 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
The Data Provenance Initiative: A Large Scale Audit of Dataset Licensing & Attribution in AI
Nov 04, 2023



The race to train language models on vast, diverse, and inconsistently documented datasets has raised pressing concerns about the legal and ethical risks for practitioners. To remedy these practices threatening data transparency and understanding, we convene a multi-disciplinary effort between legal and machine learning experts to systematically audit and trace 1800+ text datasets. We develop tools and standards to trace the lineage of these datasets, from their source, creators, series of license conditions, properties, and subsequent use. Our landscape analysis highlights the sharp divides in composition and focus of commercially open vs closed datasets, with closed datasets monopolizing important categories: lower resource languages, more creative tasks, richer topic variety, newer and more synthetic training data. This points to a deepening divide in the types of data that are made available under different license conditions, and heightened implications for jurisdictional legal interpretations of copyright and fair use. We also observe frequent miscategorization of licenses on widely used dataset hosting sites, with license omission of 70%+ and error rates of 50%+. This points to a crisis in misattribution and informed use of the most popular datasets driving many recent breakthroughs. As a contribution to ongoing improvements in dataset transparency and responsible use, we release our entire audit, with an interactive UI, the Data Provenance Explorer, which allows practitioners to trace and filter on data provenance for the most popular open source finetuning data collections: www.dataprovenance.org.
Speech Wikimedia: A 77 Language Multilingual Speech Dataset
Aug 30, 2023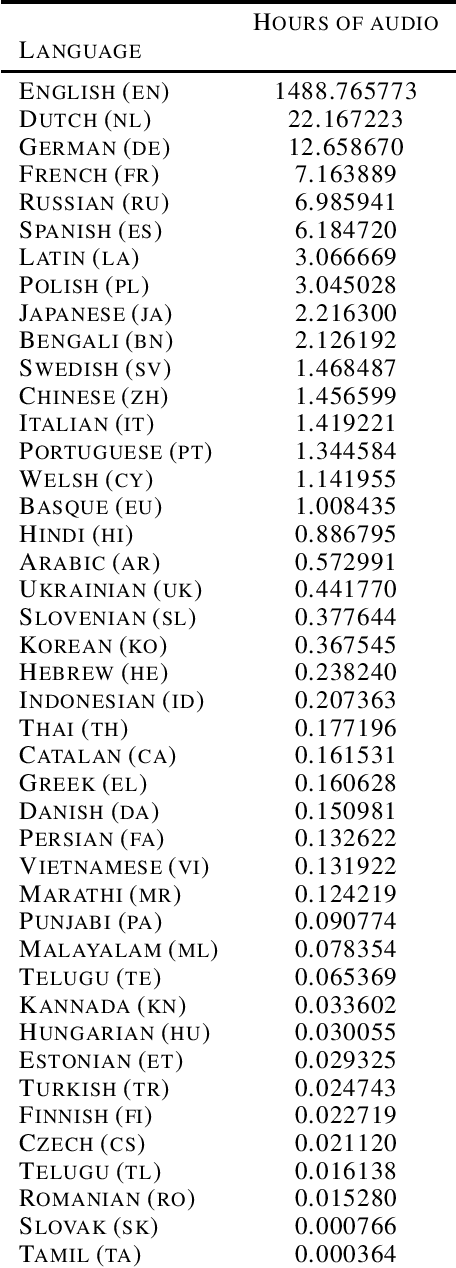
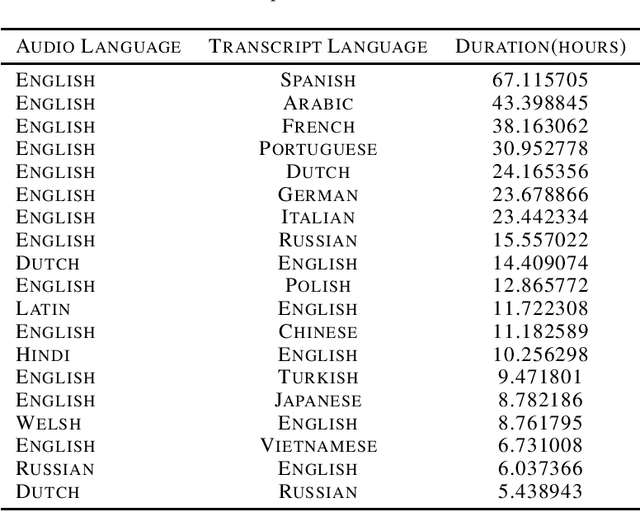
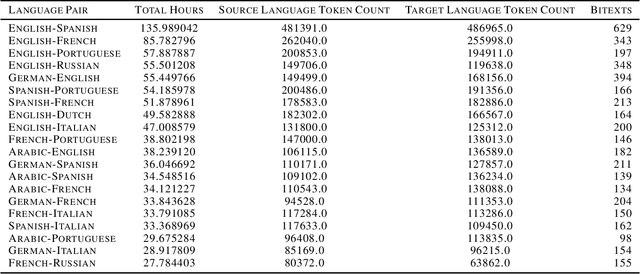

The Speech Wikimedia Dataset is a publicly available compilation of audio with transcriptions extracted from Wikimedia Commons. It includes 1780 hours (195 GB) of CC-BY-SA licensed transcribed speech from a diverse set of scenarios and speakers, in 77 different languages. Each audio file has one or more transcriptions in different languages, making this dataset suitable for training speech recognition, speech translation, and machine translation models.