 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePain Intensity Estimation from Mobile Video Using 2D and 3D Facial Keypoints
Jun 17, 2020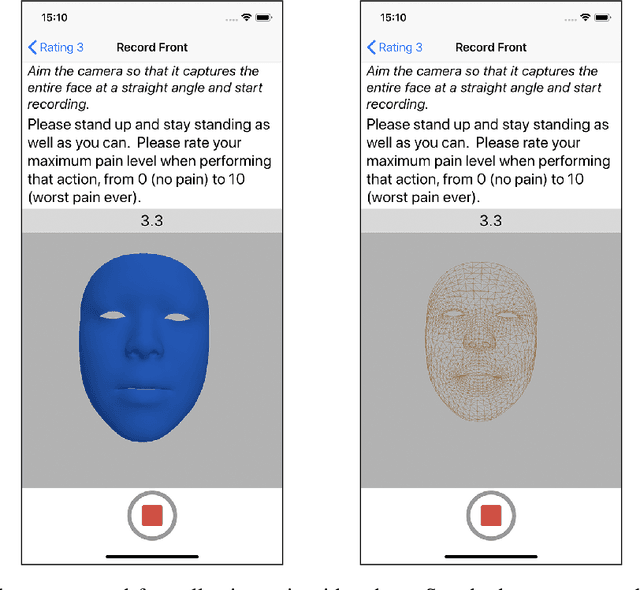
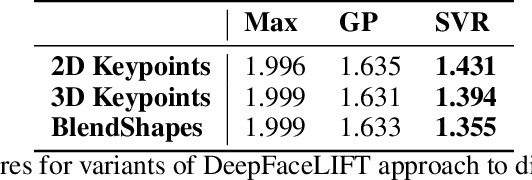
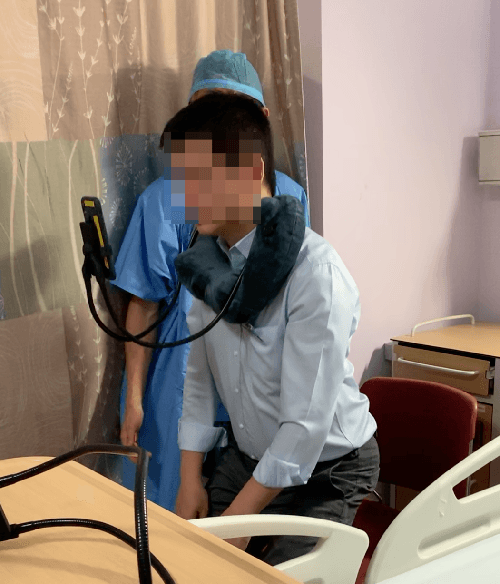
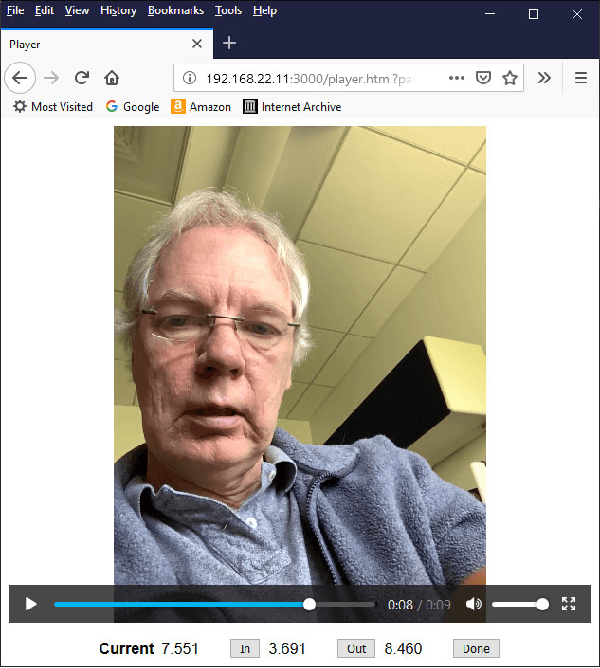
Managing post-surgical pain is critical for successful surgical outcomes. One of the challenges of pain management is accurately assessing the pain level of patients. Self-reported numeric pain ratings are limited because they are subjective, can be affected by mood, and can influence the patient's perception of pain when making comparisons. In this paper, we introduce an approach that analyzes 2D and 3D facial keypoints of post-surgical patients to estimate their pain intensity level. Our approach leverages the previously unexplored capabilities of a smartphone to capture a dense 3D representation of a person's face as input for pain intensity level estimation. Our contributions are adata collection study with post-surgical patients to collect ground-truth labeled sequences of 2D and 3D facial keypoints for developing a pain estimation algorithm, a pain estimation model that uses multiple instance learning to overcome inherent limitations in facial keypoint sequences, and the preliminary results of the pain estimation model using 2D and 3D features with comparisons of alternate approaches.
LOH and behold: Web-scale visual search, recommendation and clustering using Locally Optimized Hashing
Jul 30, 2016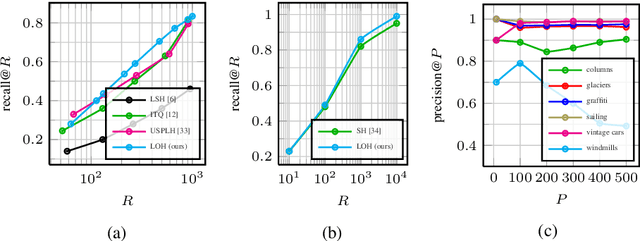



We propose a novel hashing-based matching scheme, called Locally Optimized Hashing (LOH), based on a state-of-the-art quantization algorithm that can be used for efficient, large-scale search, recommendation, clustering, and deduplication. We show that matching with LOH only requires set intersections and summations to compute and so is easily implemented in generic distributed computing systems. We further show application of LOH to: a) large-scale search tasks where performance is on par with other state-of-the-art hashing approaches; b) large-scale recommendation where queries consisting of thousands of images can be used to generate accurate recommendations from collections of hundreds of millions of images; and c) efficient clustering with a graph-based algorithm that can be scaled to massive collections in a distributed environment or can be used for deduplication for small collections, like search results, performing better than traditional hashing approaches while only requiring a few milliseconds to run. In this paper we experiment on datasets of up to 100 million images, but in practice our system can scale to larger collections and can be used for other types of data that have a vector representation in a Euclidean space.
Visual Congruent Ads for Image Search
Apr 21, 2016
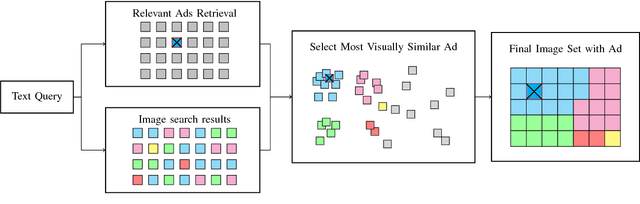
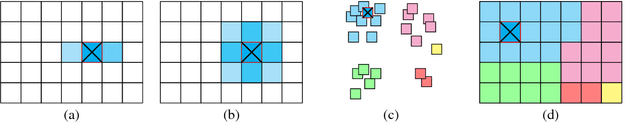

The quality of user experience online is affected by the relevance and placement of advertisements. We propose a new system for selecting and displaying visual advertisements in image search result sets. Our method compares the visual similarity of candidate ads to the image search results and selects the most visually similar ad to be displayed. The method further selects an appropriate location in the displayed image grid to minimize the perceptual visual differences between the ad and its neighbors. We conduct an experiment with about 900 users and find that our proposed method provides significant improvement in the users' overall satisfaction with the image search experience, without diminishing the users' ability to see the ad or recall the advertised brand.