 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology Distance: A Topology-Based Approach For Evaluating Generative Adversarial Networks
Feb 27, 2020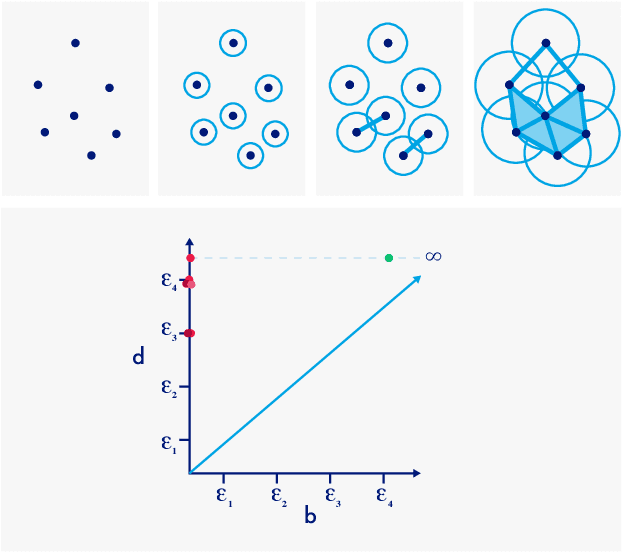
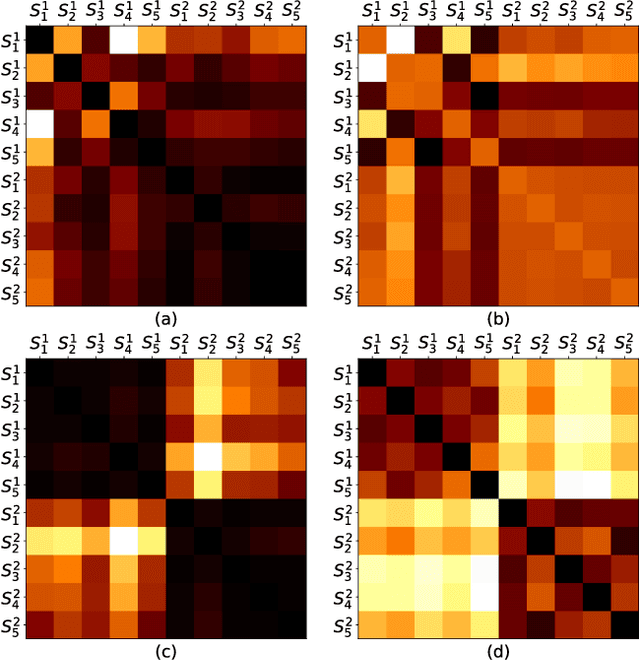
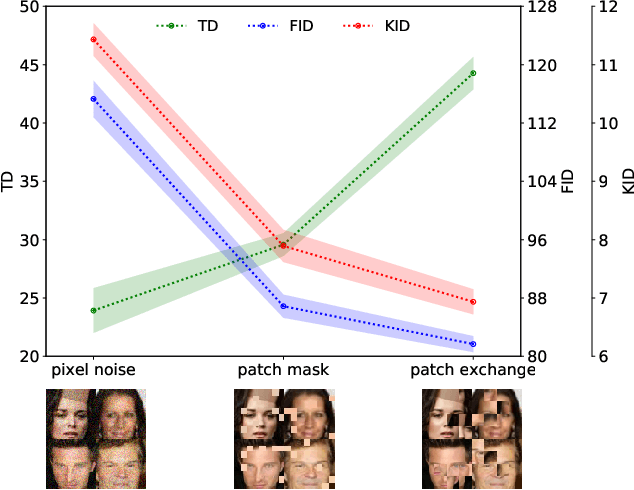
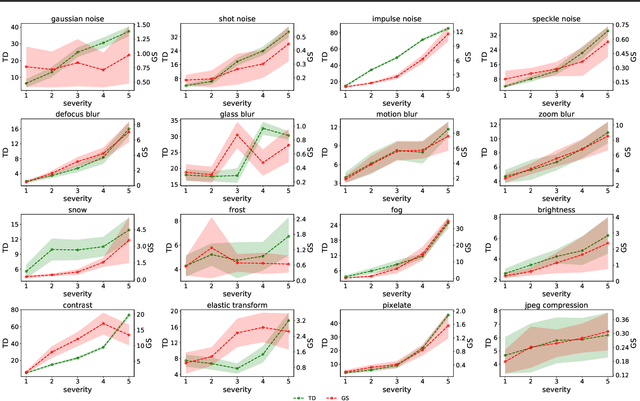
Automatic evaluation of the goodness of Generative Adversarial Networks (GANs) has been a challenge for the field of machine learning. In this work, we propose a distance complementary to existing measures: Topology Distance (TD), the main idea behind which is to compare the geometric and topological features of the latent manifold of real data with those of generated data. More specifically, we build Vietoris-Rips complex on image features, and define TD based on the differences in persistent-homology groups of the two manifolds. We compare TD with the most commonly used and relevant measures in the field, including Inception Score (IS), Frechet Inception Distance (FID), Kernel Inception Distance (KID) and Geometry Score (GS), in a range of experiments on various datasets. We demonstrate the unique advantage and superiority of our proposed approach over the aforementioned metrics. A combination of our empirical results and the theoretical argument we propose in favour of TD, strongly supports the claim that TD is a powerful candidate metric that researchers can employ when aiming to automatically evaluate the goodness of GANs' learning.
$¶$ILCRO: Making Importance Landscapes Flat Again
Feb 06, 2020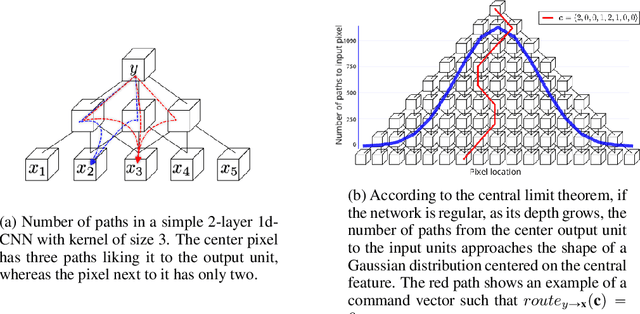
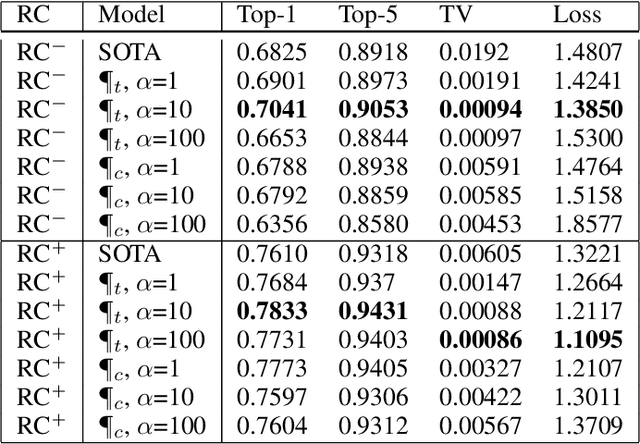
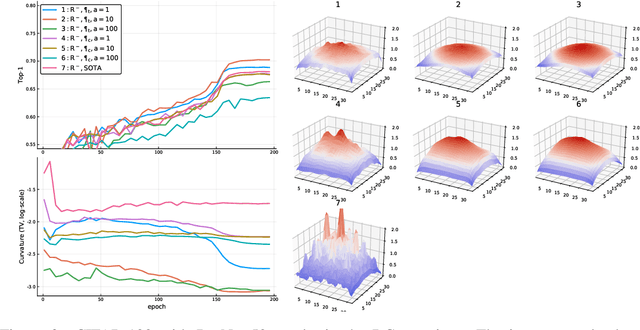
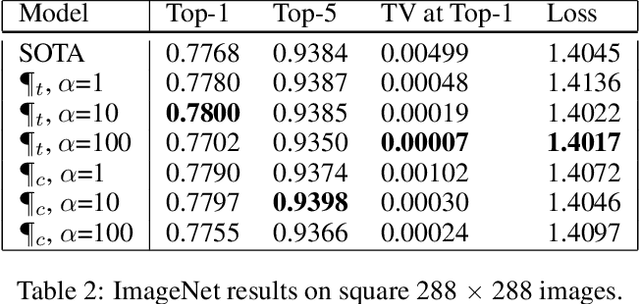
Convolutional neural networks have had a great success in numerous tasks, including image classification, object detection, sequence modelling, and many more. It is generally assumed that such neural networks are translation invariant, meaning that they can detect a given feature independent of its location in the input image. While this is true for simple cases, where networks are composed of a restricted number of layer classes and where images are fairly simple, complex images with common state-of-the-art networks do not usually enjoy this property as one might hope. This paper shows that most of the existing convolutional architectures define, at initialisation, a specific feature importance landscape that conditions their capacity to attend to different locations of the images later during training or even at test time. We demonstrate how this phenomenon occurs under specific conditions and how it can be adjusted under some assumptions. We derive the P-objective, or PILCRO for Pixel-wise Importance Landscape Curvature Regularised Objective, a simple regularisation technique that favours weight configurations that produce smooth, low-curvature importance landscapes that are conditioned on the data and not on the chosen architecture. Through extensive experiments, we further show that P-regularised versions of popular computer vision networks have a flat importance landscape, train faster, result in a better accuracy and are more robust to noise at test time, when compared to their original counterparts in common computer-vision classification settings.
Generative Creativity: Adversarial Learning for Bionic Design
May 19, 2018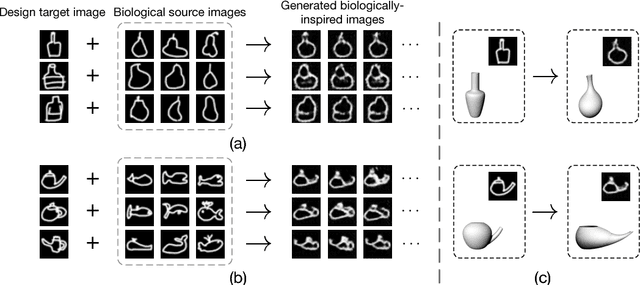
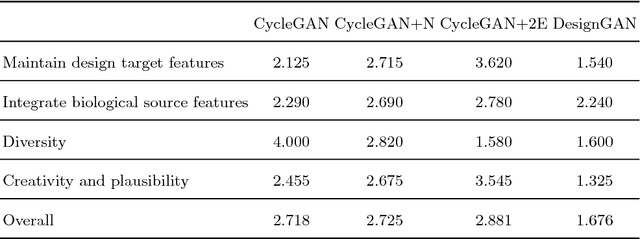
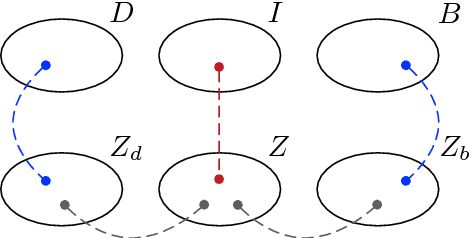
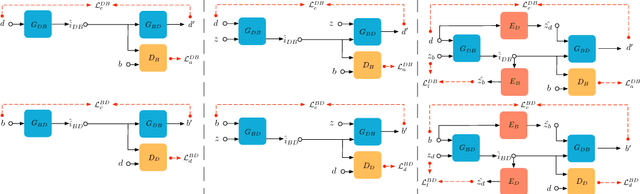
Bionic design refers to an approach of generative creativity in which a target object (e.g. a floor lamp) is designed to contain features of biological source objects (e.g. flowers), resulting in creative biologically-inspired design. In this work, we attempt to model the process of shape-oriented bionic design as follows: given an input image of a design target object, the model generates images that 1) maintain shape features of the input design target image, 2) contain shape features of images from the specified biological source domain, 3) are plausible and diverse. We propose DesignGAN, a novel unsupervised deep generative approach to realising bionic design. Specifically, we employ a conditional Generative Adversarial Networks architecture with several designated losses (an adversarial loss, a regression loss, a cycle loss and a latent loss) that respectively constrict our model to meet the corresponding aforementioned requirements of bionic design modelling. We perform qualitative and quantitative experiments to evaluate our method, and demonstrate that our proposed approach successfully generates creative images of bionic design.
TensorLayer: A Versatile Library for Efficient Deep Learning Development
Aug 03, 2017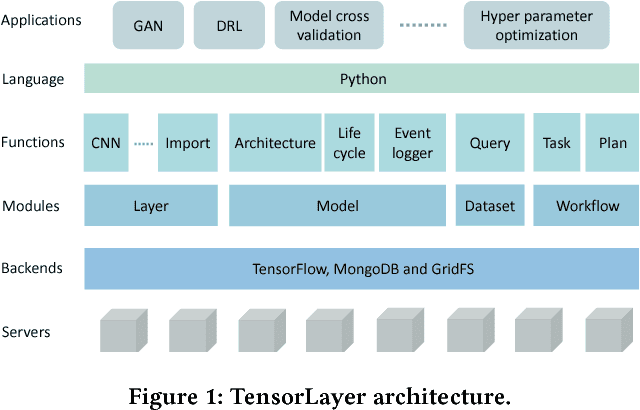

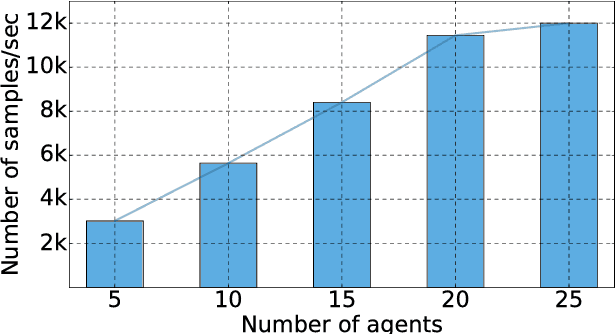
Deep learning has enabled major advances in the fields of computer vision, natural language processing, and multimedia among many others. Developing a deep learning system is arduous and complex, as it involves constructing neural network architectures, managing training/trained models, tuning optimization process, preprocessing and organizing data, etc. TensorLayer is a versatile Python library that aims at helping researchers and engineers efficiently develop deep learning systems. It offers rich abstractions for neural networks, model and data management, and parallel workflow mechanism. While boosting efficiency, TensorLayer maintains both performance and scalability. TensorLayer was released in September 2016 on GitHub, and has helped people from academia and industry develop real-world applications of deep learning.
Semantic Image Synthesis via Adversarial Learning
Jul 21, 2017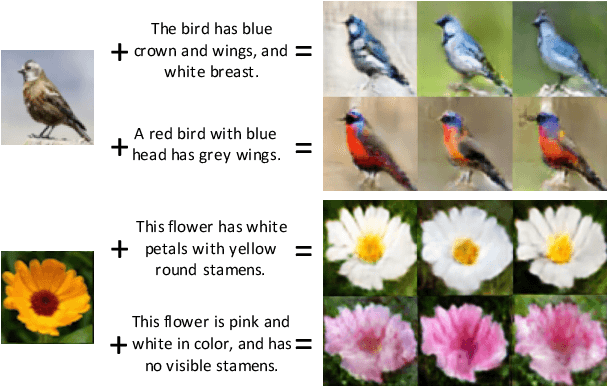
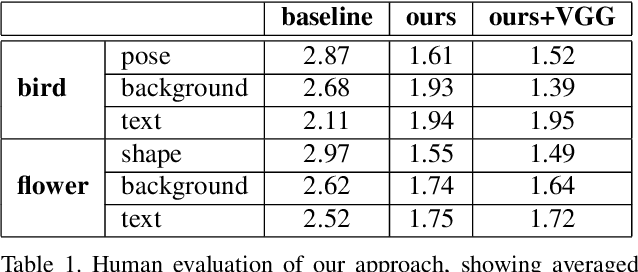
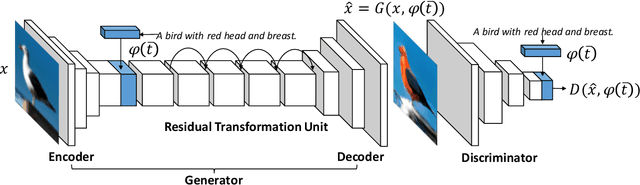

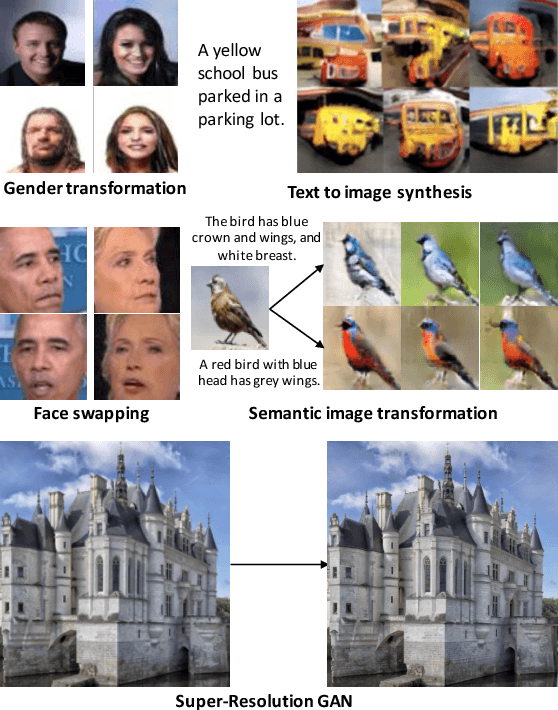
In this paper, we propose a way of synthesizing realistic images directly with natural language description, which has many useful applications, e.g. intelligent image manipulation. We attempt to accomplish such synthesis: given a source image and a target text description, our model synthesizes images to meet two requirements: 1) being realistic while matching the target text description; 2) maintaining other image features that are irrelevant to the text description. The model should be able to disentangle the semantic information from the two modalities (image and text), and generate new images from the combined semantics. To achieve this, we proposed an end-to-end neural architecture that leverages adversarial learning to automatically learn implicit loss functions, which are optimized to fulfill the aforementioned two requirements. We have evaluated our model by conducting experiments on Caltech-200 bird dataset and Oxford-102 flower dataset, and have demonstrated that our model is capable of synthesizing realistic images that match the given descriptions, while still maintain other features of original images.
Deep De-Aliasing for Fast Compressive Sensing MRI
May 19, 2017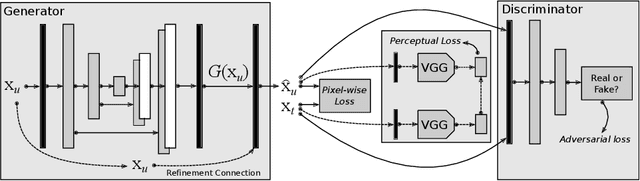
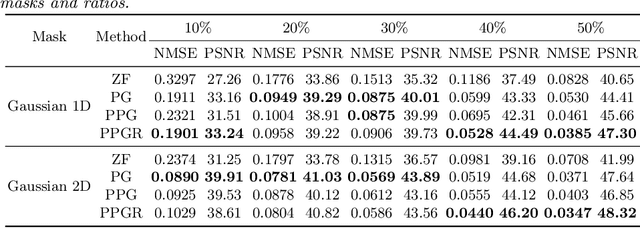
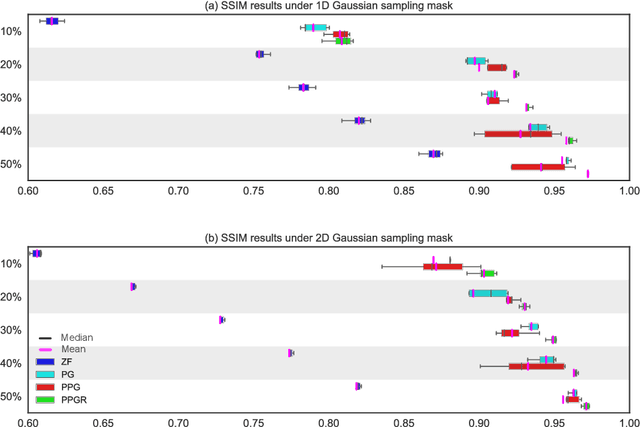
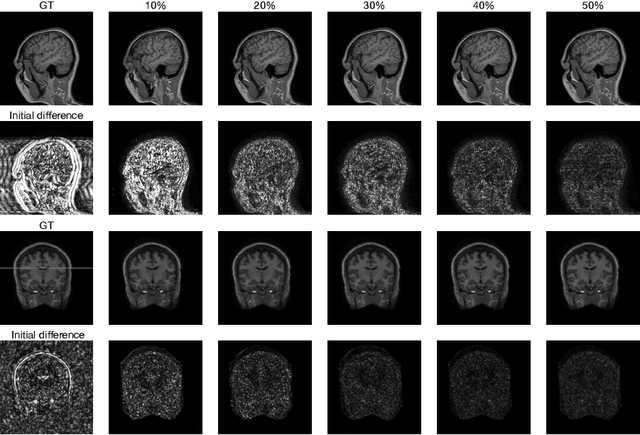
Fast Magnetic Resonance Imaging (MRI) is highly in demand for many clinical applications in order to reduce the scanning cost and improve the patient experience. This can also potentially increase the image quality by reducing the motion artefacts and contrast washout. However, once an image field of view and the desired resolution are chosen, the minimum scanning time is normally determined by the requirement of acquiring sufficient raw data to meet the Nyquist-Shannon sampling criteria. Compressive Sensing (CS) theory has been perfectly matched to the MRI scanning sequence design with much less required raw data for the image reconstruction. Inspired by recent advances in deep learning for solving various inverse problems, we propose a conditional Generative Adversarial Networks-based deep learning framework for de-aliasing and reconstructing MRI images from highly undersampled data with great promise to accelerate the data acquisition process. By coupling an innovative content loss with the adversarial loss our de-aliasing results are more realistic. Furthermore, we propose a refinement learning procedure for training the generator network, which can stabilise the training with fast convergence and less parameter tuning. We demonstrate that the proposed framework outperforms state-of-the-art CS-MRI methods, in terms of reconstruction error and perceptual image quality. In addition, our method can reconstruct each image in 0.22ms--0.37ms, which is promising for real-time applications.