 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
Apr 24, 2025Sparse attention offers a promising strategy to extend long-context capabilities in Transformer LLMs, yet its viability, its efficiency-accuracy trade-offs, and systematic scaling studies remain unexplored. To address this gap, we perform a careful comparison of training-free sparse attention methods at varying model scales, sequence lengths, and sparsity levels on a diverse collection of long-sequence tasks-including novel ones that rely on natural language while remaining controllable and easy to evaluate. Based on our experiments, we report a series of key findings: 1) an isoFLOPS analysis reveals that for very long sequences, larger and highly sparse models are preferable to smaller and dense ones. 2) The level of sparsity attainable while statistically guaranteeing accuracy preservation is higher during decoding than prefilling, and correlates with model size in the former. 3) There is no clear strategy that performs best across tasks and phases, with different units of sparsification or budget adaptivity needed for different scenarios. Even moderate sparsity levels often result in significant performance degradation on at least one task, highlighting that sparse attention is not a universal solution. 4) We introduce and validate novel scaling laws specifically tailored for sparse attention, providing evidence that our findings are likely to hold true beyond our range of experiments. Through these insights, we demonstrate that sparse attention is a key tool to enhance the capabilities of Transformer LLMs for processing longer sequences, but requires careful evaluation of trade-offs for performance-sensitive applications.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Yield Evaluation of Citrus Fruits based on the YoloV5 compressed by Knowledge Distillation
Nov 16, 2022In the field of planting fruit trees, pre-harvest estimation of fruit yield is important for fruit storage and price evaluation. However, considering the cost, the yield of each tree cannot be assessed by directly picking the immature fruit. Therefore, the problem is a very difficult task. In this paper, a fruit counting and yield assessment method based on computer vision is proposed for citrus fruit trees as an example. Firstly, images of single fruit trees from different angles are acquired and the number of fruits is detected using a deep Convolutional Neural Network model YOLOv5, and the model is compressed using a knowledge distillation method. Then, a linear regression method is used to model yield-related features and evaluate yield. Experiments show that the proposed method can accurately count fruits and approximate the yield.
Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021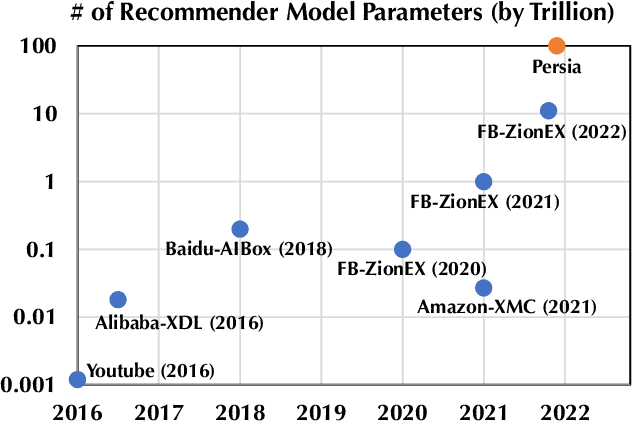
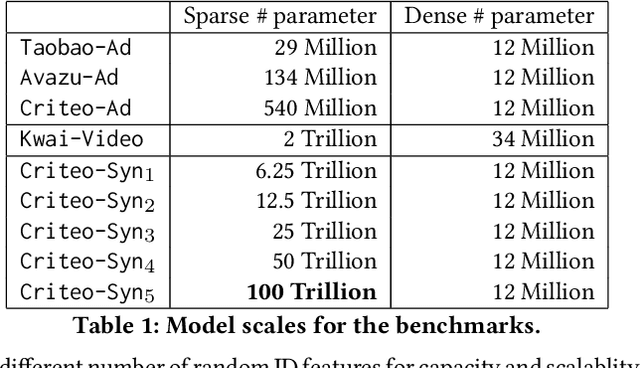
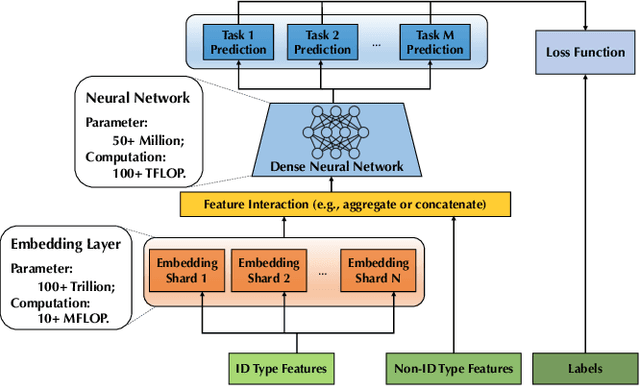
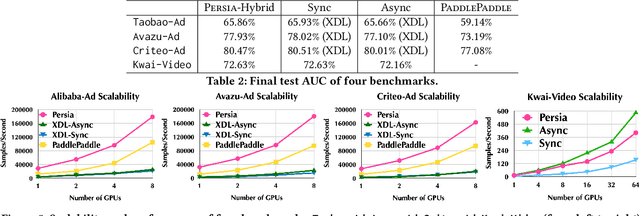
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.