 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Budget Allocation in Multi-Task Learning
Aug 24, 2023The cost of labeling data often limits the performance of machine learning systems. In multi-task learning, related tasks provide information to each other and improve overall performance, but the label cost can vary among tasks. How should the label budget (i.e. the amount of money spent on labeling) be allocated among different tasks to achieve optimal multi-task performance? We are the first to propose and formally define the label budget allocation problem in multi-task learning and to empirically show that different budget allocation strategies make a big difference to its performance. We propose a Task-Adaptive Budget Allocation algorithm to robustly generate the optimal budget allocation adaptive to different multi-task learning settings. Specifically, we estimate and then maximize the extent of new information obtained from the allocated budget as a proxy for multi-task learning performance. Experiments on PASCAL VOC and Taskonomy demonstrate the efficacy of our approach over other widely used heuristic labeling strategies.
PseudoSeg: Designing Pseudo Labels for Semantic Segmentation
Oct 19, 2020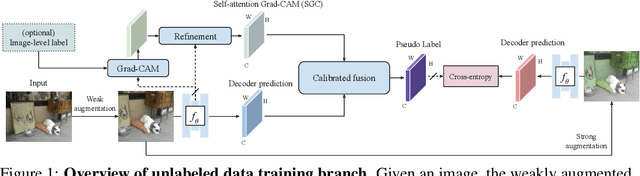
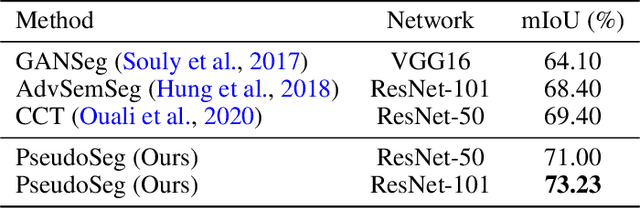

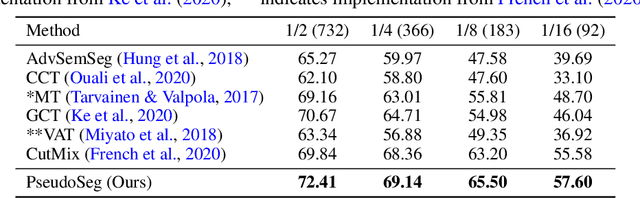
Recent advances in semi-supervised learning (SSL) demonstrate that a combination of consistency regularization and pseudo-labeling can effectively improve image classification accuracy in the low-data regime. Compared to classification, semantic segmentation tasks require much more intensive labeling costs. Thus, these tasks greatly benefit from data-efficient training methods. However, structured outputs in segmentation render particular difficulties (e.g., designing pseudo-labeling and augmentation) to apply existing SSL strategies. To address this problem, we present a simple and novel re-design of pseudo-labeling to generate well-calibrated structured pseudo labels for training with unlabeled or weakly-labeled data. Our proposed pseudo-labeling strategy is network structure agnostic to apply in a one-stage consistency training framework. We demonstrate the effectiveness of the proposed pseudo-labeling strategy in both low-data and high-data regimes. Extensive experiments have validated that pseudo labels generated from wisely fusing diverse sources and strong data augmentation are crucial to consistency training for segmentation. The source code is available at https://github.com/googleinterns/wss.
Feature Space Augmentation for Long-Tailed Data
Aug 09, 2020
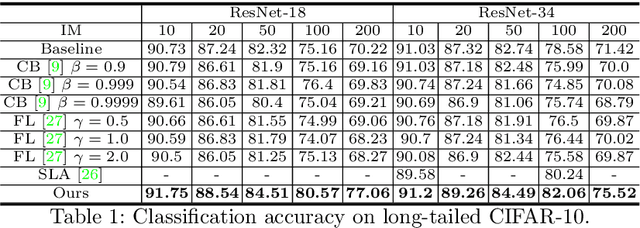
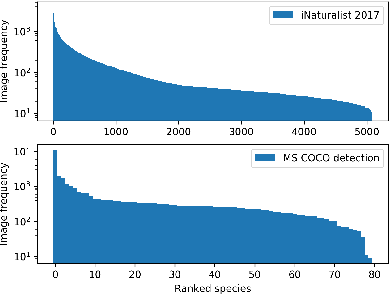
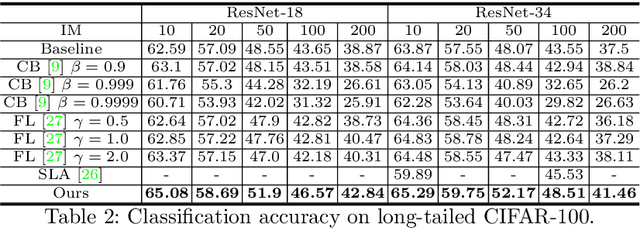
Real-world data often follow a long-tailed distribution as the frequency of each class is typically different. For example, a dataset can have a large number of under-represented classes and a few classes with more than sufficient data. However, a model to represent the dataset is usually expected to have reasonably homogeneous performances across classes. Introducing class-balanced loss and advanced methods on data re-sampling and augmentation are among the best practices to alleviate the data imbalance problem. However, the other part of the problem about the under-represented classes will have to rely on additional knowledge to recover the missing information. In this work, we present a novel approach to address the long-tailed problem by augmenting the under-represented classes in the feature space with the features learned from the classes with ample samples. In particular, we decompose the features of each class into a class-generic component and a class-specific component using class activation maps. Novel samples of under-represented classes are then generated on the fly during training stages by fusing the class-specific features from the under-represented classes with the class-generic features from confusing classes. Our results on different datasets such as iNaturalist, ImageNet-LT, Places-LT and a long-tailed version of CIFAR have shown the state of the art performances.
Vision Meets Drones: Past, Present and Future
Jan 16, 2020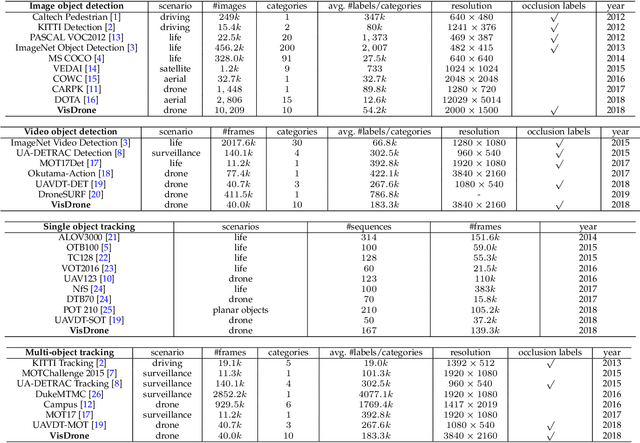
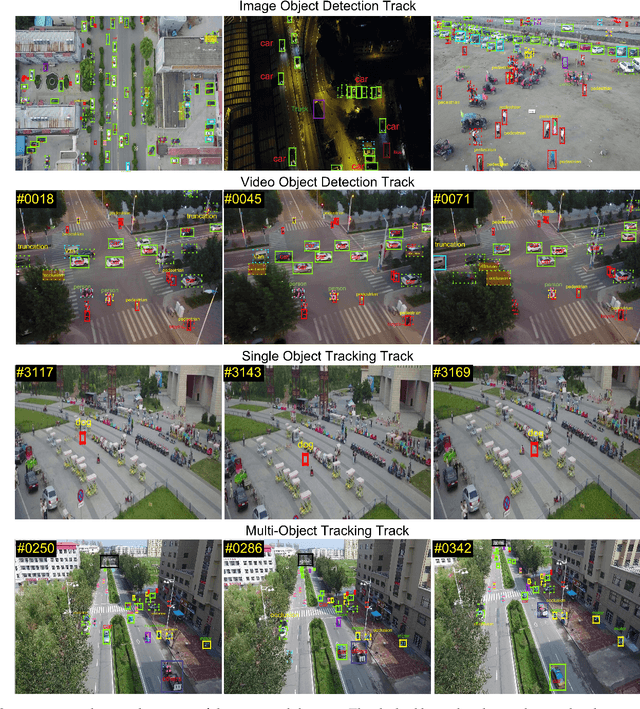
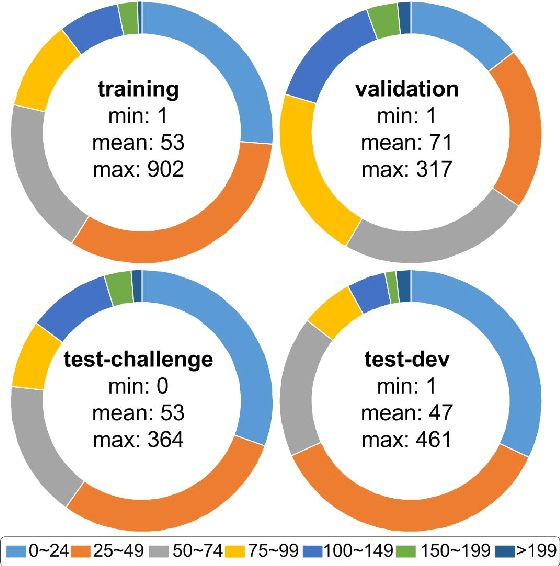
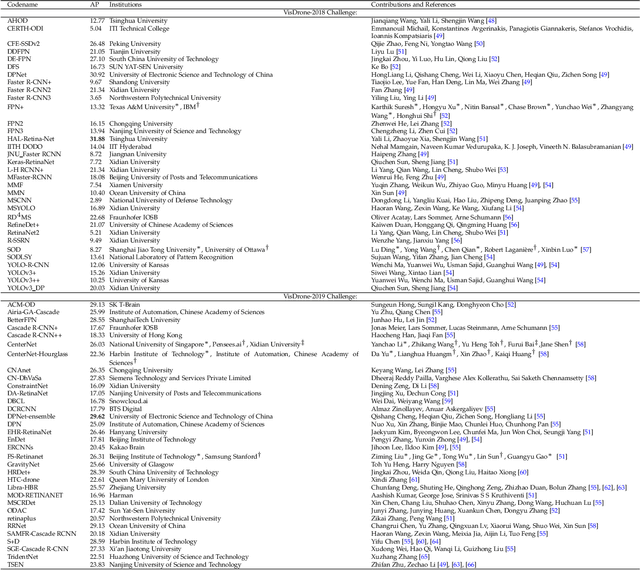
Drones, or general UAVs, equipped with cameras have been fast deployed with a wide range of applications, including agriculture, aerial photography, fast delivery, and surveillance. Consequently, automatic understanding of visual data collected from drones becomes highly demanding, bringing computer vision and drones more and more closely. To promote and track the developments of object detection and tracking algorithms, we have organized two challenge workshops in conjunction with European Conference on Computer Vision (ECCV) 2018, and IEEE International Conference on Computer Vision (ICCV) 2019, attracting more than 100 teams around the world. We provide a large-scale drone captured dataset, VisDrone, which includes four tracks, i.e., (1) image object detection, (2) video object detection, (3) single object tracking, and (4) multi-object tracking. This paper first presents a thorough review of object detection and tracking datasets and benchmarks, and discuss the challenges of collecting large-scale drone-based object detection and tracking datasets with fully manual annotations. After that, we describe our VisDrone dataset, which is captured over various urban/suburban areas of $14$ different cities across China from North to South. Being the largest such dataset ever published, VisDrone enables extensive evaluation and investigation of visual analysis algorithms on the drone platform. We provide a detailed analysis of the current state of the field of large-scale object detection and tracking on drones, and conclude the challenge as well as propose future directions and improvements. We expect the benchmark largely boost the research and development in video analysis on drone platforms. All the datasets and experimental results can be downloaded from the website: https://github.com/VisDrone/VisDrone-Dataset.
Learning Non-Uniform Hypergraph for Multi-Object Tracking
Dec 10, 2018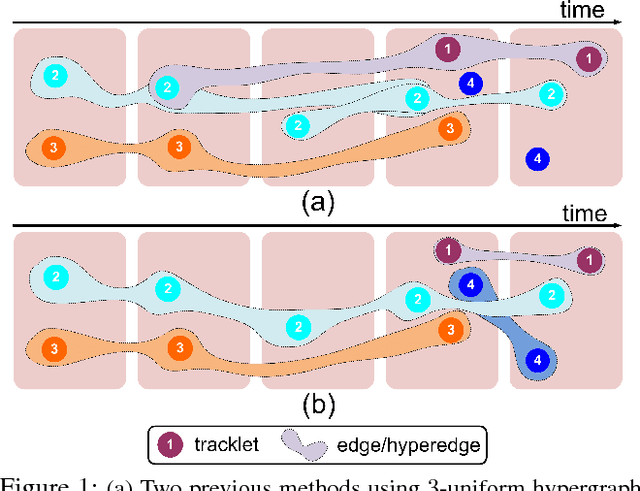
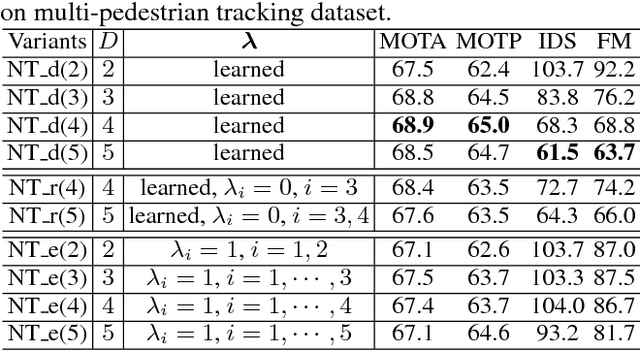
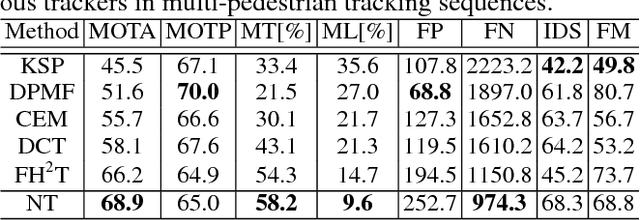

The majority of Multi-Object Tracking (MOT) algorithms based on the tracking-by-detection scheme do not use higher order dependencies among objects or tracklets, which makes them less effective in handling complex scenarios. In this work, we present a new near-online MOT algorithm based on non-uniform hypergraph, which can model different degrees of dependencies among tracklets in a unified objective. The nodes in the hypergraph correspond to the tracklets and the hyperedges with different degrees encode various kinds of dependencies among them. Specifically, instead of setting the weights of hyperedges with different degrees empirically, they are learned automatically using the structural support vector machine algorithm (SSVM). Several experiments are carried out on various challenging datasets (i.e., PETS09, ParkingLot sequence, SubwayFace, and MOT16 benchmark), to demonstrate that our method achieves favorable performance against the state-of-the-art MOT methods.
Evolvement Constrained Adversarial Learning for Video Style Transfer
Nov 06, 2018
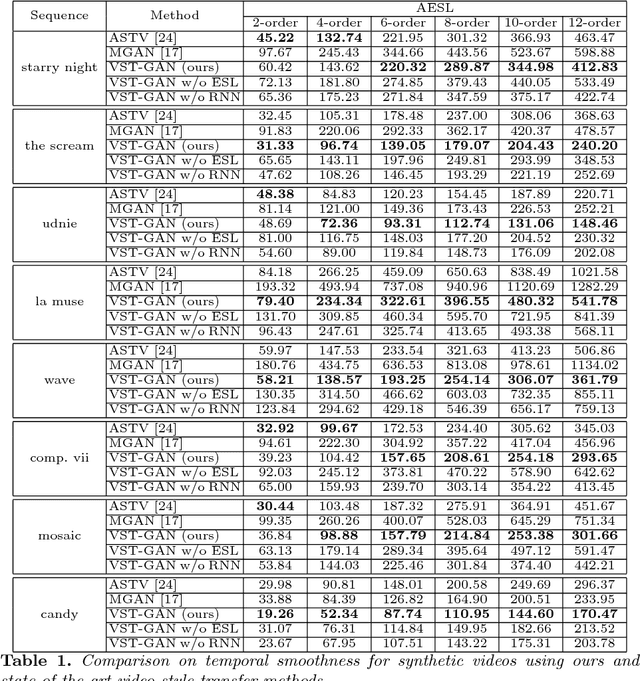


Video style transfer is a useful component for applications such as augmented reality, non-photorealistic rendering, and interactive games. Many existing methods use optical flow to preserve the temporal smoothness of the synthesized video. However, the estimation of optical flow is sensitive to occlusions and rapid motions. Thus, in this work, we introduce a novel evolve-sync loss computed by evolvements to replace optical flow. Using this evolve-sync loss, we build an adversarial learning framework, termed as Video Style Transfer Generative Adversarial Network (VST-GAN), which improves upon the MGAN method for image style transfer for more efficient video style transfer. We perform extensive experimental evaluations of our method and show quantitative and qualitative improvements over the state-of-the-art methods.
Robust Adversarial Perturbation on Deep Proposal-based Models
Sep 16, 2018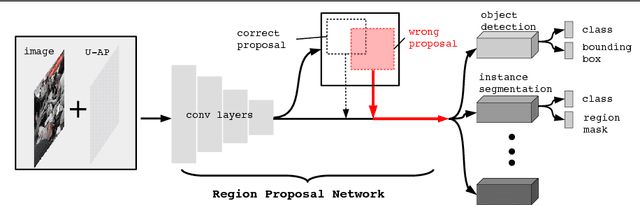
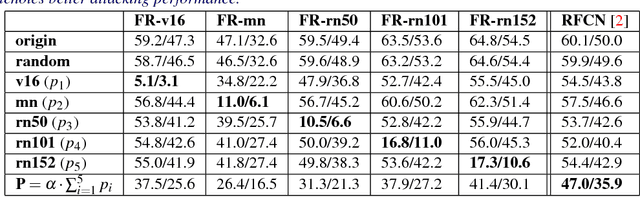
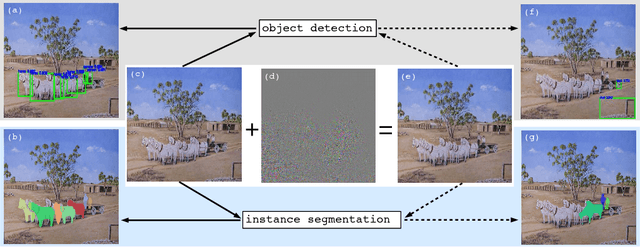
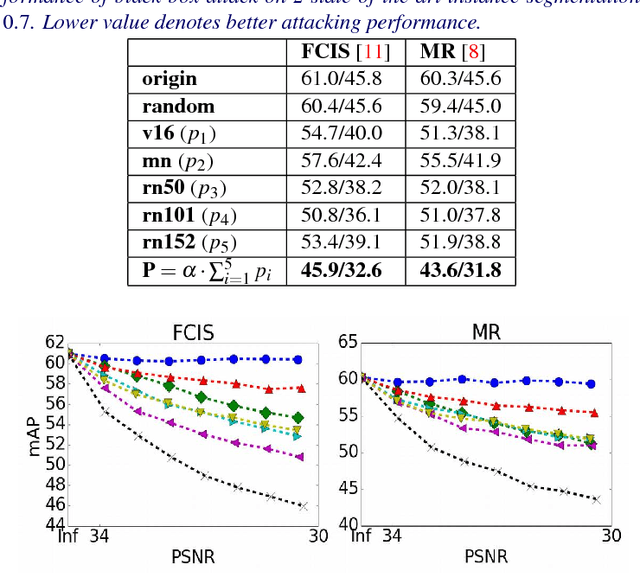
Adversarial noises are useful tools to probe the weakness of deep learning based computer vision algorithms. In this paper, we describe a robust adversarial perturbation (R-AP) method to attack deep proposal-based object detectors and instance segmentation algorithms. Our method focuses on attacking the common component in these algorithms, namely Region Proposal Network (RPN), to universally degrade their performance in a black-box fashion. To do so, we design a loss function that combines a label loss and a novel shape loss, and optimize it with respect to image using a gradient based iterative algorithm. Evaluations are performed on the MS COCO 2014 dataset for the adversarial attacking of 6 state-of-the-art object detectors and 2 instance segmentation algorithms. Experimental results demonstrate the efficacy of the proposed method.
Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd
Jul 23, 2018
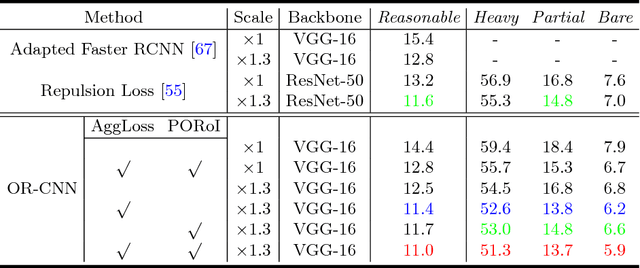
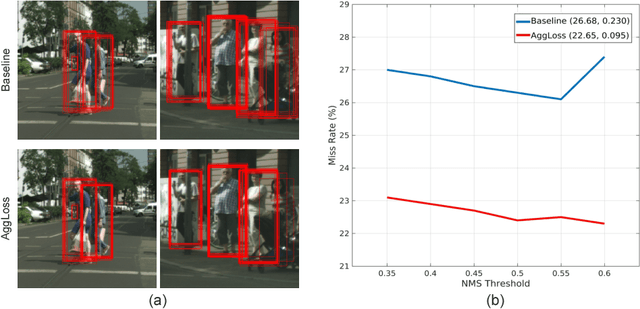

Pedestrian detection in crowded scenes is a challenging problem since the pedestrians often gather together and occlude each other. In this paper, we propose a new occlusion-aware R-CNN (OR-CNN) to improve the detection accuracy in the crowd. Specifically, we design a new aggregation loss to enforce proposals to be close and locate compactly to the corresponding objects. Meanwhile, we use a new part occlusion-aware region of interest (PORoI) pooling unit to replace the RoI pooling layer in order to integrate the prior structure information of human body with visibility prediction into the network to handle occlusion. Our detector is trained in an end-to-end fashion, which achieves state-of-the-art results on three pedestrian detection datasets, i.e., CityPersons, ETH, and INRIA, and performs on-pair with the state-of-the-arts on Caltech.
Vision Meets Drones: A Challenge
Apr 23, 2018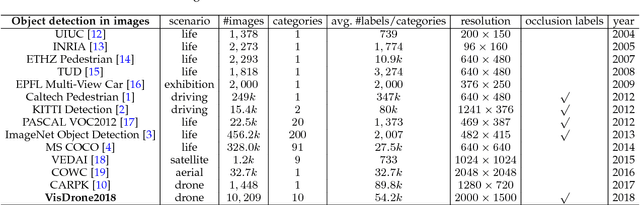



In this paper we present a large-scale visual object detection and tracking benchmark, named VisDrone2018, aiming at advancing visual understanding tasks on the drone platform. The images and video sequences in the benchmark were captured over various urban/suburban areas of 14 different cities across China from north to south. Specifically, VisDrone2018 consists of 263 video clips and 10,209 images (no overlap with video clips) with rich annotations, including object bounding boxes, object categories, occlusion, truncation ratios, etc. With intensive amount of effort, our benchmark has more than 2.5 million annotated instances in 179,264 images/video frames. Being the largest such dataset ever published, the benchmark enables extensive evaluation and investigation of visual analysis algorithms on the drone platform. In particular, we design four popular tasks with the benchmark, including object detection in images, object detection in videos, single object tracking, and multi-object tracking. All these tasks are extremely challenging in the proposed dataset due to factors such as occlusion, large scale and pose variation, and fast motion. We hope the benchmark largely boost the research and development in visual analysis on drone platforms.
Single-Shot Refinement Neural Network for Object Detection
Jan 03, 2018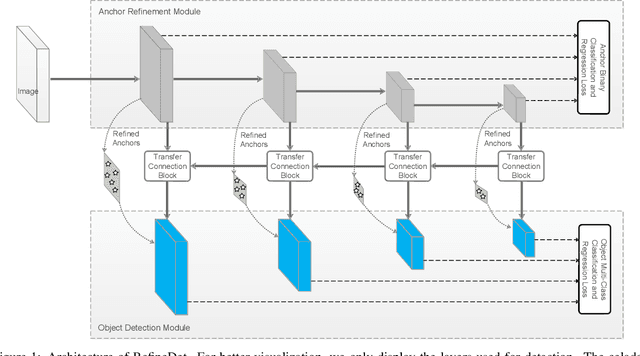
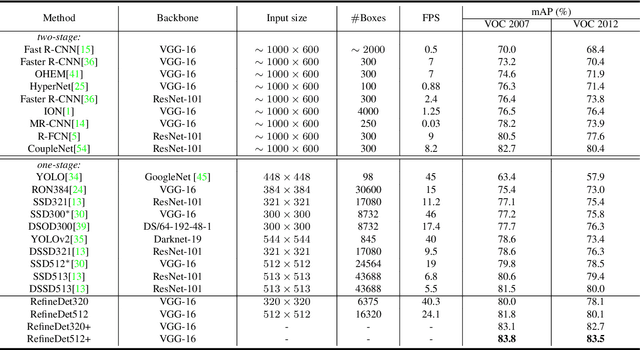
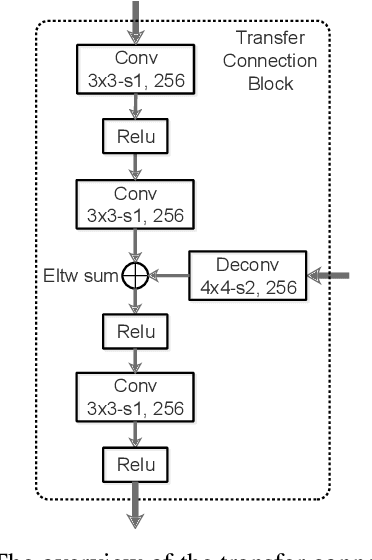
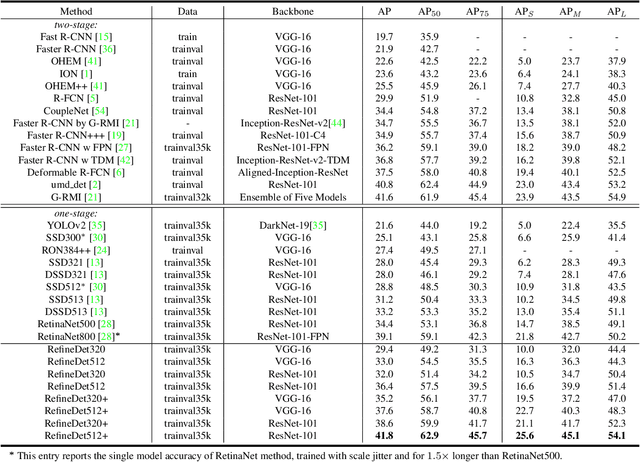
For object detection, the two-stage approach (e.g., Faster R-CNN) has been achieving the highest accuracy, whereas the one-stage approach (e.g., SSD) has the advantage of high efficiency. To inherit the merits of both while overcoming their disadvantages, in this paper, we propose a novel single-shot based detector, called RefineDet, that achieves better accuracy than two-stage methods and maintains comparable efficiency of one-stage methods. RefineDet consists of two inter-connected modules, namely, the anchor refinement module and the object detection module. Specifically, the former aims to (1) filter out negative anchors to reduce search space for the classifier, and (2) coarsely adjust the locations and sizes of anchors to provide better initialization for the subsequent regressor. The latter module takes the refined anchors as the input from the former to further improve the regression and predict multi-class label. Meanwhile, we design a transfer connection block to transfer the features in the anchor refinement module to predict locations, sizes and class labels of objects in the object detection module. The multi-task loss function enables us to train the whole network in an end-to-end way. Extensive experiments on PASCAL VOC 2007, PASCAL VOC 2012, and MS COCO demonstrate that RefineDet achieves state-of-the-art detection accuracy with high efficiency. Code is available at https://github.com/sfzhang15/RefineDet