 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Improving End-to-End Speech Processing by Efficient Text Data Utilization with Latent Synthesis
Oct 24, 2023Training a high performance end-to-end speech (E2E) processing model requires an enormous amount of labeled speech data, especially in the era of data-centric artificial intelligence. However, labeled speech data are usually scarcer and more expensive for collection, compared to textual data. We propose Latent Synthesis (LaSyn), an efficient textual data utilization framework for E2E speech processing models. We train a latent synthesizer to convert textual data into an intermediate latent representation of a pre-trained speech model. These pseudo acoustic representations of textual data augment acoustic data for model training. We evaluate LaSyn on low-resource automatic speech recognition (ASR) and spoken language understanding (SLU) tasks. For ASR, LaSyn improves an E2E baseline trained on LibriSpeech train-clean-100, with relative word error rate reductions over 22.3% on different test sets. For SLU, LaSyn improves our E2E baseline by absolute 4.1% for intent classification accuracy and 3.8% for slot filling SLU-F1 on SLURP, and absolute 4.49% and 2.25% for exact match (EM) and EM-Tree accuracies on STOP respectively. With fewer parameters, the results of LaSyn are competitive to published state-of-the-art works. The results demonstrate the quality of the augmented training data.
CorrectSpeech: A Fully Automated System for Speech Correction and Accent Reduction
Apr 12, 2022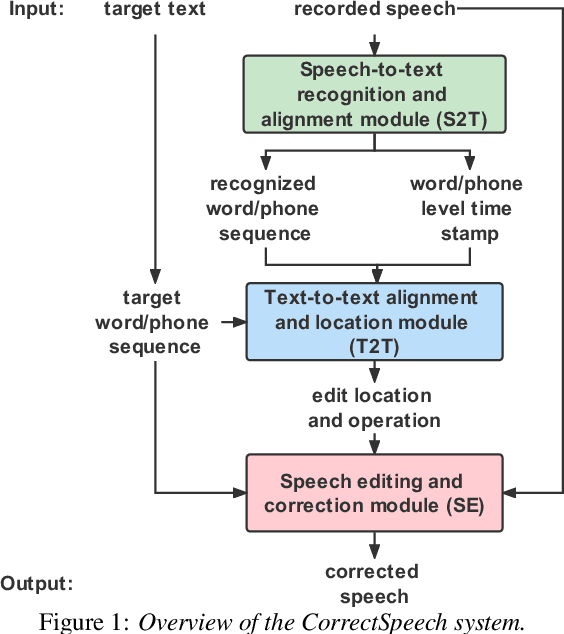
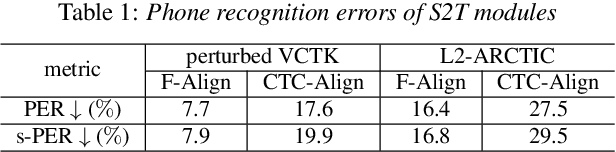
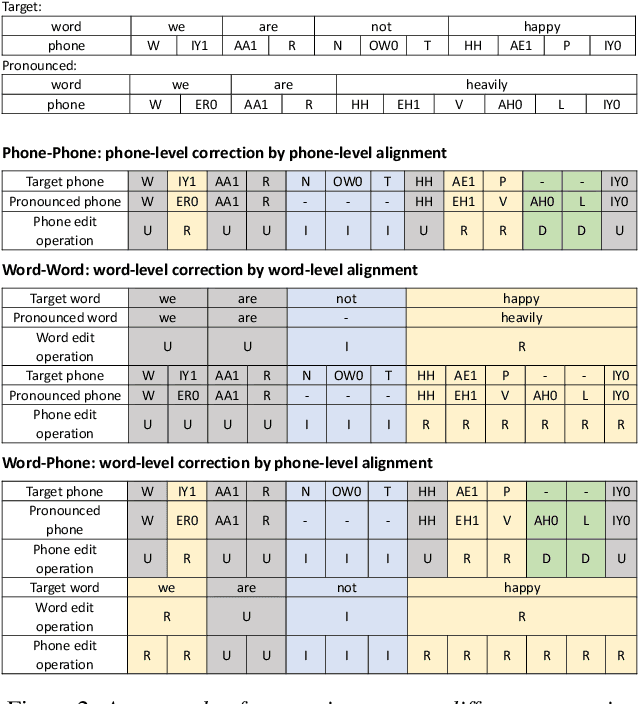
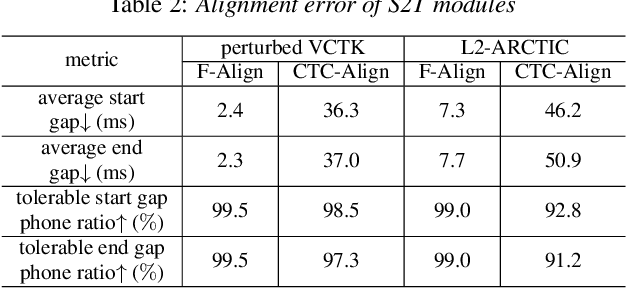
This study extends our previous work on text-based speech editing to developing a fully automated system for speech correction and accent reduction. Consider the application scenario that a recorded speech audio contains certain errors, e.g., inappropriate words, mispronunciations, that need to be corrected. The proposed system, named CorrectSpeech, performs the correction in three steps: recognizing the recorded speech and converting it into time-stamped symbol sequence, aligning recognized symbol sequence with target text to determine locations and types of required edit operations, and generating the corrected speech. Experiments show that the quality and naturalness of corrected speech depend on the performance of speech recognition and alignment modules, as well as the granularity level of editing operations. The proposed system is evaluated on two corpora: a manually perturbed version of VCTK and L2-ARCTIC. The results demonstrate that our system is able to correct mispronunciation and reduce accent in speech recordings. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/CorrectSpeech/ .
CCA-MDD: A Coupled Cross-Attention based Framework for Streaming Mispronunciation detection and diagnosis
Nov 16, 2021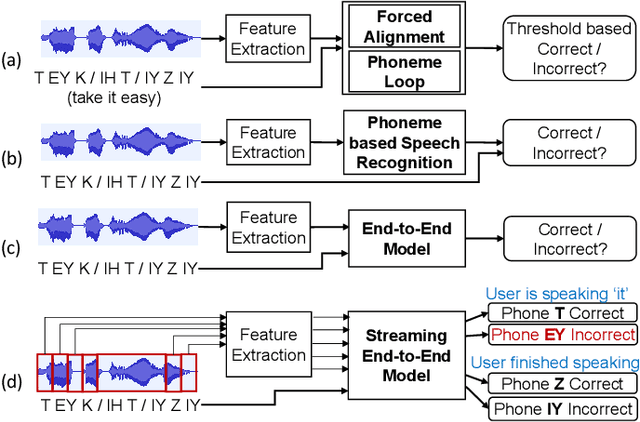
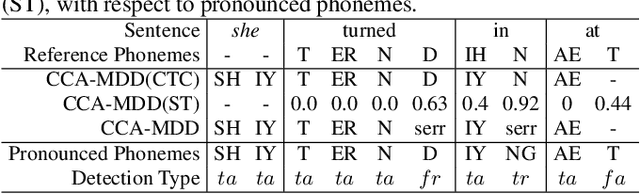
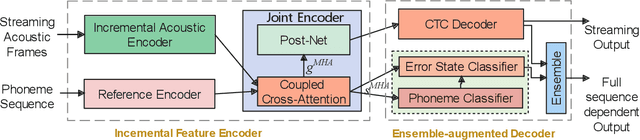

End-to-end models are becoming popular approaches for mispronunciation detection and diagnosis (MDD). A streaming MDD framework which is demanded by many practical applications still remains a challenge. This paper proposes a streaming end-to-end MDD framework called CCA-MDD. CCA-MDD supports online processing and is able to run strictly in real-time. The encoder of CCA-MDD consists of a conv-Transformer network based streaming acoustic encoder and an improved cross-attention named coupled cross-attention (CCA). The coupled cross-attention integrates encoded acoustic features with pre-encoded linguistic features. An ensemble of decoders trained from multi-task learning is applied for final MDD decision. Experiments on publicly available corpora demonstrate that CCA-MDD achieves comparable performance to published offline end-to-end MDD models.