 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Meets Drones: A Challenge
Paper and Code
Apr 23, 2018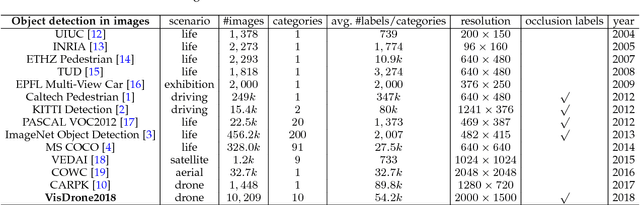



In this paper we present a large-scale visual object detection and tracking benchmark, named VisDrone2018, aiming at advancing visual understanding tasks on the drone platform. The images and video sequences in the benchmark were captured over various urban/suburban areas of 14 different cities across China from north to south. Specifically, VisDrone2018 consists of 263 video clips and 10,209 images (no overlap with video clips) with rich annotations, including object bounding boxes, object categories, occlusion, truncation ratios, etc. With intensive amount of effort, our benchmark has more than 2.5 million annotated instances in 179,264 images/video frames. Being the largest such dataset ever published, the benchmark enables extensive evaluation and investigation of visual analysis algorithms on the drone platform. In particular, we design four popular tasks with the benchmark, including object detection in images, object detection in videos, single object tracking, and multi-object tracking. All these tasks are extremely challenging in the proposed dataset due to factors such as occlusion, large scale and pose variation, and fast motion. We hope the benchmark largely boost the research and development in visual analysis on drone platforms.