 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention in Attention: Modeling Context Correlation for Efficient Video Classification
Apr 20, 2022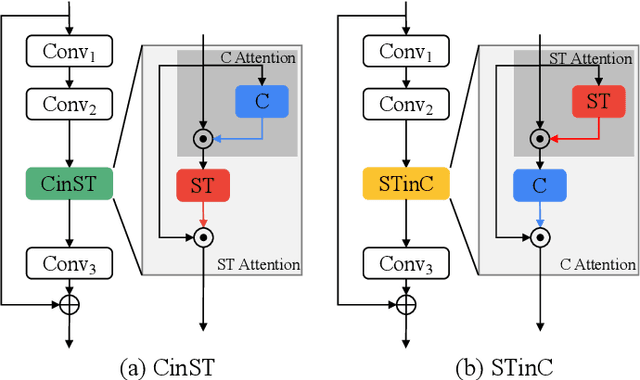
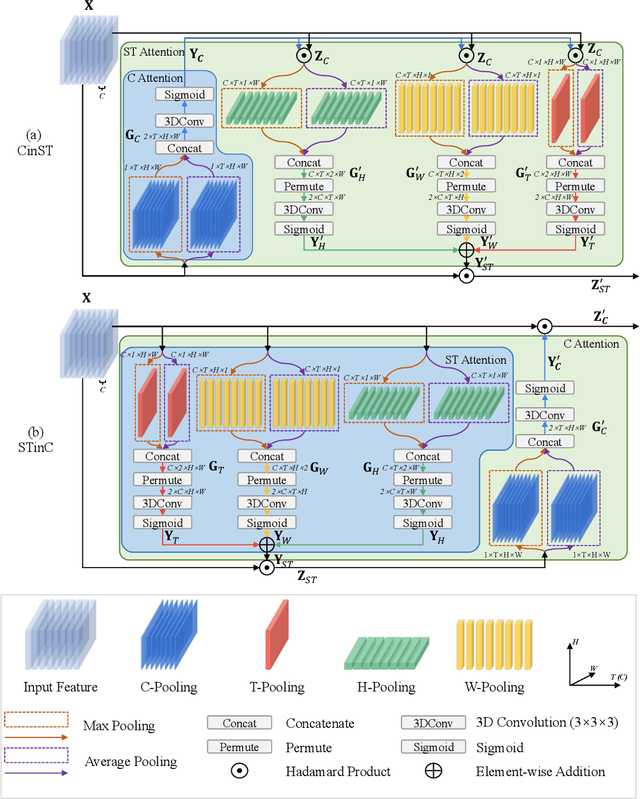

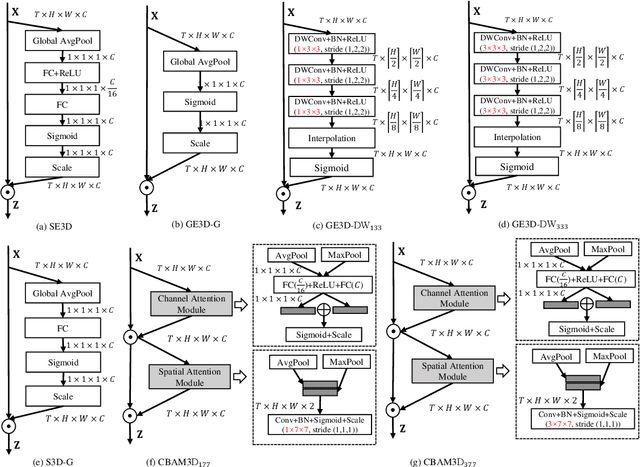
Attention mechanisms have significantly boosted the performance of video classification neural networks thanks to the utilization of perspective contexts. However, the current research on video attention generally focuses on adopting a specific aspect of contexts (e.g., channel, spatial/temporal, or global context) to refine the features and neglects their underlying correlation when computing attentions. This leads to incomplete context utilization and hence bears the weakness of limited performance improvement. To tackle the problem, this paper proposes an efficient attention-in-attention (AIA) method for element-wise feature refinement, which investigates the feasibility of inserting the channel context into the spatio-temporal attention learning module, referred to as CinST, and also its reverse variant, referred to as STinC. Specifically, we instantiate the video feature contexts as dynamics aggregated along a specific axis with global average and max pooling operations. The workflow of an AIA module is that the first attention block uses one kind of context information to guide the gating weights calculation of the second attention that targets at the other context. Moreover, all the computational operations in attention units act on the pooled dimension, which results in quite few computational cost increase ($<$0.02\%). To verify our method, we densely integrate it into two classical video network backbones and conduct extensive experiments on several standard video classification benchmarks. The source code of our AIA is available at \url{https://github.com/haoyanbin918/Attention-in-Attention}.
Mondegreen: A Post-Processing Solution to Speech Recognition Error Correction for Voice Search Queries
May 20, 2021
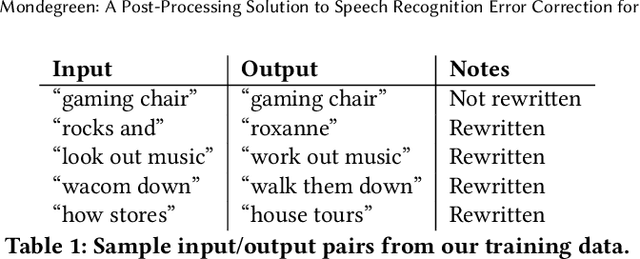


As more and more online search queries come from voice, automatic speech recognition becomes a key component to deliver relevant search results. Errors introduced by automatic speech recognition (ASR) lead to irrelevant search results returned to the user, thus causing user dissatisfaction. In this paper, we introduce an approach, Mondegreen, to correct voice queries in text space without depending on audio signals, which may not always be available due to system constraints or privacy or bandwidth (for example, some ASR systems run on-device) considerations. We focus on voice queries transcribed via several proprietary commercial ASR systems. These queries come from users making internet, or online service search queries. We first present an analysis showing how different the language distribution coming from user voice queries is from that in traditional text corpora used to train off-the-shelf ASR systems. We then demonstrate that Mondegreen can achieve significant improvements in increased user interaction by correcting user voice queries in one of the largest search systems in Google. Finally, we see Mondegreen as complementing existing highly-optimized production ASR systems, which may not be frequently retrained and thus lag behind due to vocabulary drifts.
Zero-Shot Heterogeneous Transfer Learning from Recommender Systems to Cold-Start Search Retrieval
Aug 19, 2020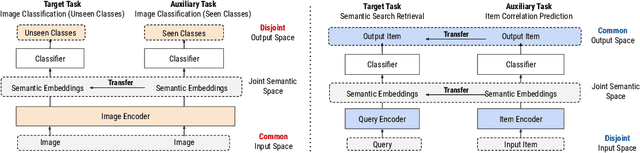

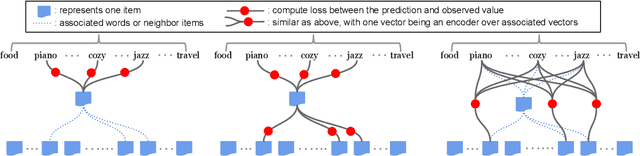
Many recent advances in neural information retrieval models, which predict top-K items given a query, learn directly from a large training set of (query, item) pairs. However, they are often insufficient when there are many previously unseen (query, item) combinations, often referred to as the cold start problem. Furthermore, the search system can be biased towards items that are frequently shown to a query previously, also known as the 'rich get richer' (a.k.a. feedback loop) problem. In light of these problems, we observed that most online content platforms have both a search and a recommender system that, while having heterogeneous input spaces, can be connected through their common output item space and a shared semantic representation. In this paper, we propose a new Zero-Shot Heterogeneous Transfer Learning framework that transfers learned knowledge from the recommender system component to improve the search component of a content platform. First, it learns representations of items and their natural-language features by predicting (item, item) correlation graphs derived from the recommender system as an auxiliary task. Then, the learned representations are transferred to solve the target search retrieval task, performing query-to-item prediction without having seen any (query, item) pairs in training. We conduct online and offline experiments on one of the world's largest search and recommender systems from Google, and present the results and lessons learned. We demonstrate that the proposed approach can achieve high performance on offline search retrieval tasks, and more importantly, achieved significant improvements on relevance and user interactions over the highly-optimized production system in online experiments.
Leveraging Gaussian Process and Voting-Empowered Many-Objective Evaluation for Fault Identification
Oct 29, 2018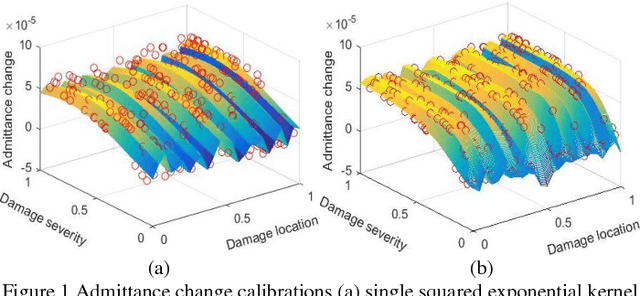
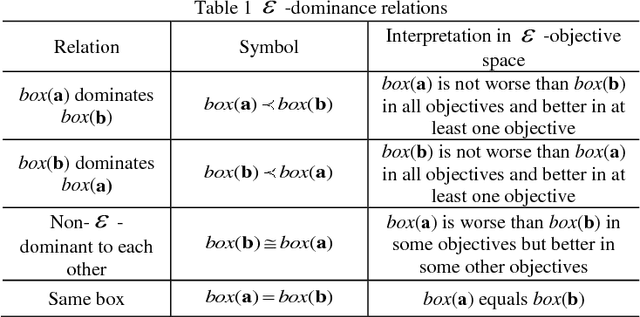
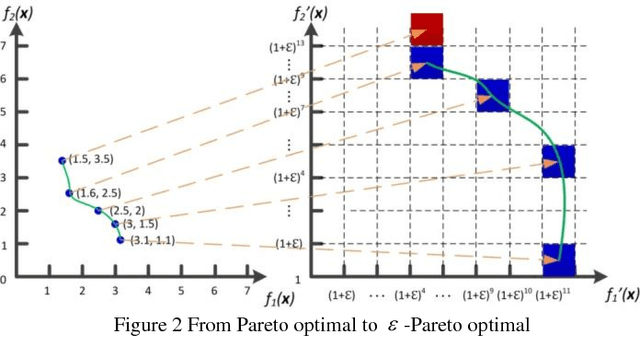
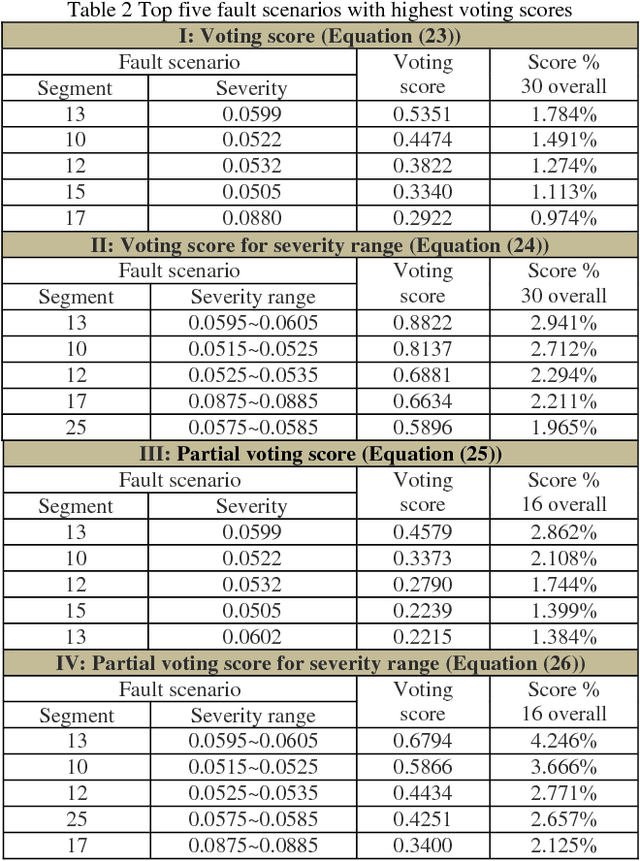
Using piezoelectric impedance/admittance sensing for structural health monitoring is promising, owing to the simplicity in circuitry design as well as the high-frequency interrogation capability. The actual identification of fault location and severity using impedance/admittance measurements, nevertheless, remains to be an extremely challenging task. A first-principle based structural model using finite element discretization requires high dimensionality to characterize the high-frequency response. As such, direct inversion using the sensitivity matrix usually yields an under-determined problem. Alternatively, the identification problem may be cast into an optimization framework in which fault parameters are identified through repeated forward finite element analysis which however is oftentimes computationally prohibitive. This paper presents an efficient data-assisted optimization approach for fault identification without using finite element model iteratively. We formulate a many-objective optimization problem to identify fault parameters, where response surfaces of impedance measurements are constructed through Gaussian process-based calibration. To balance between solution diversity and convergence, an -dominance enabled many-objective simulated annealing algorithm is established. As multiple solutions are expected, a voting score calculation procedure is developed to further identify those solutions that yield better implications regarding structural health condition. The effectiveness of the proposed approach is demonstrated by systematic numerical and experimental case studies.
Pre-Processing-Free Gear Fault Diagnosis Using Small Datasets with Deep Convolutional Neural Network-Based Transfer Learning
Oct 24, 2017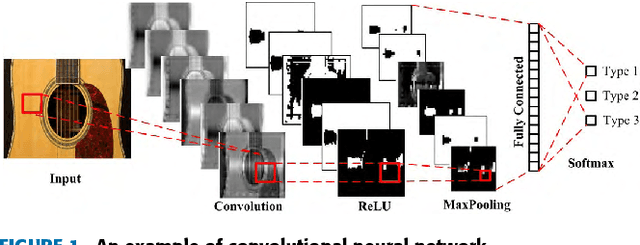
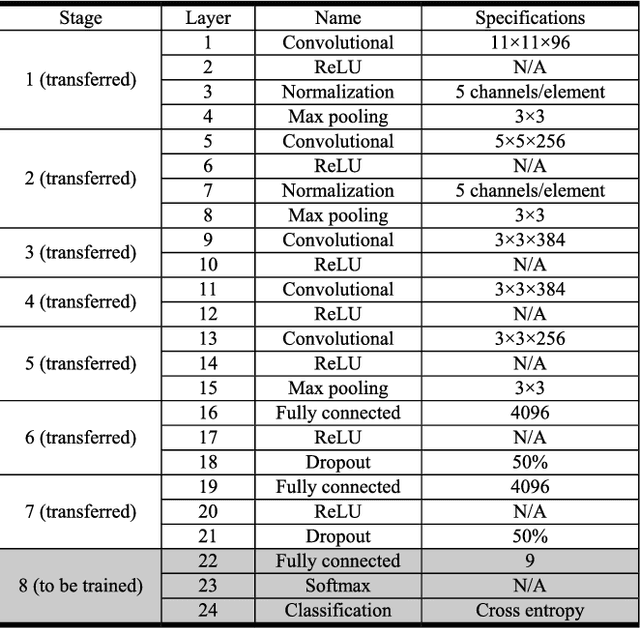
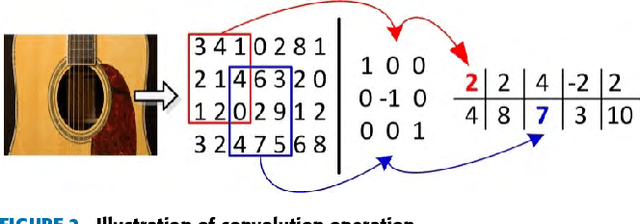
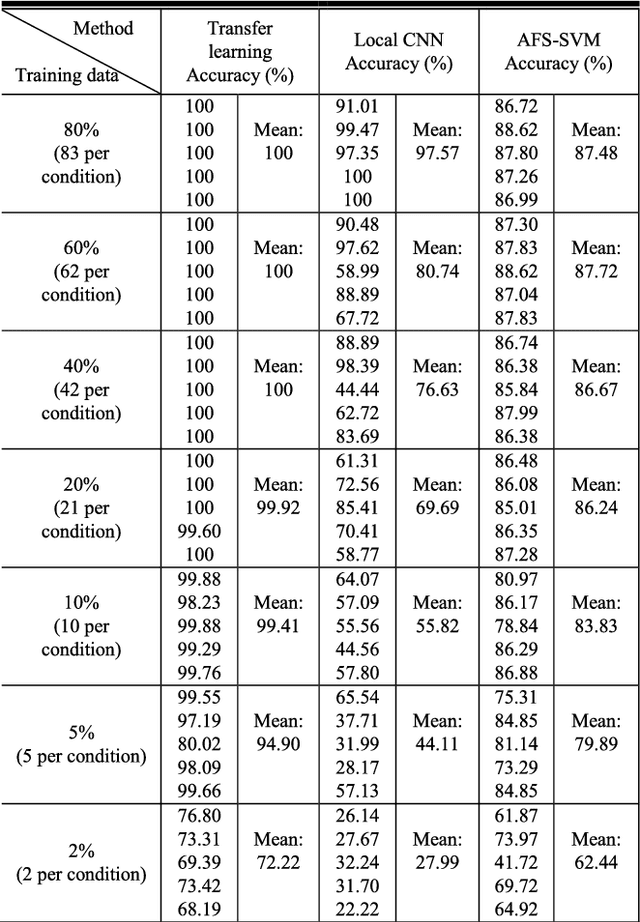
Early fault diagnosis in complex mechanical systems such as gearbox has always been a great challenge, even with the recent development in deep neural networks. The performance of a classic fault diagnosis system predominantly depends on the features extracted and the classifier subsequently applied. Although a large number of attempts have been made regarding feature extraction techniques, the methods require great human involvements are heavily depend on domain expertise and may thus be non-representative and biased from application to application. On the other hand, while the deep neural networks based approaches feature adaptive feature extractions and inherent classifications, they usually require a substantial set of training data and thus hinder their usage for engineering applications with limited training data such as gearbox fault diagnosis. This paper develops a deep convolutional neural network-based transfer learning approach that not only entertains pre-processing free adaptive feature extractions, but also requires only a small set of training data. The proposed approach performs gear fault diagnosis using pre-processing free raw accelerometer data and experiments with various sizes of training data were conducted. The superiority of the proposed approach is revealed by comparing the performance with other methods such as locally trained convolution neural network and angle-frequency analysis based support vector machine. The achieved accuracy indicates that the proposed approach is not only viable and robust, but also has the potential to be readily applicable to other fault diagnosis practices.
A Focal Any-Angle Path-finding Algorithm Based on A* on Visibility Graphs
Jun 09, 2017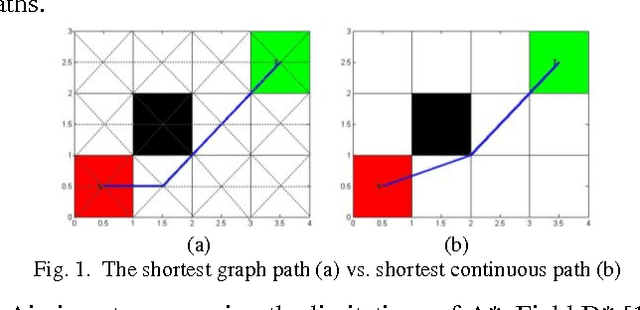
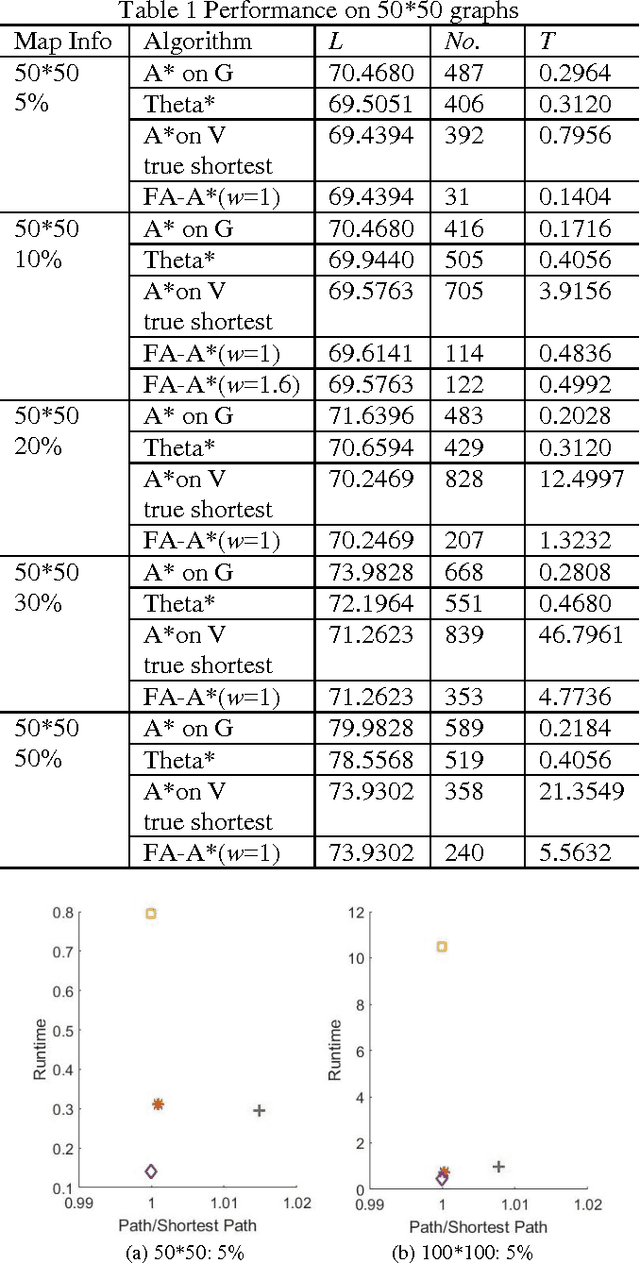
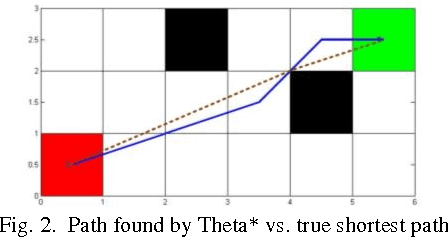
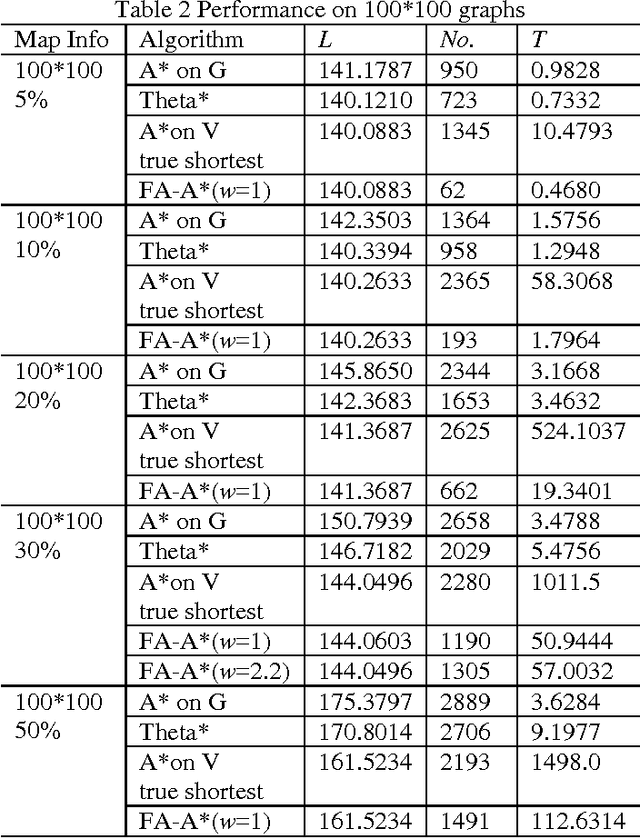
In this research, we investigate the subject of path-finding. A pruned version of visibility graph based on Candidate Vertices is formulated, followed by a new visibility check technique. Such combination enables us to quickly identify the useful vertices and thus find the optimal path more efficiently. The algorithm proposed is demonstrated on various path-finding cases. The performance of the new technique on visibility graphs is compared to the traditional A* on Grids, Theta* and A* on Visibility Graphs in terms of path length, number of nodes evaluated, as well as computational time. The key algorithmic contribution is that the new approach combines the merits of grid-based method and visibility graph-based method and thus yields better overall performance.