 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVILA-M3: Enhancing Vision-Language Models with Medical Expert Knowledge
Nov 19, 2024



Generalist vision language models (VLMs) have made significant strides in computer vision, but they fall short in specialized fields like healthcare, where expert knowledge is essential. In traditional computer vision tasks, creative or approximate answers may be acceptable, but in healthcare, precision is paramount.Current large multimodal models like Gemini and GPT-4o are insufficient for medical tasks due to their reliance on memorized internet knowledge rather than the nuanced expertise required in healthcare. VLMs are usually trained in three stages: vision pre-training, vision-language pre-training, and instruction fine-tuning (IFT). IFT has been typically applied using a mixture of generic and healthcare data. In contrast, we propose that for medical VLMs, a fourth stage of specialized IFT is necessary, which focuses on medical data and includes information from domain expert models. Domain expert models developed for medical use are crucial because they are specifically trained for certain clinical tasks, e.g. to detect tumors and classify abnormalities through segmentation and classification, which learn fine-grained features of medical data$-$features that are often too intricate for a VLM to capture effectively especially in radiology. This paper introduces a new framework, VILA-M3, for medical VLMs that utilizes domain knowledge via expert models. Through our experiments, we show an improved state-of-the-art (SOTA) performance with an average improvement of ~9% over the prior SOTA model Med-Gemini and ~6% over models trained on the specific tasks. Our approach emphasizes the importance of domain expertise in creating precise, reliable VLMs for medical applications.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
Optimal Transport Features for Morphometric Population Analysis
Aug 11, 2022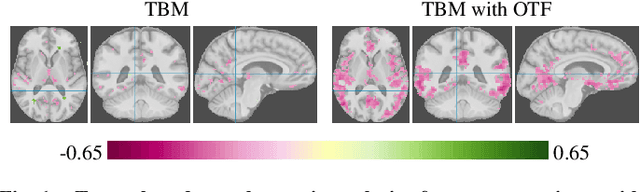
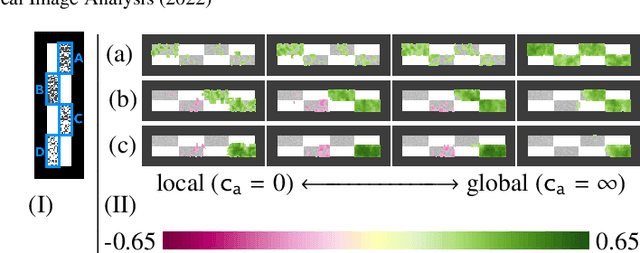
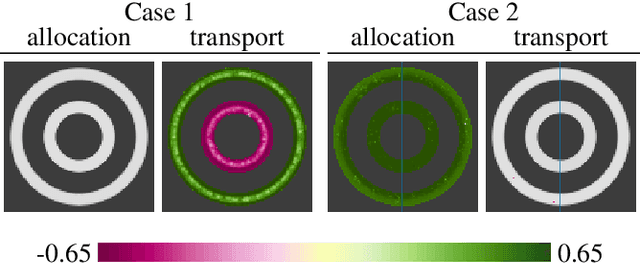
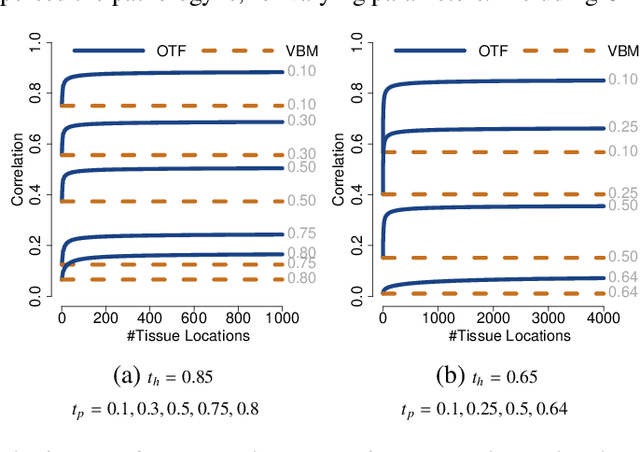
Brain pathologies often manifest as partial or complete loss of tissue. The goal of many neuroimaging studies is to capture the location and amount of tissue changes with respect to a clinical variable of interest, such as disease progression. Morphometric analysis approaches capture local differences in the distribution of tissue or other quantities of interest in relation to a clinical variable. We propose to augment morphometric analysis with an additional feature extraction step based on unbalanced optimal transport. The optimal transport feature extraction step increases statistical power for pathologies that cause spatially dispersed tissue loss, minimizes sensitivity to shifts due to spatial misalignment or differences in brain topology, and separates changes due to volume differences from changes due to tissue location. We demonstrate the proposed optimal transport feature extraction step in the context of a volumetric morphometric analysis of the OASIS-1 study for Alzheimer's disease. The results demonstrate that the proposed approach can identify tissue changes and differences that are not otherwise measurable.
Deep Decomposition for Stochastic Normal-Abnormal Transport
Nov 29, 2021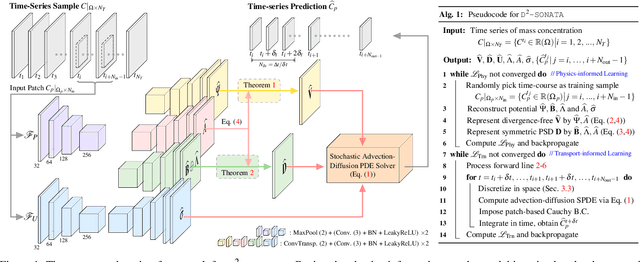
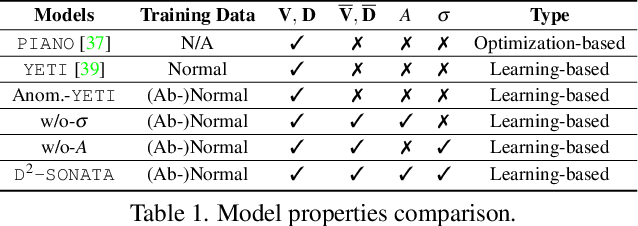
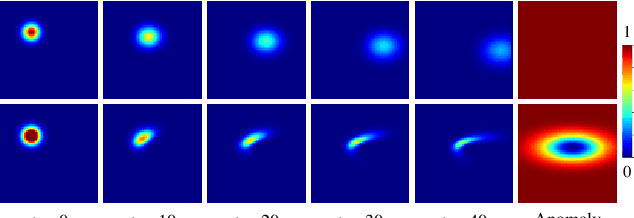
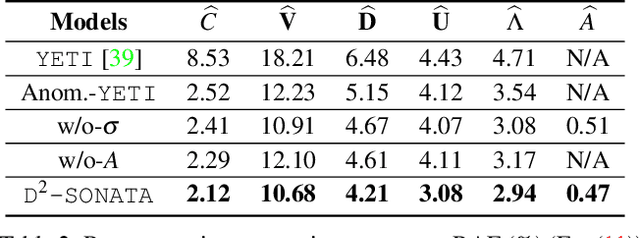
Advection-diffusion equations describe a large family of natural transport processes, e.g., fluid flow, heat transfer, and wind transport. They are also used for optical flow and perfusion imaging computations. We develop a machine learning model, D^2-SONATA, built upon a stochastic advection-diffusion equation, which predicts the velocity and diffusion fields that drive 2D/3D image time-series of transport. In particular, our proposed model incorporates a model of transport atypicality, which isolates abnormal differences between expected normal transport behavior and the observed transport. In a medical context such a normal-abnormal decomposition can be used, for example, to quantify pathologies. Specifically, our model identifies the advection and diffusion contributions from the transport time-series and simultaneously predicts an anomaly value field to provide a decomposition into normal and abnormal advection and diffusion behavior. To achieve improved estimation performance for the velocity and diffusion-tensor fields underlying the advection-diffusion process and for the estimation of the anomaly fields, we create a 2D/3D anomaly-encoded advection-diffusion simulator, which allows for supervised learning. We further apply our model on a brain perfusion dataset from ischemic stroke patients via transfer learning. Extensive comparisons demonstrate that our model successfully distinguishes stroke lesions (abnormal) from normal brain regions, while reconstructing the underlying velocity and diffusion tensor fields.
Brain Extraction from Normal and Pathological Images: A Joint PCA/Image-Reconstruction Approach
Apr 30, 2018

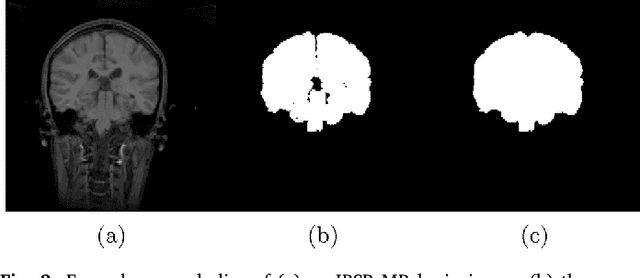

Brain extraction from images is a common pre-processing step. Many approaches exist, but they are frequently only designed to perform brain extraction from images without strong pathologies. Extracting the brain from images with strong pathologies, for example, the presence of a tumor or of a traumatic brain injury, is challenging. In such cases, tissue appearance may deviate from normal tissue and violates algorithmic assumptions for these approaches; hence, the brain may not be correctly extracted. This paper proposes a brain extraction approach which can explicitly account for pathologies by jointly modeling normal tissue and pathologies. Specifically, our model uses a three-part image decomposition: (1) normal tissue appearance is captured by principal component analysis, (2) pathologies are captured via a total variation term, and (3) non-brain tissue is captured by a sparse term. Decomposition and image registration steps are alternated to allow statistical modeling in a fixed atlas space. As a beneficial side effect, the model allows for the identification of potential pathologies and the reconstruction of a quasi-normal image in atlas space. We demonstrate the effectiveness of our method on four datasets: the IBSR and LPBA40 datasets which show normal images, the BRATS dataset containing images with brain tumors and a dataset containing clinical TBI images. We compare the performance with other popular models: ROBEX, BEaST, MASS, BET, BSE and a recently proposed deep learning approach. Our model performs better than these competing methods on all four datasets. Specifically, our model achieves the best median (97.11) and mean (96.88) Dice scores over all datasets. The two best performing competitors, ROBEX and MASS, achieve scores of 96.23/95.62 and 96.67/94.25 respectively. Hence, our approach is an effective method for high quality brain extraction on a wide variety of images.
Efficient Registration of Pathological Images: A Joint PCA/Image-Reconstruction Approach
Mar 31, 2017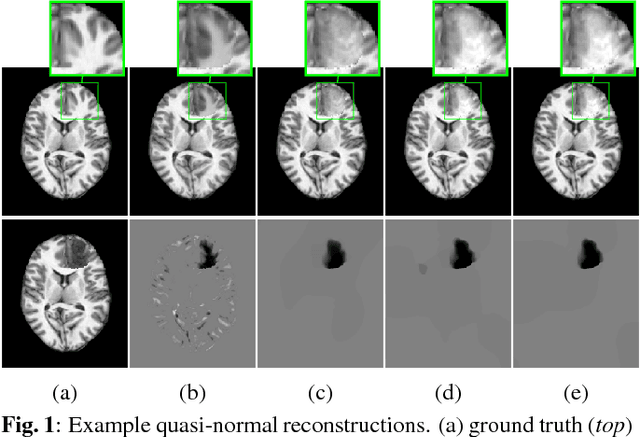


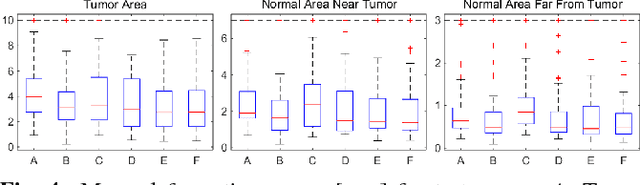
Registration involving one or more images containing pathologies is challenging, as standard image similarity measures and spatial transforms cannot account for common changes due to pathologies. Low-rank/Sparse (LRS) decomposition removes pathologies prior to registration; however, LRS is memory-demanding and slow, which limits its use on larger data sets. Additionally, LRS blurs normal tissue regions, which may degrade registration performance. This paper proposes an efficient alternative to LRS: (1) normal tissue appearance is captured by principal component analysis (PCA) and (2) blurring is avoided by an integrated model for pathology removal and image reconstruction. Results on synthetic and BRATS 2015 data demonstrate its utility.