 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCA-MDD: A Coupled Cross-Attention based Framework for Streaming Mispronunciation detection and diagnosis
Nov 16, 2021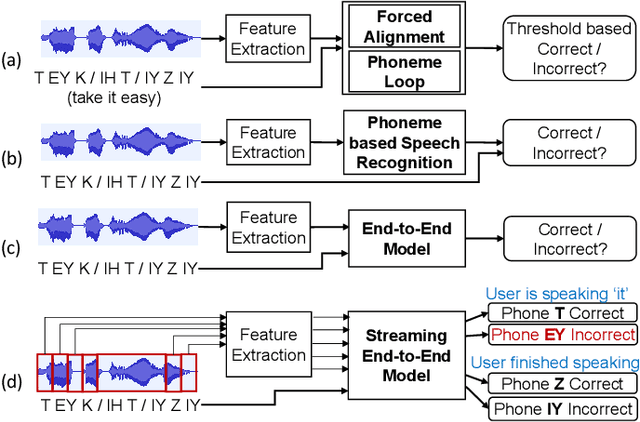
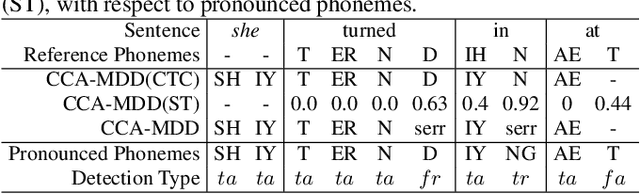
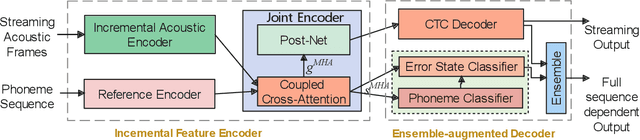

End-to-end models are becoming popular approaches for mispronunciation detection and diagnosis (MDD). A streaming MDD framework which is demanded by many practical applications still remains a challenge. This paper proposes a streaming end-to-end MDD framework called CCA-MDD. CCA-MDD supports online processing and is able to run strictly in real-time. The encoder of CCA-MDD consists of a conv-Transformer network based streaming acoustic encoder and an improved cross-attention named coupled cross-attention (CCA). The coupled cross-attention integrates encoded acoustic features with pre-encoded linguistic features. An ensemble of decoders trained from multi-task learning is applied for final MDD decision. Experiments on publicly available corpora demonstrate that CCA-MDD achieves comparable performance to published offline end-to-end MDD models.