 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDinoAtten3D: Slice-Level Attention Aggregation of DinoV2 for 3D Brain MRI Anomaly Classification
Sep 15, 2025Anomaly detection and classification in medical imaging are critical for early diagnosis but remain challenging due to limited annotated data, class imbalance, and the high cost of expert labeling. Emerging vision foundation models such as DINOv2, pretrained on extensive, unlabeled datasets, offer generalized representations that can potentially alleviate these limitations. In this study, we propose an attention-based global aggregation framework tailored specifically for 3D medical image anomaly classification. Leveraging the self-supervised DINOv2 model as a pretrained feature extractor, our method processes individual 2D axial slices of brain MRIs, assigning adaptive slice-level importance weights through a soft attention mechanism. To further address data scarcity, we employ a composite loss function combining supervised contrastive learning with class-variance regularization, enhancing inter-class separability and intra-class consistency. We validate our framework on the ADNI dataset and an institutional multi-class headache cohort, demonstrating strong anomaly classification performance despite limited data availability and significant class imbalance. Our results highlight the efficacy of utilizing pretrained 2D foundation models combined with attention-based slice aggregation for robust volumetric anomaly detection in medical imaging. Our implementation is publicly available at https://github.com/Rafsani/DinoAtten3D.git.
AnoFPDM: Anomaly Segmentation with Forward Process of Diffusion Models for Brain MRI
Apr 24, 2024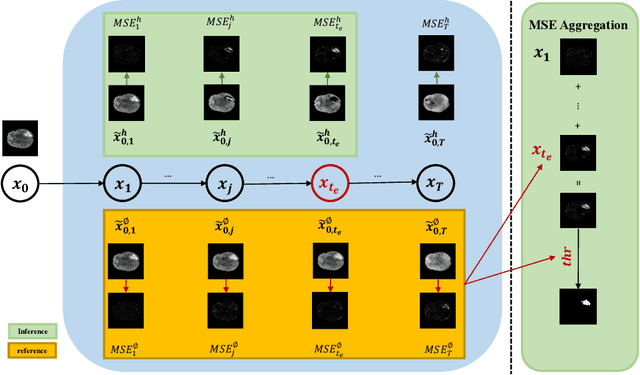

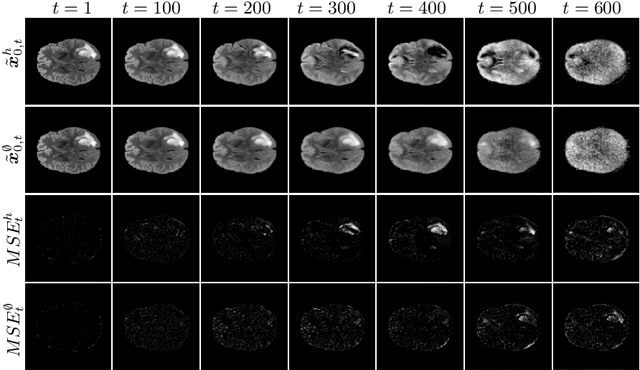

Weakly-supervised diffusion models (DM) in anomaly segmentation, leveraging image-level labels, have attracted significant attention for their superior performance compared to unsupervised methods. It eliminates the need for pixel-level labels in training, offering a more cost-effective alternative to supervised methods. However, existing methods are not fully weakly-supervised because they heavily rely on costly pixel-level labels for hyperparameter tuning in inference. To tackle this challenge, we introduce Anomaly Segmentation with Forward Process of Diffusion Models (AnoFPDM), a fully weakly-supervised framework that operates without the need for pixel-level labels. Leveraging the unguided forward process as a reference, we identify suitable hyperparameters, i.e., noise scale and threshold, for each input image. We aggregate anomaly maps from each step in the forward process, enhancing the signal strength of anomalous regions. Remarkably, our proposed method outperforms recent state-of-the-art weakly-supervised approaches, even without utilizing pixel-level labels.
Pseudo Supervised Metrics: Evaluating Unsupervised Image to Image Translation Models In Unsupervised Cross-Domain Classification Frameworks
Mar 18, 2023The ability to classify images accurately and efficiently is dependent on having access to large labeled datasets and testing on data from the same domain that the model is trained on. Classification becomes more challenging when dealing with new data from a different domain, where collecting a large labeled dataset and training a new classifier from scratch is time-consuming, expensive, and sometimes infeasible or impossible. Cross-domain classification frameworks were developed to handle this data domain shift problem by utilizing unsupervised image-to-image (UI2I) translation models to translate an input image from the unlabeled domain to the labeled domain. The problem with these unsupervised models lies in their unsupervised nature. For lack of annotations, it is not possible to use the traditional supervised metrics to evaluate these translation models to pick the best-saved checkpoint model. In this paper, we introduce a new method called Pseudo Supervised Metrics that was designed specifically to support cross-domain classification applications contrary to other typically used metrics such as the FID which was designed to evaluate the model in terms of the quality of the generated image from a human-eye perspective. We show that our metric not only outperforms unsupervised metrics such as the FID, but is also highly correlated with the true supervised metrics, robust, and explainable. Furthermore, we demonstrate that it can be used as a standard metric for future research in this field by applying it to a critical real-world problem (the boiling crisis problem).
Brainomaly: Unsupervised Neurologic Disease Detection Utilizing Unannotated T1-weighted Brain MR Images
Feb 18, 2023Deep neural networks have revolutionized the field of supervised learning by enabling accurate predictions through learning from large annotated datasets. However, acquiring large annotated medical imaging datasets is a challenging task, especially for rare diseases, due to the high cost, time, and effort required for annotation. In these scenarios, unsupervised disease detection methods, such as anomaly detection, can save significant human effort. A typically used approach for anomaly detection is to learn the images from healthy subjects only, assuming the model will detect the images from diseased subjects as outliers. However, in many real-world scenarios, unannotated datasets with a mix of healthy and diseased individuals are available. Recent studies have shown improvement in unsupervised disease/anomaly detection using such datasets of unannotated images from healthy and diseased individuals compared to datasets that only include images from healthy individuals. A major issue remains unaddressed in these studies, which is selecting the best model for inference from a set of trained models without annotated samples. To address this issue, we propose Brainomaly, a GAN-based image-to-image translation method for neurologic disease detection using unannotated T1-weighted brain MRIs of individuals with neurologic diseases and healthy subjects. Brainomaly is trained to remove the diseased regions from the input brain MRIs and generate MRIs of corresponding healthy brains. Instead of generating the healthy images directly, Brainomaly generates an additive map where each voxel indicates the amount of changes required to make the input image look healthy. In addition, Brainomaly uses a pseudo-AUC metric for inference model selection, which further improves the detection performance. Our Brainomaly outperforms existing state-of-the-art methods by large margins.
A Generalized Framework for Critical Heat Flux Detection Using Unsupervised Image-to-Image Translation
Dec 25, 2022



This work proposes a framework developed to generalize Critical Heat Flux (CHF) detection classification models using an Unsupervised Image-to-Image (UI2I) translation model. The framework enables a typical classification model that was trained and tested on boiling images from domain A to predict boiling images coming from domain B that was never seen by the classification model. This is done by using the UI2I model to transform the domain B images to look like domain A images that the classification model is familiar with. Although CNN was used as the classification model and Fixed-Point GAN (FP-GAN) was used as the UI2I model, the framework is model agnostic. Meaning, that the framework can generalize any image classification model type, making it applicable to a variety of similar applications and not limited to the boiling crisis detection problem. It also means that the more the UI2I models advance, the better the performance of the framework.
HealthyGAN: Learning from Unannotated Medical Images to Detect Anomalies Associated with Human Disease
Sep 05, 2022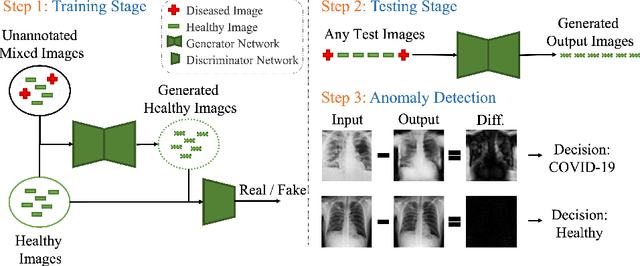
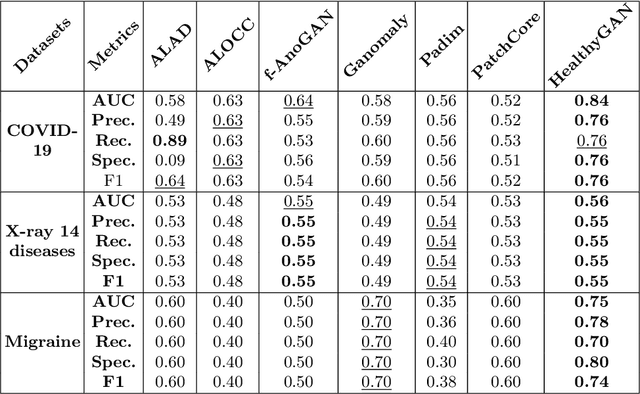
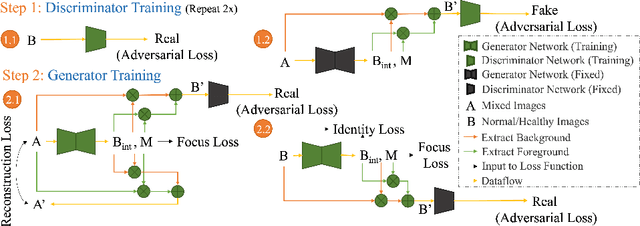
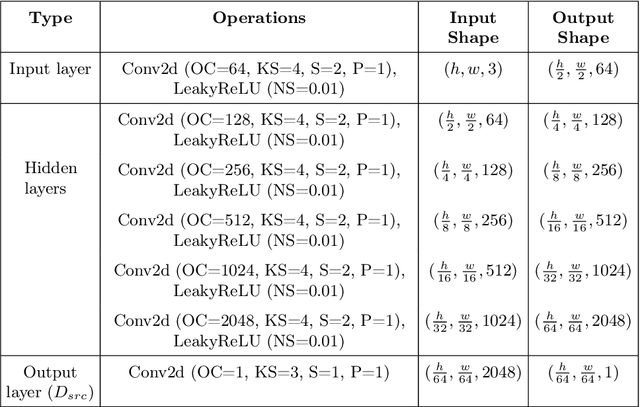
Automated anomaly detection from medical images, such as MRIs and X-rays, can significantly reduce human effort in disease diagnosis. Owing to the complexity of modeling anomalies and the high cost of manual annotation by domain experts (e.g., radiologists), a typical technique in the current medical imaging literature has focused on deriving diagnostic models from healthy subjects only, assuming the model will detect the images from patients as outliers. However, in many real-world scenarios, unannotated datasets with a mix of both healthy and diseased individuals are abundant. Therefore, this paper poses the research question of how to improve unsupervised anomaly detection by utilizing (1) an unannotated set of mixed images, in addition to (2) the set of healthy images as being used in the literature. To answer the question, we propose HealthyGAN, a novel one-directional image-to-image translation method, which learns to translate the images from the mixed dataset to only healthy images. Being one-directional, HealthyGAN relaxes the requirement of cycle consistency of existing unpaired image-to-image translation methods, which is unattainable with mixed unannotated data. Once the translation is learned, we generate a difference map for any given image by subtracting its translated output. Regions of significant responses in the difference map correspond to potential anomalies (if any). Our HealthyGAN outperforms the conventional state-of-the-art methods by significant margins on two publicly available datasets: COVID-19 and NIH ChestX-ray14, and one institutional dataset collected from Mayo Clinic. The implementation is publicly available at https://github.com/mahfuzmohammad/HealthyGAN.
Beyond Point Clouds: A Knowledge-Aided High Resolution Imaging Radar Deep Detector for Autonomous Driving
Nov 01, 2021
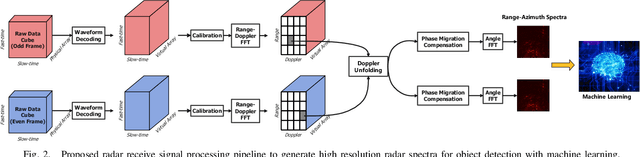
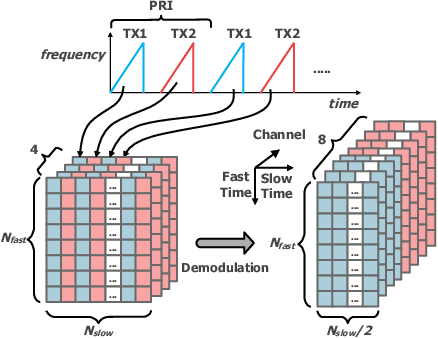
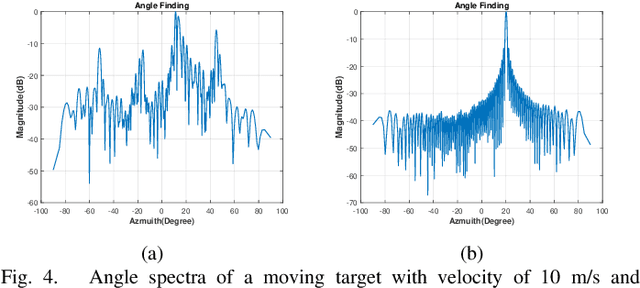
The potentials of automotive radar for autonomous driving have not been fully exploited. We present a multi-input multi-output (MIMO) radar transmit and receive signal processing chain, a knowledge-aided approach exploiting the radar domain knowledge and signal structure, to generate high resolution radar range-azimuth spectra for object detection and classification using deep neural networks. To achieve waveform orthogonality among a large number of transmit antennas cascaded by four automotive radar transceivers, we propose a staggered time division multiplexing (TDM) scheme and velocity unfolding algorithm using both Chinese remainder theorem and overlapped array. Field experiments with multi-modal sensors were conducted at The University of Alabama. High resolution radar spectra were obtained and labeled using the camera and LiDAR recordings. Initial experiments show promising performance of object detection using an image-oriented deep neural network with an average precision of 96.1% at an intersection of union (IoU) of typically 0.5 on 2,000 radar frames.
A Preliminary Comparison Between Compressive Sampling and Anisotropic Mesh-based Image Representation
Dec 14, 2020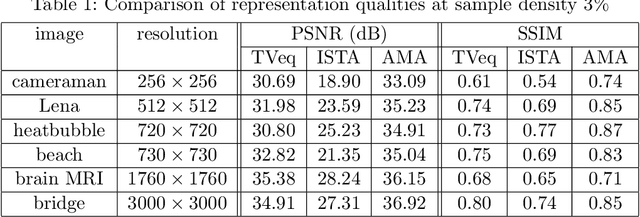


Compressed sensing (CS) has become a popular field in the last two decades to represent and reconstruct a sparse signal with much fewer samples than the signal itself. Although regular images are not sparse on their own, many can be sparsely represented in wavelet transform domain. Therefore, CS has also been widely applied to represent digital images. However, an alternative approach, adaptive sampling such as mesh-based image representation (MbIR), has not attracted as much attention. MbIR works directly on image pixels and represents the image with fewer points using a triangular mesh. In this paper, we perform a preliminary comparison between the CS and a recently developed MbIR method, AMA representation. The results demonstrate that, at the same sample density, AMA representation can provide better reconstruction quality than CS based on the tested algorithms. Further investigation with recent algorithms is needed to perform a thorough comparison.
A Feature Transfer Enabled Multi-Task Deep Learning Model on Medical Imaging
Jun 05, 2019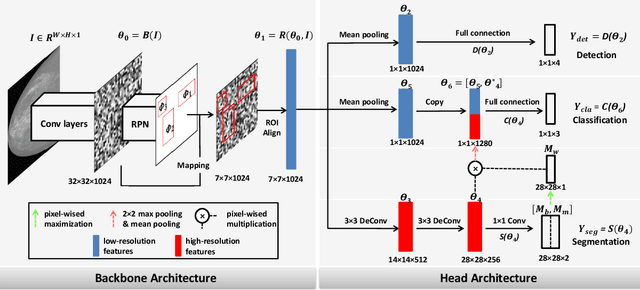
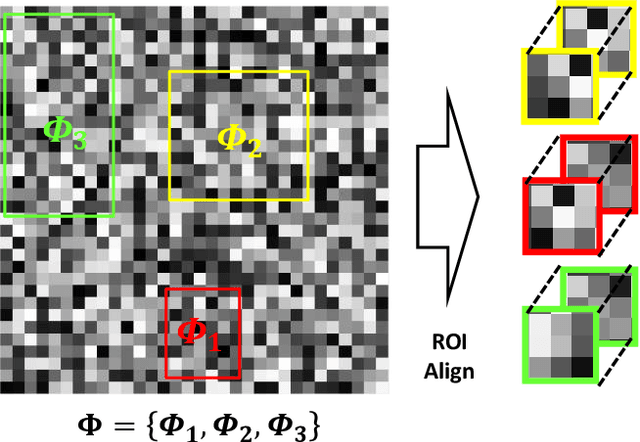
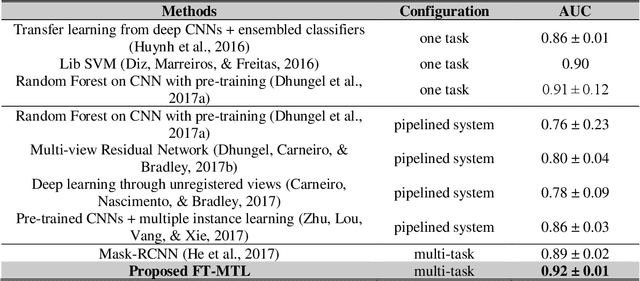
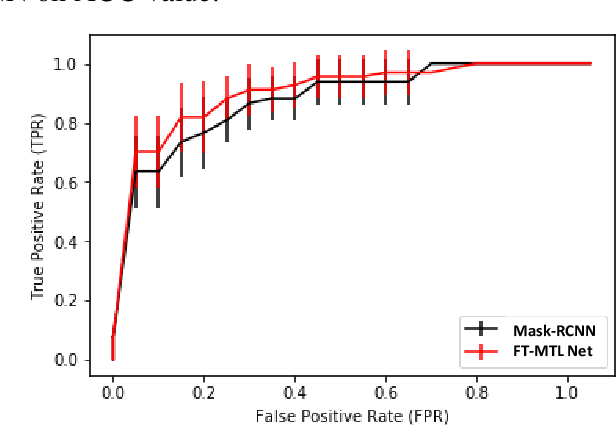
Object detection, segmentation and classification are three common tasks in medical image analysis. Multi-task deep learning (MTL) tackles these three tasks jointly, which provides several advantages saving computing time and resources and improving robustness against overfitting. However, existing multitask deep models start with each task as an individual task and integrate parallelly conducted tasks at the end of the architecture with one cost function. Such architecture fails to take advantage of the combined power of the features from each individual task at an early stage of the training. In this research, we propose a new architecture, FTMTLNet, an MTL enabled by feature transferring. Traditional transfer learning deals with the same or similar task from different data sources (a.k.a. domain). The underlying assumption is that the knowledge gained from source domains may help the learning task on the target domain. Our proposed FTMTLNet utilizes the different tasks from the same domain. Considering features from the tasks are different views of the domain, the combined feature maps can be well exploited using knowledge from multiple views to enhance the generalizability. To evaluate the validity of the proposed approach, FTMTLNet is compared with models from literature including 8 classification models, 4 detection models and 3 segmentation models using a public full field digital mammogram dataset for breast cancer diagnosis. Experimental results show that the proposed FTMTLNet outperforms the competing models in classification and detection and has comparable results in segmentation.
SD-CNN: a Shallow-Deep CNN for Improved Breast Cancer Diagnosis
Oct 26, 2018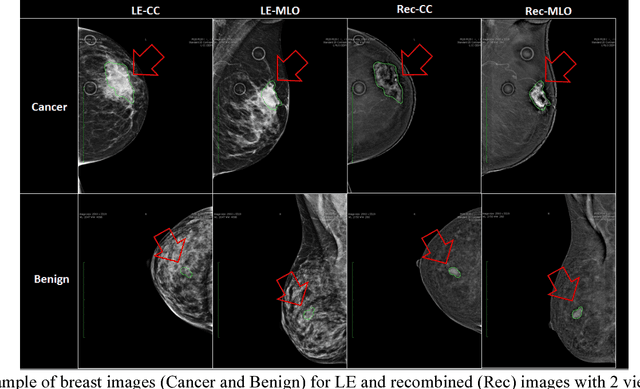

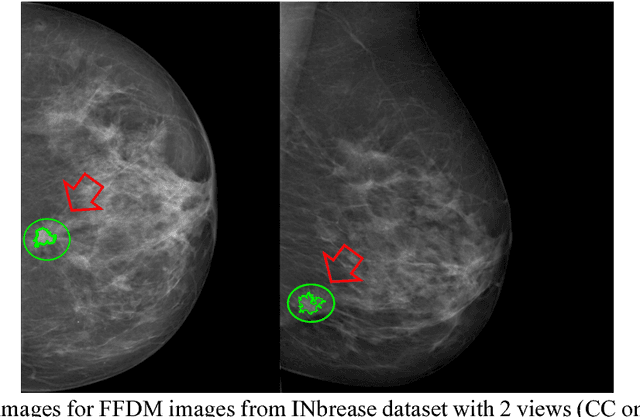

Breast cancer is the second leading cause of cancer death among women worldwide. Nevertheless, it is also one of the most treatable malignances if detected early. Screening for breast cancer with digital mammography (DM) has been widely used. However it demonstrates limited sensitivity for women with dense breasts. An emerging technology in the field is contrast-enhanced digital mammography (CEDM), which includes a low energy (LE) image similar to DM, and a recombined image leveraging tumor neoangiogenesis similar to breast magnetic resonance imaging (MRI). CEDM has shown better diagnostic accuracy than DM. While promising, CEDM is not yet widely available across medical centers. In this research, we propose a Shallow-Deep Convolutional Neural Network (SD-CNN) where a shallow CNN is developed to derive "virtual" recombined images from LE images, and a deep CNN is employed to extract novel features from LE, recombined or "virtual" recombined images for ensemble models to classify the cases as benign vs. cancer. To evaluate the validity of our approach, we first develop a deep-CNN using 49 CEDM cases collected from Mayo Clinic to prove the contributions from recombined images for improved breast cancer diagnosis (0.86 in accuracy using LE imaging vs. 0.90 in accuracy using both LE and recombined imaging). We then develop a shallow-CNN using the same 49 CEDM cases to learn the nonlinear mapping from LE to recombined images. Next, we use 69 DM cases collected from the hospital located at Zhejiang University, China to generate "virtual" recombined images. Using DM alone provides 0.91 in accuracy, whereas SD-CNN improves the diagnostic accuracy to 0.95.