 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemlirSynth: Automatic, Retargetable Program Raising in Multi-Level IR using Program Synthesis
Oct 06, 2023MLIR is an emerging compiler infrastructure for modern hardware, but existing programs cannot take advantage of MLIR's high-performance compilation if they are described in lower-level general purpose languages. Consequently, to avoid programs needing to be rewritten manually, this has led to efforts to automatically raise lower-level to higher-level dialects in MLIR. However, current methods rely on manually-defined raising rules, which limit their applicability and make them challenging to maintain as MLIR dialects evolve. We present mlirSynth -- a novel approach which translates programs from lower-level MLIR dialects to high-level ones without manually defined rules. Instead, it uses available dialect definitions to construct a program space and searches it effectively using type constraints and equivalences. We demonstrate its effectiveness \revi{by raising C programs} to two distinct high-level MLIR dialects, which enables us to use existing high-level dialect specific compilation flows. On Polybench, we show a greater coverage than previous approaches, resulting in geomean speedups of 2.5x (Intel) and 3.4x (AMD) over state-of-the-art compilation flows for the C programming language. mlirSynth also enables retargetability to domain-specific accelerators, resulting in a geomean speedup of 21.6x on a TPU.
SLaDe: A Portable Small Language Model Decompiler for Optimized Assembler
May 21, 2023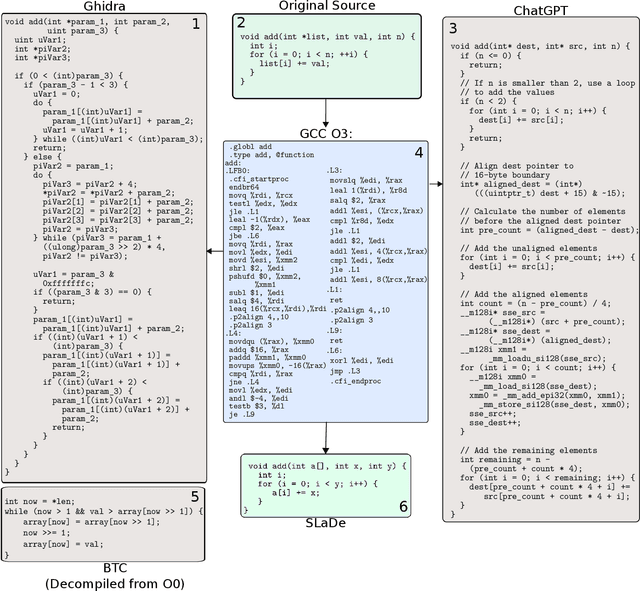
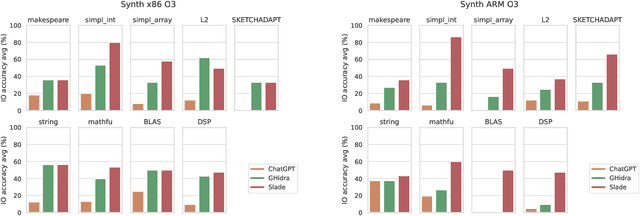
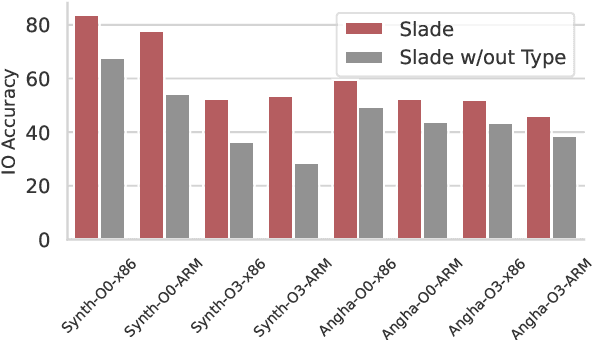

Decompilation is a well-studied area with numerous high-quality tools available. These are frequently used for security tasks and to port legacy code. However, they regularly generate difficult-to-read programs and require a large amount of engineering effort to support new programming languages and ISAs. Recent interest in neural approaches has produced portable tools that generate readable code. However, to-date such techniques are usually restricted to synthetic programs without optimization, and no models have evaluated their portability. Furthermore, while the code generated may be more readable, it is usually incorrect. This paper presents SLaDe, a Small Language model Decompiler based on a sequence-to-sequence transformer trained over real-world code. We develop a novel tokenizer and exploit no-dropout training to produce high-quality code. We utilize type-inference to generate programs that are more readable and accurate than standard analytic and recent neural approaches. Unlike standard approaches, SLaDe can infer out-of-context types and unlike neural approaches, it generates correct code. We evaluate SLaDe on over 4,000 functions from AnghaBench on two ISAs and at two optimizations levels. SLaDe is up to 6 times more accurate than Ghidra, a state-of-the-art, industrial-strength decompiler and up to 4 times more accurate than the large language model ChatGPT and generates significantly more readable code than both.
Learning C to x86 Translation: An Experiment in Neural Compilation
Aug 17, 2021



Deep learning has had a significant impact on many fields. Recently, code-to-code neural models have been used in code translation, code refinement and decompilation. However, the question of whether these models can automate compilation has yet to be investigated. In this work, we explore neural compilation, building and evaluating Transformer models that learn how to produce x86 assembler from C code. Although preliminary results are relatively weak, we make our data, models and code publicly available to encourage further research in this area.
TASO: Time and Space Optimization for Memory-Constrained DNN Inference
May 21, 2020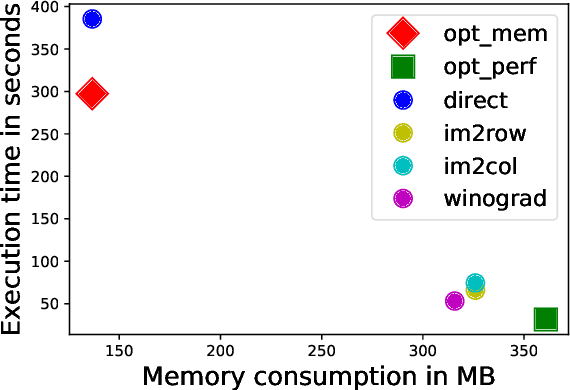
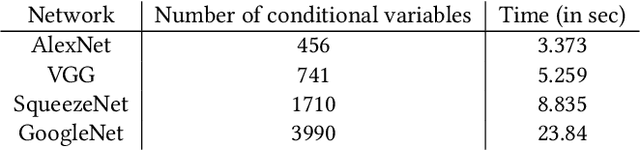

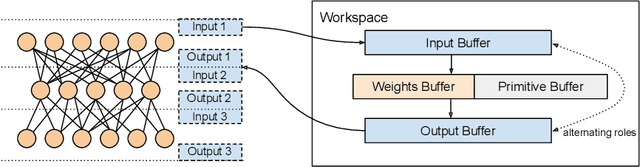
Convolutional neural networks (CNNs) are used in many embedded applications, from industrial robotics and automation systems to biometric identification on mobile devices. State-of-the-art classification is typically achieved by large networks, which are prohibitively expensive to run on mobile and embedded devices with tightly constrained memory and energy budgets. We propose an approach for ahead-of-time domain specific optimization of CNN models, based on an integer linear programming (ILP) for selecting primitive operations to implement convolutional layers. We optimize the trade-off between execution time and memory consumption by: 1) attempting to minimize execution time across the whole network by selecting data layouts and primitive operations to implement each layer; and 2) allocating an appropriate workspace that reflects the upper bound of memory footprint per layer. These two optimization strategies can be used to run any CNN on any platform with a C compiler. Our evaluation with a range of popular ImageNet neural architectures (GoogleNet, AlexNet, VGG, ResNet and SqueezeNet) on the ARM Cortex-A15 yields speedups of 8x compared to a greedy algorithm based primitive selection, reduces memory requirement by 2.2x while sacrificing only 15% of inference time compared to a solver that considers inference time only. In addition, our optimization approach exposes a range of optimal points for different configurations across the Pareto frontier of memory and latency trade-off, which can be used under arbitrary system constraints.
Navigating the Landscape for Real-time Localisation and Mapping for Robotics and Virtual and Augmented Reality
Aug 20, 2018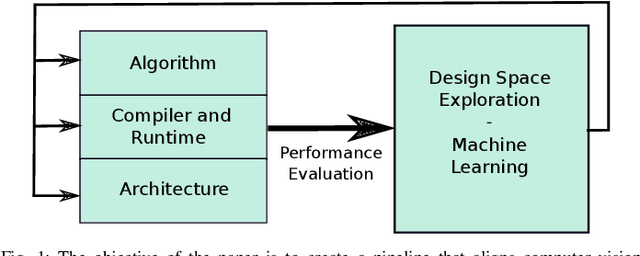

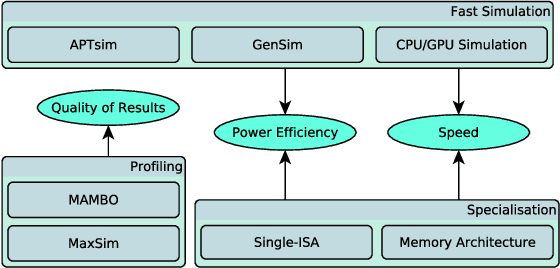
Visual understanding of 3D environments in real-time, at low power, is a huge computational challenge. Often referred to as SLAM (Simultaneous Localisation and Mapping), it is central to applications spanning domestic and industrial robotics, autonomous vehicles, virtual and augmented reality. This paper describes the results of a major research effort to assemble the algorithms, architectures, tools, and systems software needed to enable delivery of SLAM, by supporting applications specialists in selecting and configuring the appropriate algorithm and the appropriate hardware, and compilation pathway, to meet their performance, accuracy, and energy consumption goals. The major contributions we present are (1) tools and methodology for systematic quantitative evaluation of SLAM algorithms, (2) automated, machine-learning-guided exploration of the algorithmic and implementation design space with respect to multiple objectives, (3) end-to-end simulation tools to enable optimisation of heterogeneous, accelerated architectures for the specific algorithmic requirements of the various SLAM algorithmic approaches, and (4) tools for delivering, where appropriate, accelerated, adaptive SLAM solutions in a managed, JIT-compiled, adaptive runtime context.
Introducing SLAMBench, a performance and accuracy benchmarking methodology for SLAM
Feb 26, 2015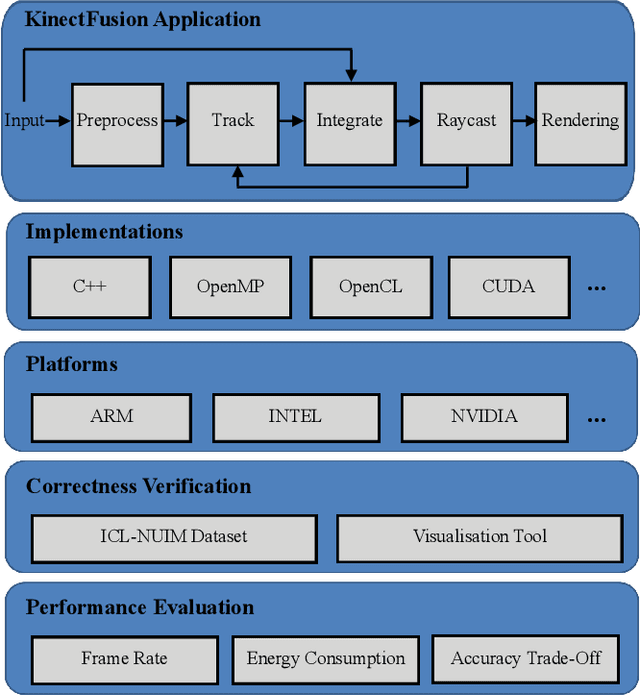

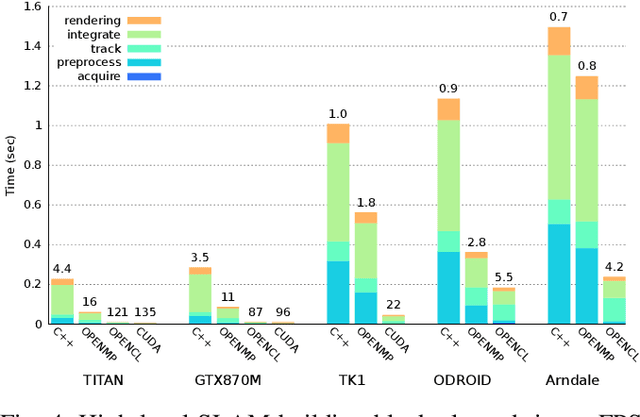
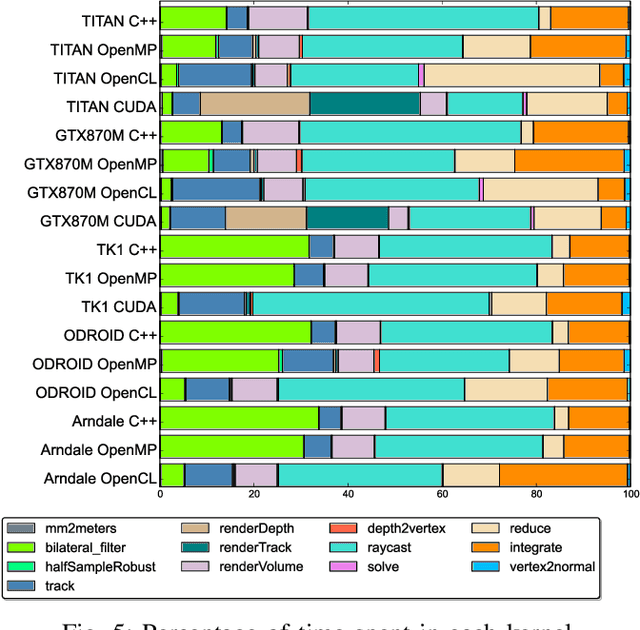
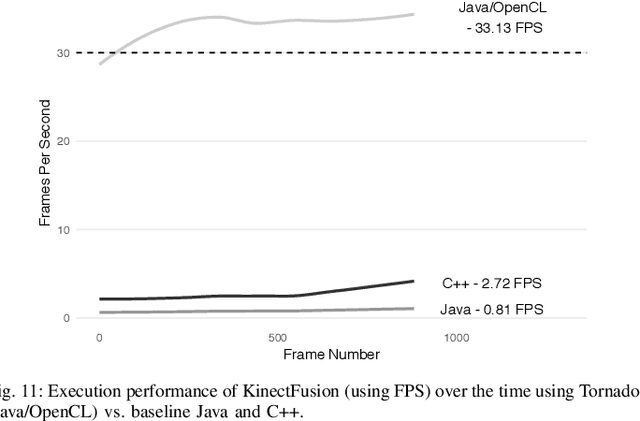
Real-time dense computer vision and SLAM offer great potential for a new level of scene modelling, tracking and real environmental interaction for many types of robot, but their high computational requirements mean that use on mass market embedded platforms is challenging. Meanwhile, trends in low-cost, low-power processing are towards massive parallelism and heterogeneity, making it difficult for robotics and vision researchers to implement their algorithms in a performance-portable way. In this paper we introduce SLAMBench, a publicly-available software framework which represents a starting point for quantitative, comparable and validatable experimental research to investigate trade-offs in performance, accuracy and energy consumption of a dense RGB-D SLAM system. SLAMBench provides a KinectFusion implementation in C++, OpenMP, OpenCL and CUDA, and harnesses the ICL-NUIM dataset of synthetic RGB-D sequences with trajectory and scene ground truth for reliable accuracy comparison of different implementation and algorithms. We present an analysis and breakdown of the constituent algorithmic elements of KinectFusion, and experimentally investigate their execution time on a variety of multicore and GPUaccelerated platforms. For a popular embedded platform, we also present an analysis of energy efficiency for different configuration alternatives.
* 8 pages, ICRA 2015 conference paper