 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$¶$ILCRO: Making Importance Landscapes Flat Again
Paper and Code
Feb 06, 2020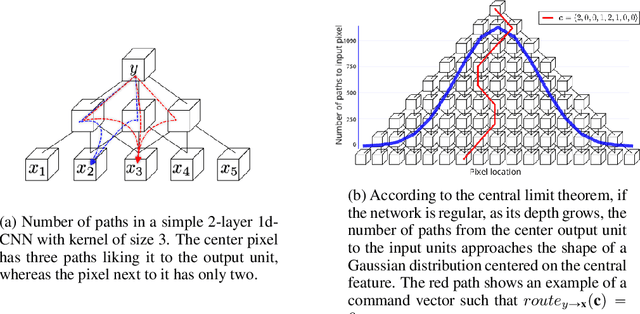
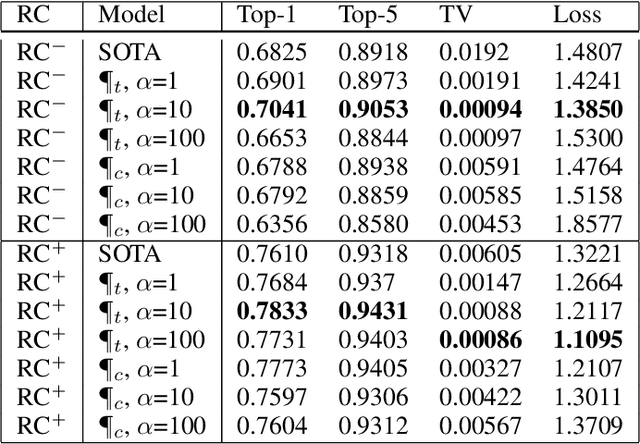
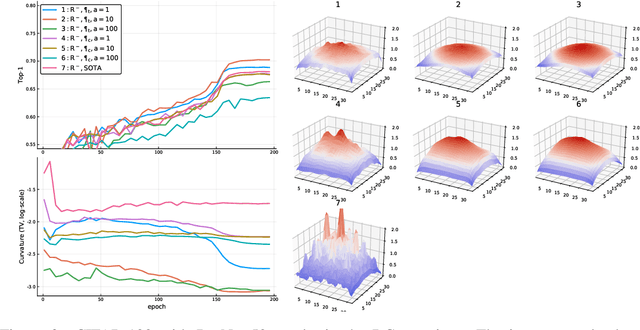
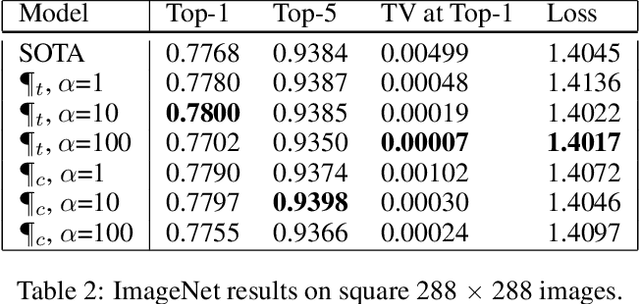
Convolutional neural networks have had a great success in numerous tasks, including image classification, object detection, sequence modelling, and many more. It is generally assumed that such neural networks are translation invariant, meaning that they can detect a given feature independent of its location in the input image. While this is true for simple cases, where networks are composed of a restricted number of layer classes and where images are fairly simple, complex images with common state-of-the-art networks do not usually enjoy this property as one might hope. This paper shows that most of the existing convolutional architectures define, at initialisation, a specific feature importance landscape that conditions their capacity to attend to different locations of the images later during training or even at test time. We demonstrate how this phenomenon occurs under specific conditions and how it can be adjusted under some assumptions. We derive the P-objective, or PILCRO for Pixel-wise Importance Landscape Curvature Regularised Objective, a simple regularisation technique that favours weight configurations that produce smooth, low-curvature importance landscapes that are conditioned on the data and not on the chosen architecture. Through extensive experiments, we further show that P-regularised versions of popular computer vision networks have a flat importance landscape, train faster, result in a better accuracy and are more robust to noise at test time, when compared to their original counterparts in common computer-vision classification settings.