Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Wikimedia: A 77 Language Multilingual Speech Dataset
Paper and Code
Aug 30, 2023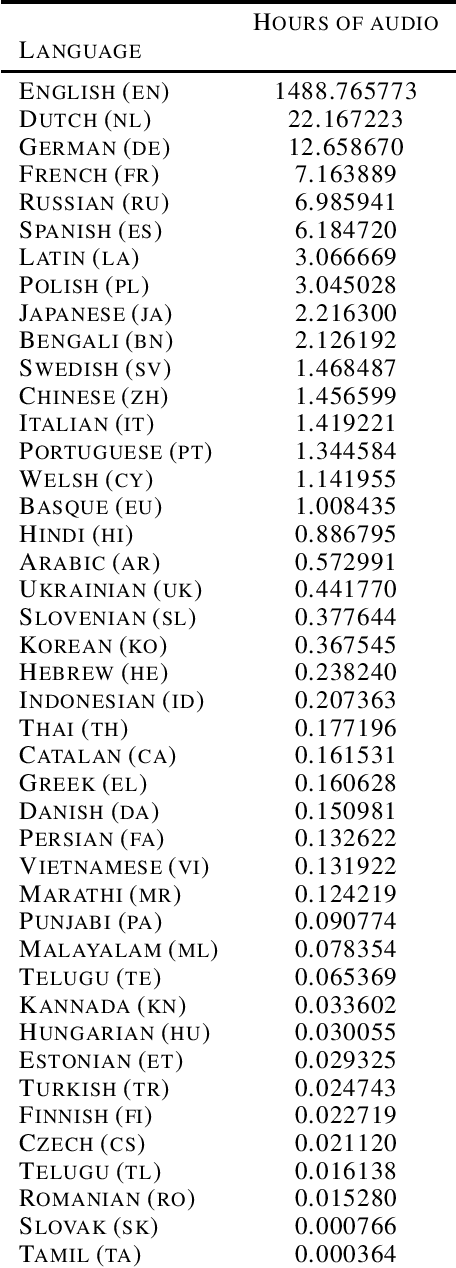
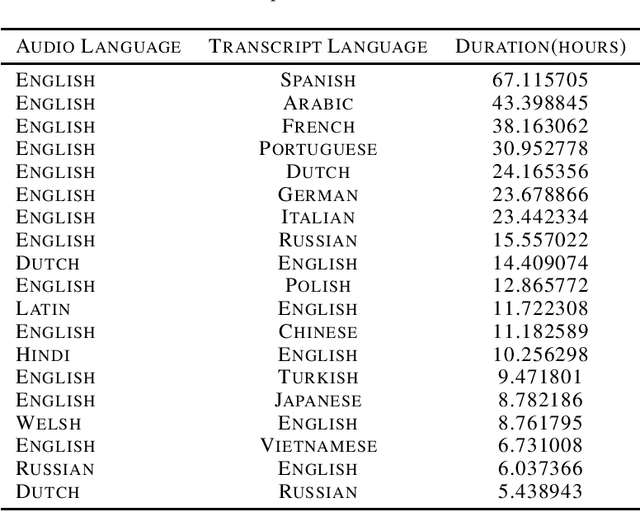
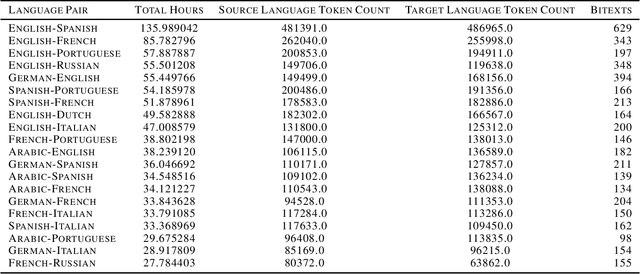

The Speech Wikimedia Dataset is a publicly available compilation of audio with transcriptions extracted from Wikimedia Commons. It includes 1780 hours (195 GB) of CC-BY-SA licensed transcribed speech from a diverse set of scenarios and speakers, in 77 different languages. Each audio file has one or more transcriptions in different languages, making this dataset suitable for training speech recognition, speech translation, and machine translation models.
* Data-Centric Machine Learning Workshop at the International Machine
Learning Conference 2023 (ICML)
View paper on