 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Social Event Detection via Hybrid Graph Contrastive Learning and Reinforced Incremental Clustering
Dec 15, 2023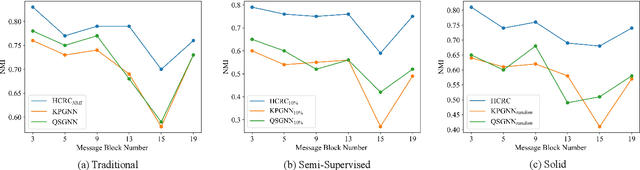


Detecting events from social media data streams is gradually attracting researchers. The innate challenge for detecting events is to extract discriminative information from social media data thereby assigning the data into different events. Due to the excessive diversity and high updating frequency of social data, using supervised approaches to detect events from social messages is hardly achieved. To this end, recent works explore learning discriminative information from social messages by leveraging graph contrastive learning (GCL) and embedding clustering in an unsupervised manner. However, two intrinsic issues exist in benchmark methods: conventional GCL can only roughly explore partial attributes, thereby insufficiently learning the discriminative information of social messages; for benchmark methods, the learned embeddings are clustered in the latent space by taking advantage of certain specific prior knowledge, which conflicts with the principle of unsupervised learning paradigm. In this paper, we propose a novel unsupervised social media event detection method via hybrid graph contrastive learning and reinforced incremental clustering (HCRC), which uses hybrid graph contrastive learning to comprehensively learn semantic and structural discriminative information from social messages and reinforced incremental clustering to perform efficient clustering in a solidly unsupervised manner. We conduct comprehensive experiments to evaluate HCRC on the Twitter and Maven datasets. The experimental results demonstrate that our approach yields consistent significant performance boosts. In traditional incremental setting, semi-supervised incremental setting and solidly unsupervised setting, the model performance has achieved maximum improvements of 53%, 45%, and 37%, respectively.
M2HGCL: Multi-Scale Meta-Path Integrated Heterogeneous Graph Contrastive Learning
Sep 03, 2023Inspired by the successful application of contrastive learning on graphs, researchers attempt to impose graph contrastive learning approaches on heterogeneous information networks. Orthogonal to homogeneous graphs, the types of nodes and edges in heterogeneous graphs are diverse so that specialized graph contrastive learning methods are required. Most existing methods for heterogeneous graph contrastive learning are implemented by transforming heterogeneous graphs into homogeneous graphs, which may lead to ramifications that the valuable information carried by non-target nodes is undermined thereby exacerbating the performance of contrastive learning models. Additionally, current heterogeneous graph contrastive learning methods are mainly based on initial meta-paths given by the dataset, yet according to our deep-going exploration, we derive empirical conclusions: only initial meta-paths cannot contain sufficiently discriminative information; and various types of meta-paths can effectively promote the performance of heterogeneous graph contrastive learning methods. To this end, we propose a new multi-scale meta-path integrated heterogeneous graph contrastive learning (M2HGCL) model, which discards the conventional heterogeneity-homogeneity transformation and performs the graph contrastive learning in a joint manner. Specifically, we expand the meta-paths and jointly aggregate the direct neighbor information, the initial meta-path neighbor information and the expanded meta-path neighbor information to sufficiently capture discriminative information. A specific positive sampling strategy is further imposed to remedy the intrinsic deficiency of contrastive learning, i.e., the hard negative sample sampling issue. Through extensive experiments on three real-world datasets, we demonstrate that M2HGCL outperforms the current state-of-the-art baseline models.
CCA-MDD: A Coupled Cross-Attention based Framework for Streaming Mispronunciation detection and diagnosis
Nov 16, 2021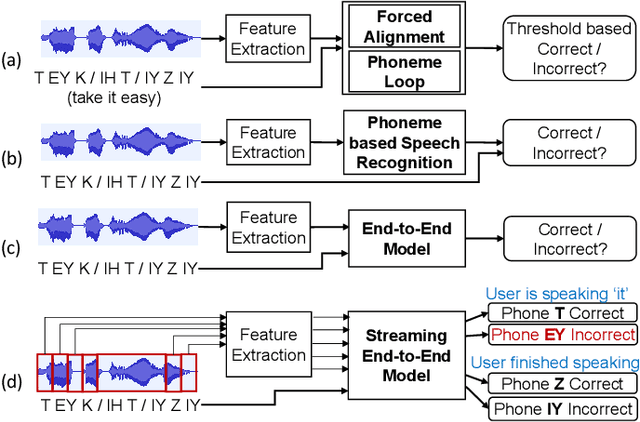
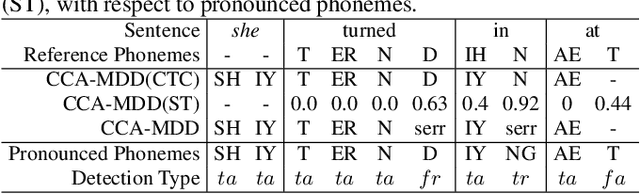
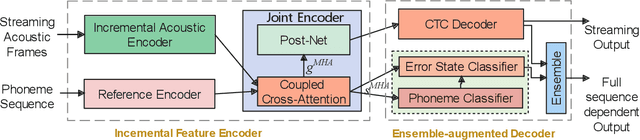

End-to-end models are becoming popular approaches for mispronunciation detection and diagnosis (MDD). A streaming MDD framework which is demanded by many practical applications still remains a challenge. This paper proposes a streaming end-to-end MDD framework called CCA-MDD. CCA-MDD supports online processing and is able to run strictly in real-time. The encoder of CCA-MDD consists of a conv-Transformer network based streaming acoustic encoder and an improved cross-attention named coupled cross-attention (CCA). The coupled cross-attention integrates encoded acoustic features with pre-encoded linguistic features. An ensemble of decoders trained from multi-task learning is applied for final MDD decision. Experiments on publicly available corpora demonstrate that CCA-MDD achieves comparable performance to published offline end-to-end MDD models.