 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Budget Allocation in Multi-Task Learning
Aug 24, 2023The cost of labeling data often limits the performance of machine learning systems. In multi-task learning, related tasks provide information to each other and improve overall performance, but the label cost can vary among tasks. How should the label budget (i.e. the amount of money spent on labeling) be allocated among different tasks to achieve optimal multi-task performance? We are the first to propose and formally define the label budget allocation problem in multi-task learning and to empirically show that different budget allocation strategies make a big difference to its performance. We propose a Task-Adaptive Budget Allocation algorithm to robustly generate the optimal budget allocation adaptive to different multi-task learning settings. Specifically, we estimate and then maximize the extent of new information obtained from the allocated budget as a proxy for multi-task learning performance. Experiments on PASCAL VOC and Taskonomy demonstrate the efficacy of our approach over other widely used heuristic labeling strategies.
CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning
Feb 18, 2021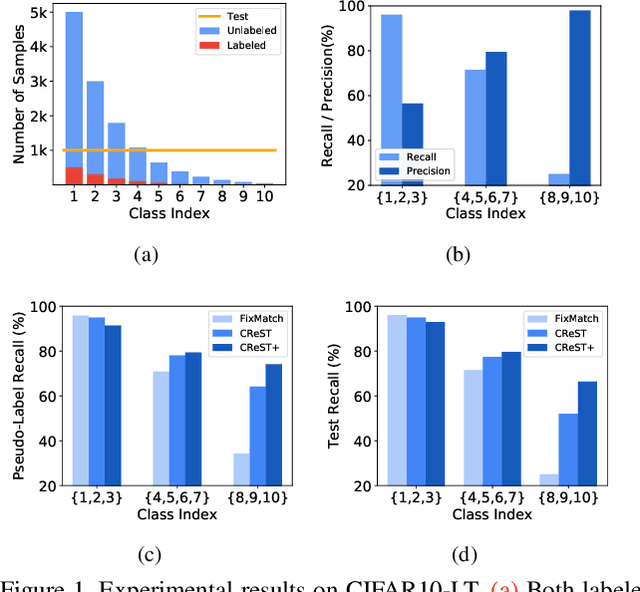

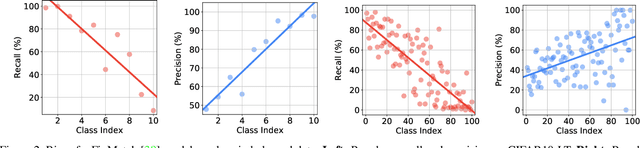
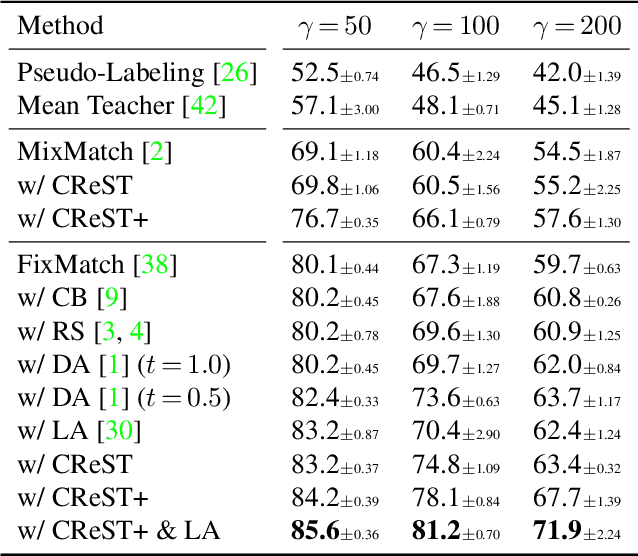
Semi-supervised learning on class-imbalanced data, although a realistic problem, has been under studied. While existing semi-supervised learning (SSL) methods are known to perform poorly on minority classes, we find that they still generate high precision pseudo-labels on minority classes. By exploiting this property, in this work, we propose Class-Rebalancing Self-Training (CReST), a simple yet effective framework to improve existing SSL methods on class-imbalanced data. CReST iteratively retrains a baseline SSL model with a labeled set expanded by adding pseudo-labeled samples from an unlabeled set, where pseudo-labeled samples from minority classes are selected more frequently according to an estimated class distribution. We also propose a progressive distribution alignment to adaptively adjust the rebalancing strength dubbed CReST+. We show that CReST and CReST+ improve state-of-the-art SSL algorithms on various class-imbalanced datasets and consistently outperform other popular rebalancing methods.
LOH and behold: Web-scale visual search, recommendation and clustering using Locally Optimized Hashing
Jul 30, 2016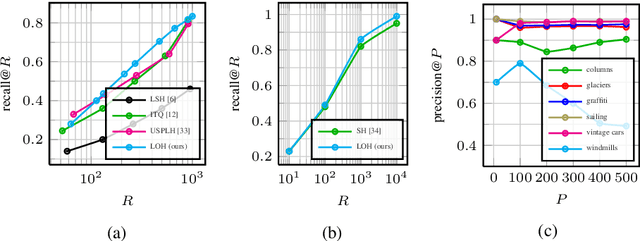



We propose a novel hashing-based matching scheme, called Locally Optimized Hashing (LOH), based on a state-of-the-art quantization algorithm that can be used for efficient, large-scale search, recommendation, clustering, and deduplication. We show that matching with LOH only requires set intersections and summations to compute and so is easily implemented in generic distributed computing systems. We further show application of LOH to: a) large-scale search tasks where performance is on par with other state-of-the-art hashing approaches; b) large-scale recommendation where queries consisting of thousands of images can be used to generate accurate recommendations from collections of hundreds of millions of images; and c) efficient clustering with a graph-based algorithm that can be scaled to massive collections in a distributed environment or can be used for deduplication for small collections, like search results, performing better than traditional hashing approaches while only requiring a few milliseconds to run. In this paper we experiment on datasets of up to 100 million images, but in practice our system can scale to larger collections and can be used for other types of data that have a vector representation in a Euclidean space.
Cross-dimensional Weighting for Aggregated Deep Convolutional Features
Jul 30, 2016
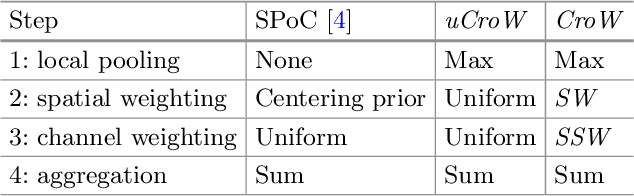
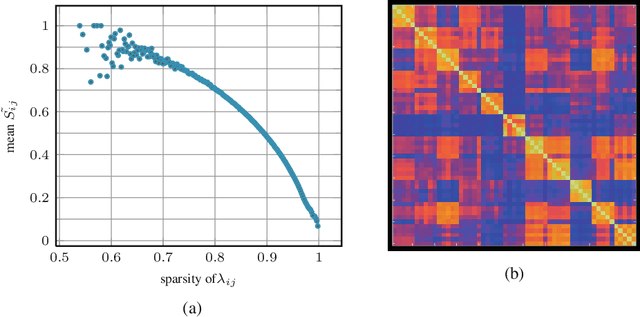
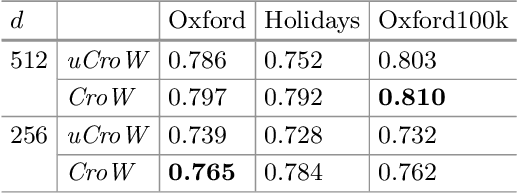
We propose a simple and straightforward way of creating powerful image representations via cross-dimensional weighting and aggregation of deep convolutional neural network layer outputs. We first present a generalized framework that encompasses a broad family of approaches and includes cross-dimensional pooling and weighting steps. We then propose specific non-parametric schemes for both spatial- and channel-wise weighting that boost the effect of highly active spatial responses and at the same time regulate burstiness effects. We experiment on different public datasets for image search and show that our approach outperforms the current state-of-the-art for approaches based on pre-trained networks. We also provide an easy-to-use, open source implementation that reproduces our results.