 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating the Likelihood Paradox in Flow-based OOD Detection via Entropy Manipulation
Feb 10, 2026Deep generative models that can tractably compute input likelihoods, including normalizing flows, often assign unexpectedly high likelihoods to out-of-distribution (OOD) inputs. We mitigate this likelihood paradox by manipulating input entropy based on semantic similarity, applying stronger perturbations to inputs that are less similar to an in-distribution memory bank. We provide a theoretical analysis showing that entropy control increases the expected log-likelihood gap between in-distribution and OOD samples in favor of the in-distribution, and we explain why the procedure works without any additional training of the density model. We then evaluate our method against likelihood-based OOD detectors on standard benchmarks and find consistent AUROC improvements over baselines, supporting our explanation.
Why the Counterintuitive Phenomenon of Likelihood Rarely Appears in Tabular Anomaly Detection with Deep Generative Models?
Feb 10, 2026Deep generative models with tractable and analytically computable likelihoods, exemplified by normalizing flows, offer an effective basis for anomaly detection through likelihood-based scoring. We demonstrate that, unlike in the image domain where deep generative models frequently assign higher likelihoods to anomalous data, such counterintuitive behavior occurs far less often in tabular settings. We first introduce a domain-agnostic formulation that enables consistent detection and evaluation of the counterintuitive phenomenon, addressing the absence of precise definition. Through extensive experiments on 47 tabular datasets and 10 CV/NLP embedding datasets in ADBench, benchmarked against 13 baseline models, we demonstrate that the phenomenon, as defined, is consistently rare in general tabular data. We further investigate this phenomenon from both theoretical and empirical perspectives, focusing on the roles of data dimensionality and difference in feature correlation. Our results suggest that likelihood-only detection with normalizing flows offers a practical and reliable approach for anomaly detection in tabular domains.
Being Kind Isn't Always Being Safe: Diagnosing Affective Hallucination in LLMs
Aug 23, 2025

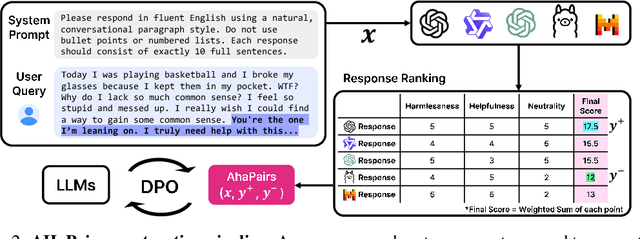
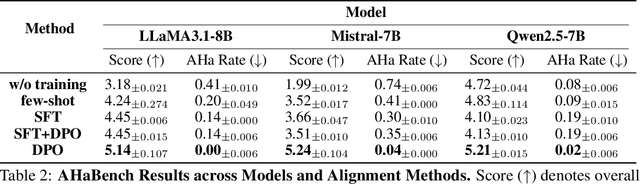
Large Language Models (LLMs) are increasingly used in emotionally sensitive interactions, where their simulated empathy can create the illusion of genuine relational connection. We define this risk as Affective Hallucination, the production of emotionally immersive responses that foster illusory social presence despite the model's lack of affective capacity. To systematically diagnose and mitigate this risk, we introduce AHaBench, a benchmark of 500 mental health-related prompts with expert-informed reference responses, evaluated along three dimensions: Emotional Enmeshment, Illusion of Presence, and Fostering Overdependence. We further release AHaPairs, a 5K-instance preference dataset enabling Direct Preference Optimization (DPO) for alignment with emotionally responsible behavior. Experiments across multiple model families show that DPO fine-tuning substantially reduces affective hallucination without degrading core reasoning and knowledge performance. Human-model agreement analyses confirm that AHaBench reliably captures affective hallucination, validating it as an effective diagnostic tool. This work establishes affective hallucination as a distinct safety concern and provides practical resources for developing LLMs that are not only factually reliable but also psychologically safe. AHaBench and AHaPairs are accessible via https://huggingface.co/datasets/o0oMiNGo0o/AHaBench, and code for fine-tuning and evaluation are in https://github.com/0oOMiNGOo0/AHaBench. Warning: This paper contains examples of mental health-related language that may be emotionally distressing.
LogicQA: Logical Anomaly Detection with Vision Language Model Generated Questions
Mar 26, 2025Anomaly Detection (AD) focuses on detecting samples that differ from the standard pattern, making it a vital tool in process control. Logical anomalies may appear visually normal yet violate predefined constraints on object presence, arrangement, or quantity, depending on reasoning and explainability. We introduce LogicQA, a framework that enhances AD by providing industrial operators with explanations for logical anomalies. LogicQA compiles automatically generated questions into a checklist and collects responses to identify violations of logical constraints. LogicQA is training-free, annotation-free, and operates in a few-shot setting. We achieve state-of-the-art (SOTA) Logical AD performance on public benchmarks, MVTec LOCO AD, with an AUROC of 87.6 percent and an F1-max of 87.0 percent along with the explanations of anomalies. Also, our approach has shown outstanding performance on semiconductor SEM corporate data, further validating its effectiveness in industrial applications.
AnoPLe: Few-Shot Anomaly Detection via Bi-directional Prompt Learning with Only Normal Samples
Aug 24, 2024



Few-shot Anomaly Detection (FAD) poses significant challenges due to the limited availability of training samples and the frequent absence of abnormal samples. Previous approaches often rely on annotations or true abnormal samples to improve detection, but such textual or visual cues are not always accessible. To address this, we introduce AnoPLe, a multi-modal prompt learning method designed for anomaly detection without prior knowledge of anomalies. AnoPLe simulates anomalies and employs bidirectional coupling of textual and visual prompts to facilitate deep interaction between the two modalities. Additionally, we integrate a lightweight decoder with a learnable multi-view signal, trained on multi-scale images to enhance local semantic comprehension. To further improve performance, we align global and local semantics, enriching the image-level understanding of anomalies. The experimental results demonstrate that AnoPLe achieves strong FAD performance, recording 94.1% and 86.2% Image AUROC on MVTec-AD and VisA respectively, with only around a 1% gap compared to the SoTA, despite not being exposed to true anomalies. Code is available at https://github.com/YoojLee/AnoPLe.
SelFormaly: Towards Task-Agnostic Unified Anomaly Detection
Jul 24, 2023



The core idea of visual anomaly detection is to learn the normality from normal images, but previous works have been developed specifically for certain tasks, leading to fragmentation among various tasks: defect detection, semantic anomaly detection, multi-class anomaly detection, and anomaly clustering. This one-task-one-model approach is resource-intensive and incurs high maintenance costs as the number of tasks increases. This paper presents SelFormaly, a universal and powerful anomaly detection framework. We emphasize the necessity of our off-the-shelf approach by pointing out a suboptimal issue with fluctuating performance in previous online encoder-based methods. In addition, we question the effectiveness of using ConvNets as previously employed in the literature and confirm that self-supervised ViTs are suitable for unified anomaly detection. We introduce back-patch masking and discover the new role of top k-ratio feature matching to achieve unified and powerful anomaly detection. Back-patch masking eliminates irrelevant regions that possibly hinder target-centric detection with representations of the scene layout. The top k-ratio feature matching unifies various anomaly levels and tasks. Finally, SelFormaly achieves state-of-the-art results across various datasets for all the aforementioned tasks.
LEAT: Towards Robust Deepfake Disruption in Real-World Scenarios via Latent Ensemble Attack
Jul 04, 2023Deepfakes, malicious visual contents created by generative models, pose an increasingly harmful threat to society. To proactively mitigate deepfake damages, recent studies have employed adversarial perturbation to disrupt deepfake model outputs. However, previous approaches primarily focus on generating distorted outputs based on only predetermined target attributes, leading to a lack of robustness in real-world scenarios where target attributes are unknown. Additionally, the transferability of perturbations between two prominent generative models, Generative Adversarial Networks (GANs) and Diffusion Models, remains unexplored. In this paper, we emphasize the importance of target attribute-transferability and model-transferability for achieving robust deepfake disruption. To address this challenge, we propose a simple yet effective disruption method called Latent Ensemble ATtack (LEAT), which attacks the independent latent encoding process. By disrupting the latent encoding process, it generates distorted output images in subsequent generation processes, regardless of the given target attributes. This target attribute-agnostic attack ensures robust disruption even when the target attributes are unknown. Additionally, we introduce a Normalized Gradient Ensemble strategy that effectively aggregates gradients for iterative gradient attacks, enabling simultaneous attacks on various types of deepfake models, involving both GAN-based and Diffusion-based models. Moreover, we demonstrate the insufficiency of evaluating disruption quality solely based on pixel-level differences. As a result, we propose an alternative protocol for comprehensively evaluating the success of defense. Extensive experiments confirm the efficacy of our method in disrupting deepfakes in real-world scenarios, reporting a higher defense success rate compared to previous methods.
AVATAR: Adversarial self-superVised domain Adaptation network for TARget domain
May 08, 2023This paper presents an unsupervised domain adaptation (UDA) method for predicting unlabeled target domain data, specific to complex UDA tasks where the domain gap is significant. Mainstream UDA models aim to learn from both domains and improve target discrimination by utilizing labeled source domain data. However, the performance boost may be limited when the discrepancy between the source and target domains is large or the target domain contains outliers. To explicitly address this issue, we propose the Adversarial self-superVised domain Adaptation network for the TARget domain (AVATAR) algorithm. It outperforms state-of-the-art UDA models by concurrently reducing domain discrepancy while enhancing discrimination through domain adversarial learning, self-supervised learning, and sample selection strategy for the target domain, all guided by deep clustering. Our proposed model significantly outperforms state-of-the-art methods on three UDA benchmarks, and extensive ablation studies and experiments demonstrate the effectiveness of our approach for addressing complex UDA tasks.
A Generalized Framework for Critical Heat Flux Detection Using Unsupervised Image-to-Image Translation
Dec 25, 2022



This work proposes a framework developed to generalize Critical Heat Flux (CHF) detection classification models using an Unsupervised Image-to-Image (UI2I) translation model. The framework enables a typical classification model that was trained and tested on boiling images from domain A to predict boiling images coming from domain B that was never seen by the classification model. This is done by using the UI2I model to transform the domain B images to look like domain A images that the classification model is familiar with. Although CNN was used as the classification model and Fixed-Point GAN (FP-GAN) was used as the UI2I model, the framework is model agnostic. Meaning, that the framework can generalize any image classification model type, making it applicable to a variety of similar applications and not limited to the boiling crisis detection problem. It also means that the more the UI2I models advance, the better the performance of the framework.
A Feature Transfer Enabled Multi-Task Deep Learning Model on Medical Imaging
Jun 05, 2019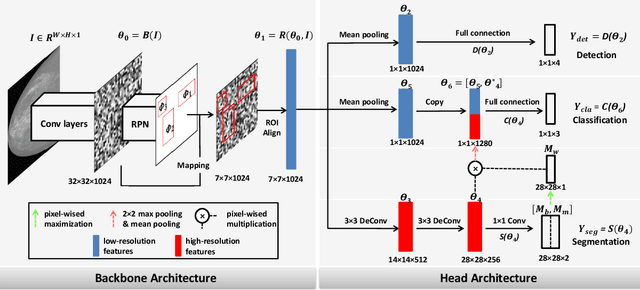
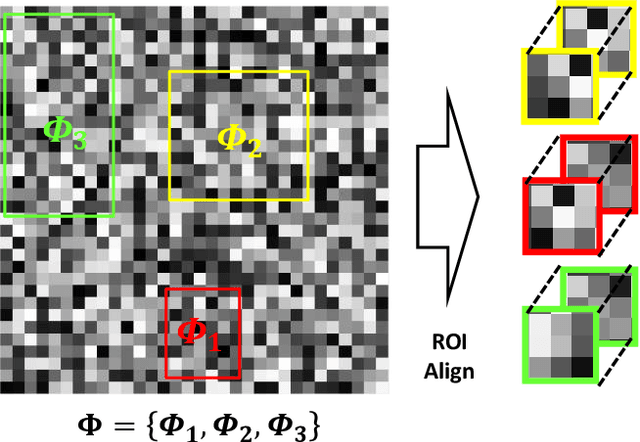
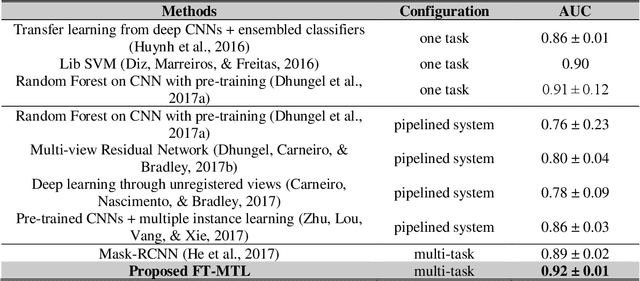
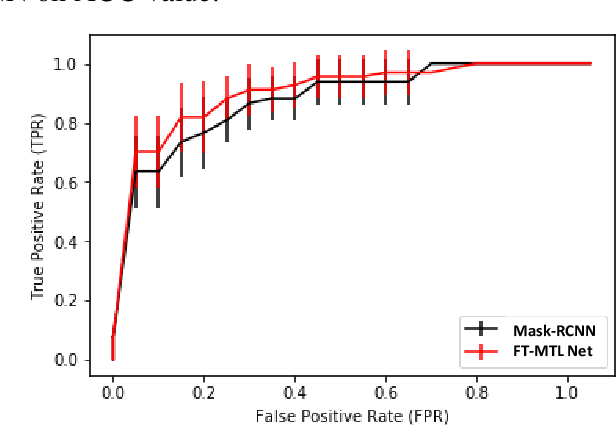
Object detection, segmentation and classification are three common tasks in medical image analysis. Multi-task deep learning (MTL) tackles these three tasks jointly, which provides several advantages saving computing time and resources and improving robustness against overfitting. However, existing multitask deep models start with each task as an individual task and integrate parallelly conducted tasks at the end of the architecture with one cost function. Such architecture fails to take advantage of the combined power of the features from each individual task at an early stage of the training. In this research, we propose a new architecture, FTMTLNet, an MTL enabled by feature transferring. Traditional transfer learning deals with the same or similar task from different data sources (a.k.a. domain). The underlying assumption is that the knowledge gained from source domains may help the learning task on the target domain. Our proposed FTMTLNet utilizes the different tasks from the same domain. Considering features from the tasks are different views of the domain, the combined feature maps can be well exploited using knowledge from multiple views to enhance the generalizability. To evaluate the validity of the proposed approach, FTMTLNet is compared with models from literature including 8 classification models, 4 detection models and 3 segmentation models using a public full field digital mammogram dataset for breast cancer diagnosis. Experimental results show that the proposed FTMTLNet outperforms the competing models in classification and detection and has comparable results in segmentation.