaining standardized crowdsourced benchmark of computational methods is a major issue in scientific communities. Dedicated frameworks enabling fair continuous benchmarking in a unified environment are yet to be developed. Here we introduce Codabench, an open-sourced, community-driven platform for benchmarking algorithms or software agents versus datasets or tasks. A public instance of Codabench is open to everyone, free of charge, and allows benchmark organizers to compare fairly submissions, under the same setting (software, hardware, data, algorithms), with custom protocols and data formats. Codabench has unique features facilitating the organization of benchmarks flexibly, easily and reproducibly. Firstly, it supports code submission and data submission for testing on dedicated compute workers, which can be supplied by the benchmark organizers. This makes the system scalable, at low cost for the platform providers. Secondly, Codabench benchmarks are created from self-contained bundles, which are zip files containing a full description of the benchmark in a configuration file (following a well-defined schema), documentation pages, data, ingestion and scoring programs, making benchmarks reusable and portable. The Codabench documentation includes many examples of bundles that can serve as templates. Thirdly, Codabench uses dockers for each task's running environment to make results reproducible. Codabench has been used internally and externally with more than 10 applications during the past 6 months. As illustrative use cases, we introduce 4 diverse benchmarks covering Graph Machine Learning, Cancer Heterogeneity, Clinical Diagnosis and Reinforcement Learning.