 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMOR: Adaptive Character Control through Multi-Objective Reinforcement Learning
May 29, 2025Reinforcement learning (RL) has significantly advanced the control of physics-based and robotic characters that track kinematic reference motion. However, methods typically rely on a weighted sum of conflicting reward functions, requiring extensive tuning to achieve a desired behavior. Due to the computational cost of RL, this iterative process is a tedious, time-intensive task. Furthermore, for robotics applications, the weights need to be chosen such that the policy performs well in the real world, despite inevitable sim-to-real gaps. To address these challenges, we propose a multi-objective reinforcement learning framework that trains a single policy conditioned on a set of weights, spanning the Pareto front of reward trade-offs. Within this framework, weights can be selected and tuned after training, significantly speeding up iteration time. We demonstrate how this improved workflow can be used to perform highly dynamic motions with a robot character. Moreover, we explore how weight-conditioned policies can be leveraged in hierarchical settings, using a high-level policy to dynamically select weights according to the current task. We show that the multi-objective policy encodes a diverse spectrum of behaviors, facilitating efficient adaptation to novel tasks.
Constructing an Optimal Behavior Basis for the Option Keyboard
May 01, 2025Multi-task reinforcement learning aims to quickly identify solutions for new tasks with minimal or no additional interaction with the environment. Generalized Policy Improvement (GPI) addresses this by combining a set of base policies to produce a new one that is at least as good -- though not necessarily optimal -- as any individual base policy. Optimality can be ensured, particularly in the linear-reward case, via techniques that compute a Convex Coverage Set (CCS). However, these are computationally expensive and do not scale to complex domains. The Option Keyboard (OK) improves upon GPI by producing policies that are at least as good -- and often better. It achieves this through a learned meta-policy that dynamically combines base policies. However, its performance critically depends on the choice of base policies. This raises a key question: is there an optimal set of base policies -- an optimal behavior basis -- that enables zero-shot identification of optimal solutions for any linear tasks? We solve this open problem by introducing a novel method that efficiently constructs such an optimal behavior basis. We show that it significantly reduces the number of base policies needed to ensure optimality in new tasks. We also prove that it is strictly more expressive than a CCS, enabling particular classes of non-linear tasks to be solved optimally. We empirically evaluate our technique in challenging domains and show that it outperforms state-of-the-art approaches, increasingly so as task complexity increases.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
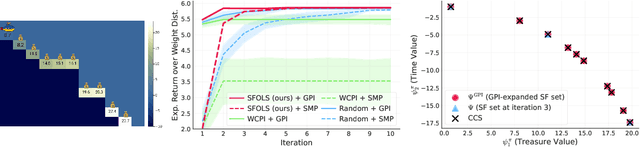
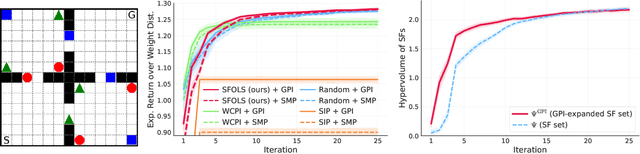
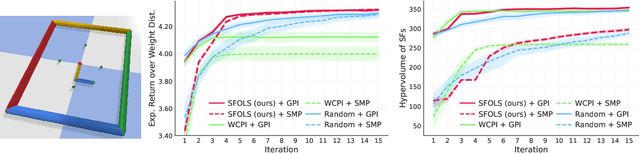
Sample-Efficient Multi-Objective Learning via Generalized Policy Improvement Prioritization
Jan 18, 2023



Multi-objective reinforcement learning (MORL) algorithms tackle sequential decision problems where agents may have different preferences over (possibly conflicting) reward functions. Such algorithms often learn a set of policies (each optimized for a particular agent preference) that can later be used to solve problems with novel preferences. We introduce a novel algorithm that uses Generalized Policy Improvement (GPI) to define principled, formally-derived prioritization schemes that improve sample-efficient learning. They implement active-learning strategies by which the agent can (i) identify the most promising preferences/objectives to train on at each moment, to more rapidly solve a given MORL problem; and (ii) identify which previous experiences are most relevant when learning a policy for a particular agent preference, via a novel Dyna-style MORL method. We prove our algorithm is guaranteed to always converge to an optimal solution in a finite number of steps, or an $\epsilon$-optimal solution (for a bounded $\epsilon$) if the agent is limited and can only identify possibly sub-optimal policies. We also prove that our method monotonically improves the quality of its partial solutions while learning. Finally, we introduce a bound that characterizes the maximum utility loss (with respect to the optimal solution) incurred by the partial solutions computed by our method throughout learning. We empirically show that our method outperforms state-of-the-art MORL algorithms in challenging multi-objective tasks, both with discrete and continuous state spaces.
Optimistic Linear Support and Successor Features as a Basis for Optimal Policy Transfer
Jun 22, 2022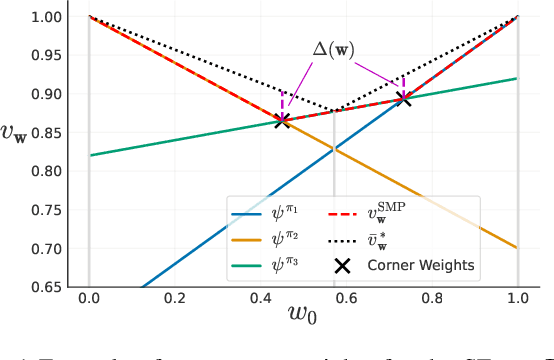
In many real-world applications, reinforcement learning (RL) agents might have to solve multiple tasks, each one typically modeled via a reward function. If reward functions are expressed linearly, and the agent has previously learned a set of policies for different tasks, successor features (SFs) can be exploited to combine such policies and identify reasonable solutions for new problems. However, the identified solutions are not guaranteed to be optimal. We introduce a novel algorithm that addresses this limitation. It allows RL agents to combine existing policies and directly identify optimal policies for arbitrary new problems, without requiring any further interactions with the environment. We first show (under mild assumptions) that the transfer learning problem tackled by SFs is equivalent to the problem of learning to optimize multiple objectives in RL. We then introduce an SF-based extension of the Optimistic Linear Support algorithm to learn a set of policies whose SFs form a convex coverage set. We prove that policies in this set can be combined via generalized policy improvement to construct optimal behaviors for any new linearly-expressible tasks, without requiring any additional training samples. We empirically show that our method outperforms state-of-the-art competing algorithms both in discrete and continuous domains under value function approximation.
Minimum-Delay Adaptation in Non-Stationary Reinforcement Learning via Online High-Confidence Change-Point Detection
May 20, 2021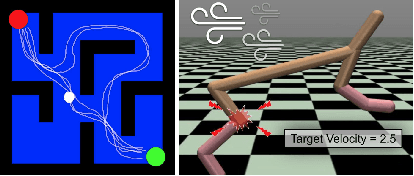
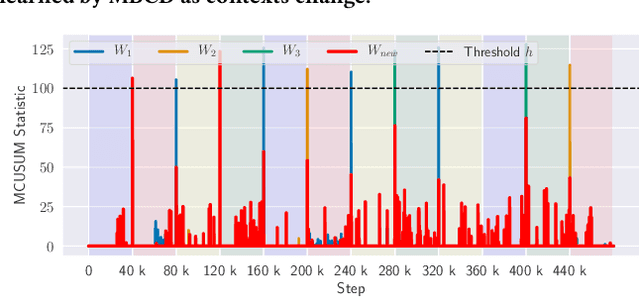
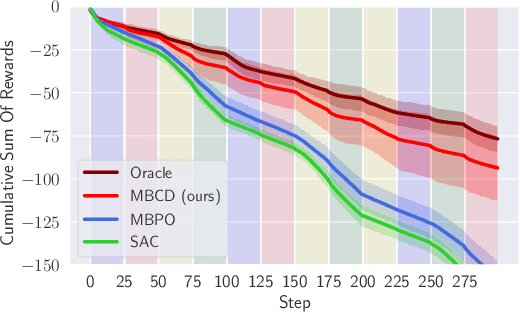
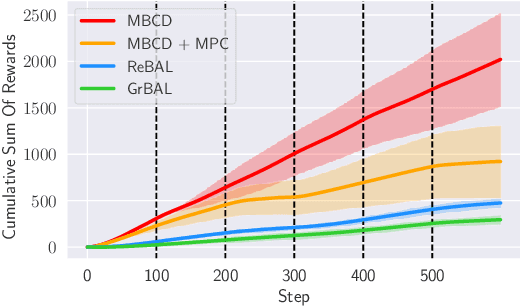
Non-stationary environments are challenging for reinforcement learning algorithms. If the state transition and/or reward functions change based on latent factors, the agent is effectively tasked with optimizing a behavior that maximizes performance over a possibly infinite random sequence of Markov Decision Processes (MDPs), each of which drawn from some unknown distribution. We call each such MDP a context. Most related works make strong assumptions such as knowledge about the distribution over contexts, the existence of pre-training phases, or a priori knowledge about the number, sequence, or boundaries between contexts. We introduce an algorithm that efficiently learns policies in non-stationary environments. It analyzes a possibly infinite stream of data and computes, in real-time, high-confidence change-point detection statistics that reflect whether novel, specialized policies need to be created and deployed to tackle novel contexts, or whether previously-optimized ones might be reused. We show that (i) this algorithm minimizes the delay until unforeseen changes to a context are detected, thereby allowing for rapid responses; and (ii) it bounds the rate of false alarm, which is important in order to minimize regret. Our method constructs a mixture model composed of a (possibly infinite) ensemble of probabilistic dynamics predictors that model the different modes of the distribution over underlying latent MDPs. We evaluate our algorithm on high-dimensional continuous reinforcement learning problems and show that it outperforms state-of-the-art (model-free and model-based) RL algorithms, as well as state-of-the-art meta-learning methods specially designed to deal with non-stationarity.
* Published at Proc. of the 20th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021)
Quantifying the Impact of Non-Stationarity in Reinforcement Learning-Based Traffic Signal Control
Apr 09, 2020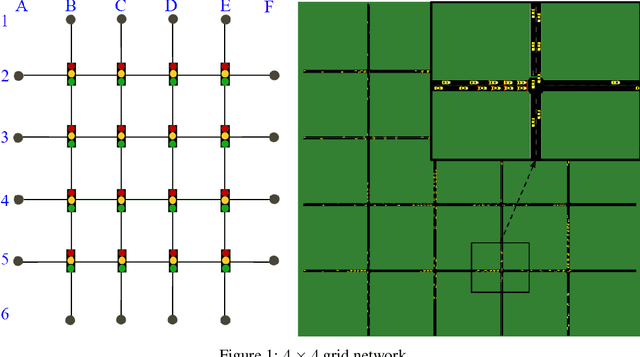
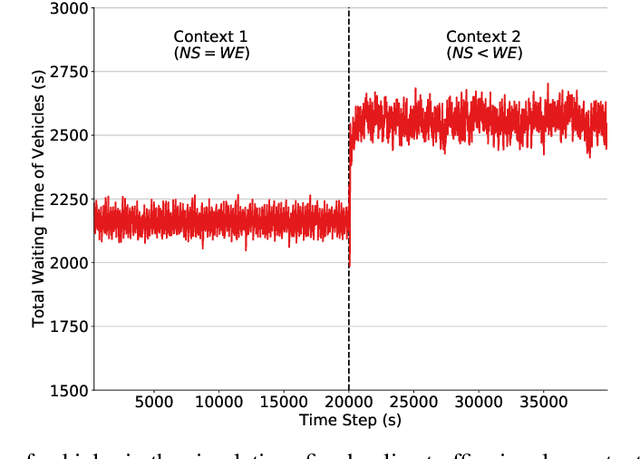
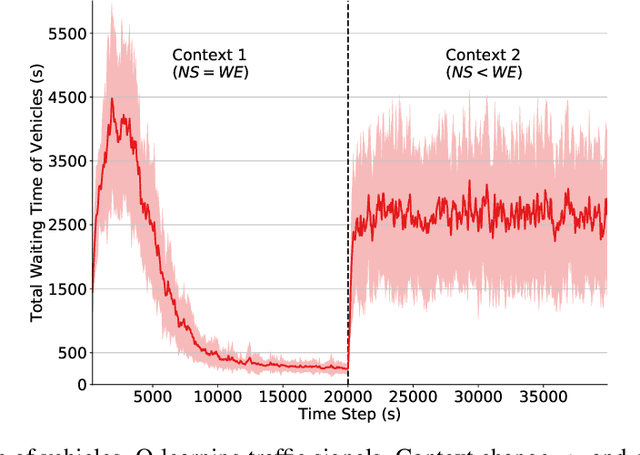
In reinforcement learning (RL), dealing with non-stationarity is a challenging issue. However, some domains such as traffic optimization are inherently non-stationary. Causes for and effects of this are manifold. In particular, when dealing with traffic signal controls, addressing non-stationarity is key since traffic conditions change over time and as a function of traffic control decisions taken in other parts of a network. In this paper we analyze the effects that different sources of non-stationarity have in a network of traffic signals, in which each signal is modeled as a learning agent. More precisely, we study both the effects of changing the \textit{context} in which an agent learns (e.g., a change in flow rates experienced by it), as well as the effects of reducing agent observability of the true environment state. Partial observability may cause distinct states (in which distinct actions are optimal) to be seen as the same by the traffic signal agents. This, in turn, may lead to sub-optimal performance. We show that the lack of suitable sensors to provide a representative observation of the real state seems to affect the performance more drastically than the changes to the underlying traffic patterns.